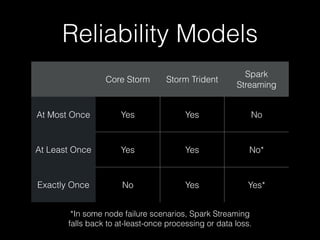
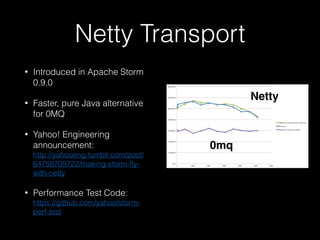
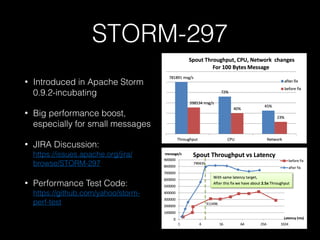
The document compares Apache Storm and Spark Streaming, highlighting inaccuracies in existing benchmarks and the need for independently verifiable claims. It discusses the differences in processing models, reliability features, and performance characteristics of both frameworks, while emphasizing the importance of data source reliability. The author critiques various studies, noting that many comparisons are incomplete, particularly regarding Storm's Trident API, and advises users to consider their specific use cases when choosing between the two.






































































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)














