Downloaded 1,062 times







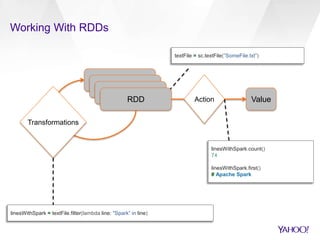

![Spark Streaming Word Count
updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
…
lines = ssc.socketTextStream(args(0), args(1).toInt)
Words = lines.flatMap(lambda line: line.split(“ ”))
wordDstream = words.map(lambda word => (word, 1))
stateDstream = wordDstream.updateStateByKey[Int](updateFunc)
ssc.start()
ssc.awaitTermination()](https://image.slidesharecdn.com/stormsparkchug-140918140317-phpapp01/85/Yahoo-compares-Storm-and-Spark-9-320.jpg)

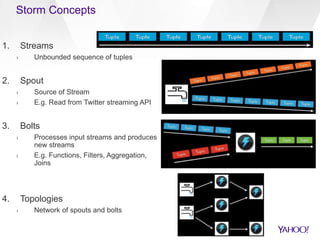
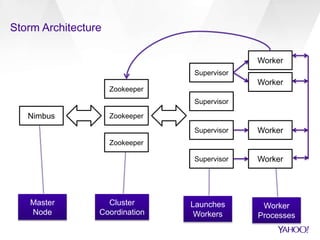






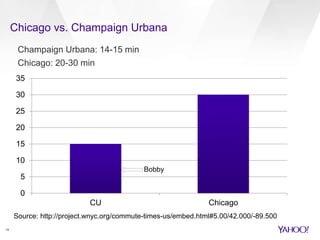

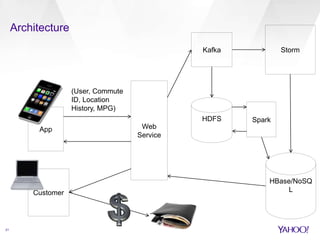
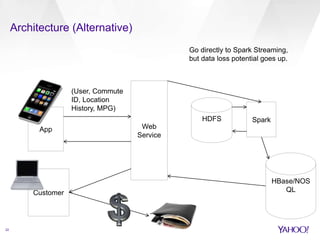
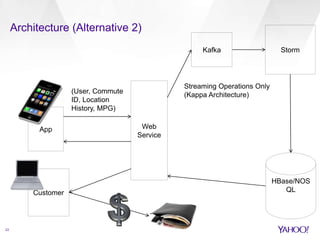


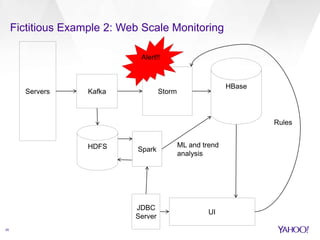


The document compares Apache Spark and Apache Storm, highlighting their use cases and architectures within Yahoo's big data ecosystem. It emphasizes Spark's strength in iterative batch processing and machine learning, while Storm excels in low-latency, real-time processing. The authors provide recommendations on when to choose each technology based on factors like scale, latency, and processing needs.












![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































