Download as PDF, PPTX





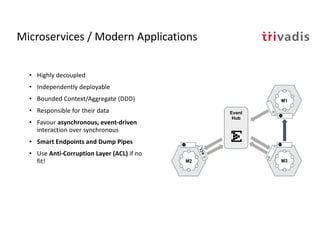
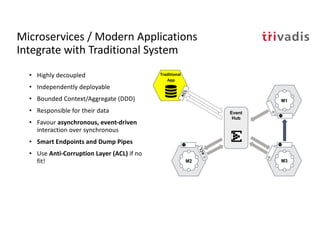
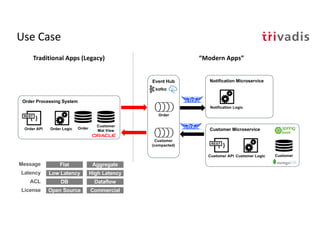
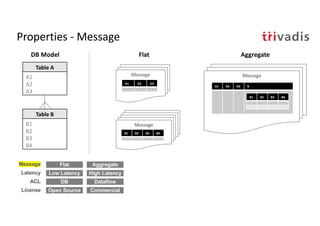
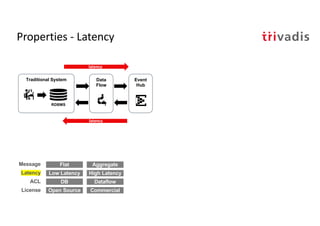
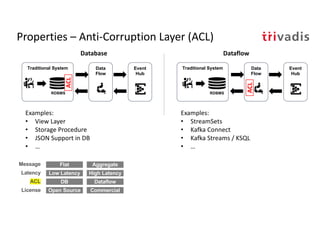

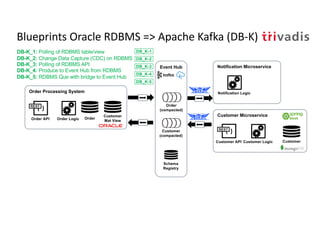
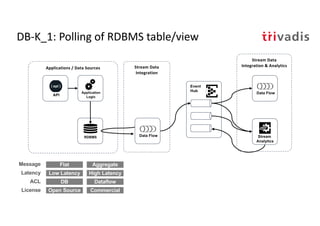
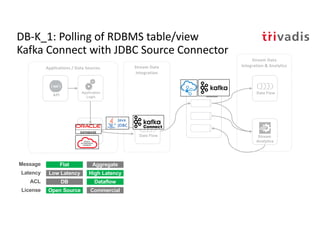
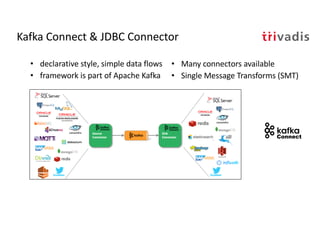
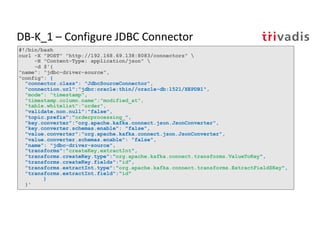
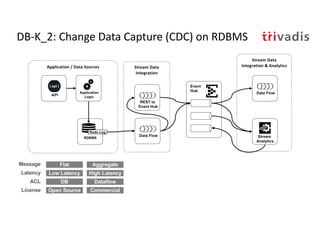
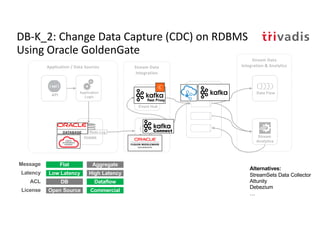
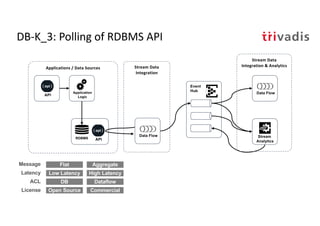
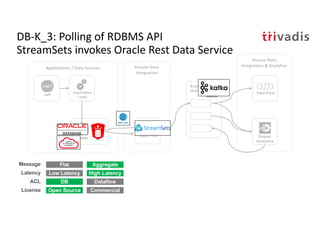
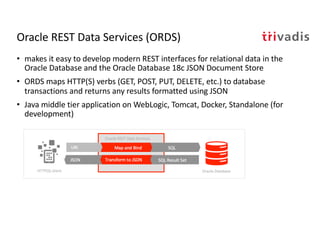

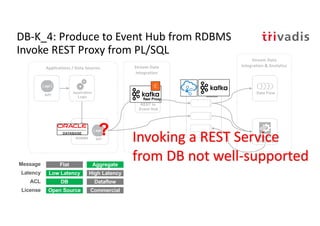
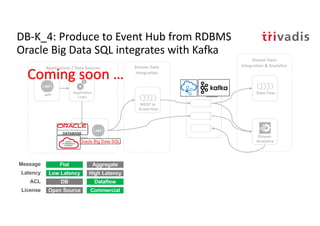
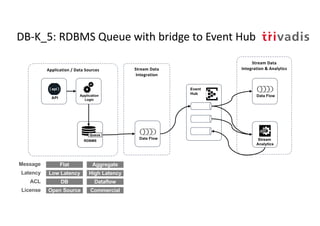
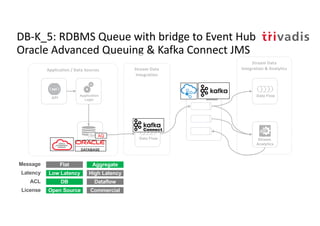

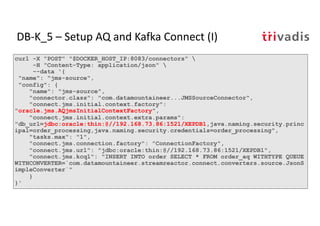
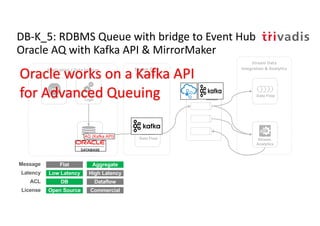

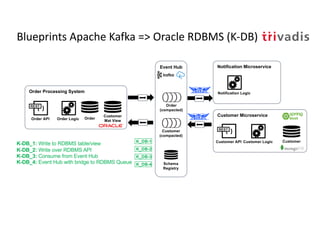
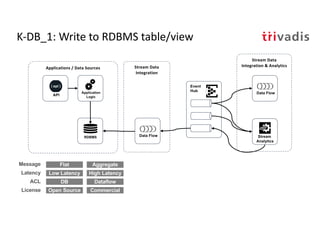
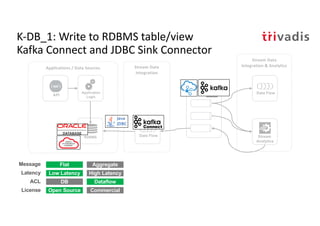
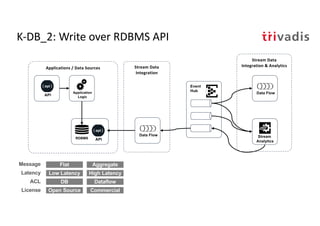
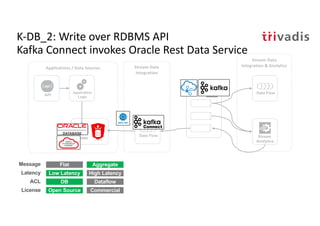
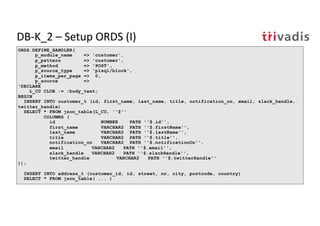
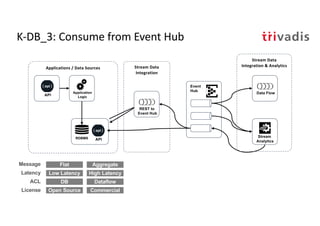
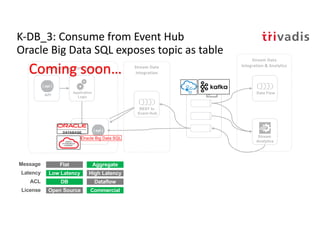
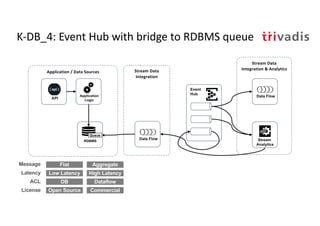
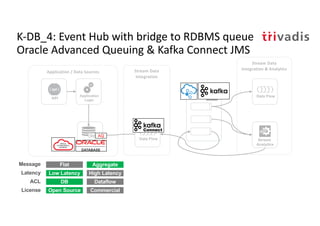
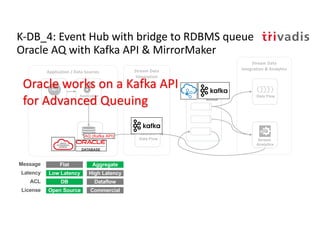

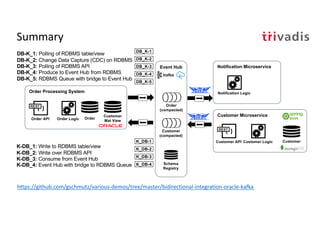
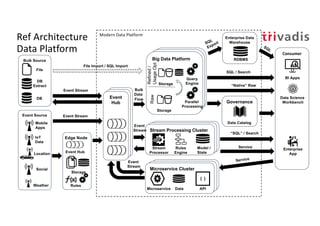
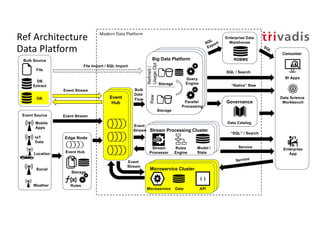


The document discusses bi-directional integration solutions between Oracle RDBMS and Apache Kafka, outlining key agendas such as blueprints for both Oracle to Kafka and Kafka to Oracle data flows. It provides detailed explanations of various integration methods including polling, change data capture, and use of APIs. Furthermore, it highlights the role of microservices in modern applications and the importance of asynchronous communication in data processing.














































































