Download as PDF, PPTX






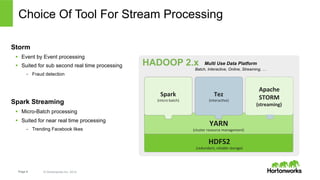

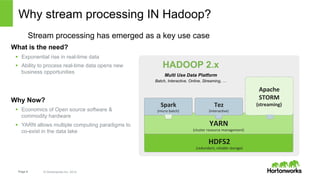
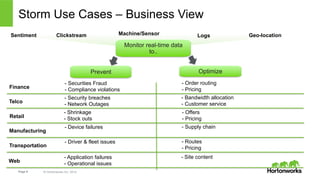

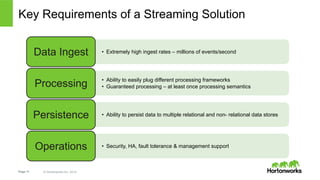
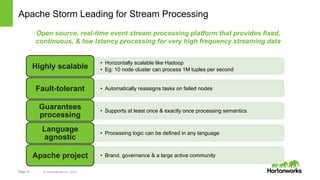
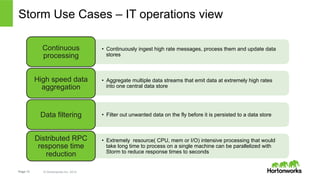


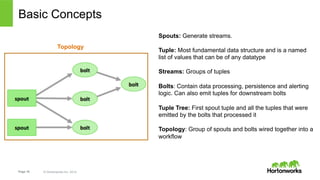
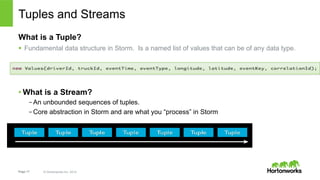
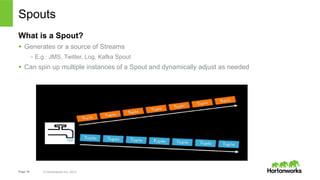


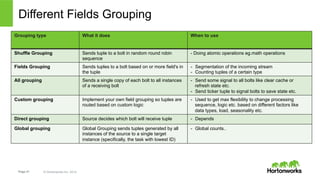

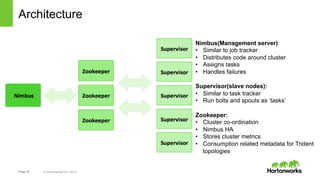

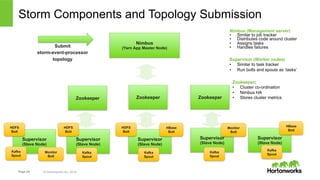
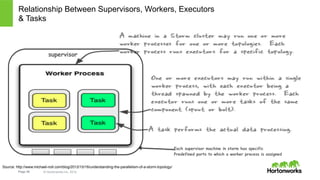


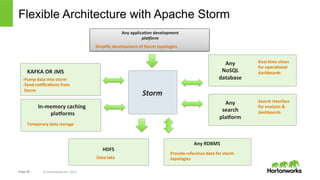
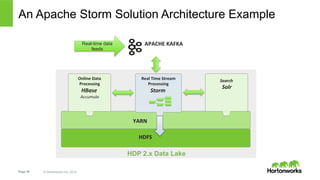
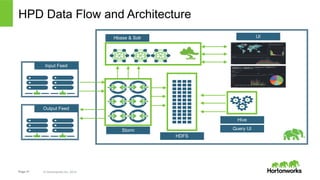
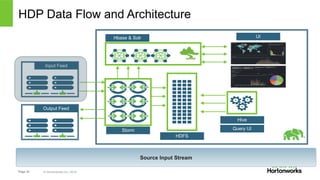
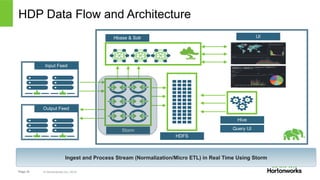
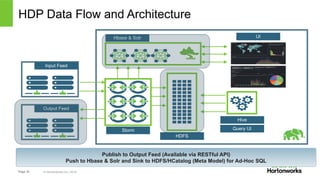
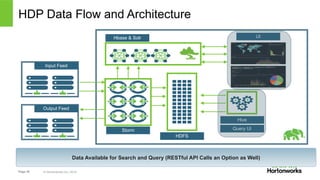


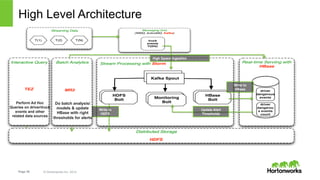
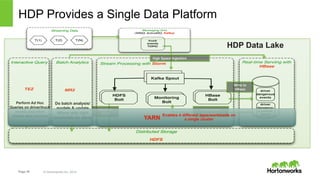
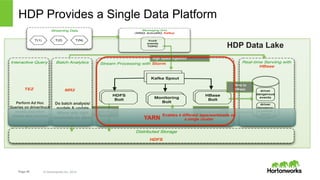


The document discusses real-time processing with Hadoop, focusing on Hortonworks and Apache Storm. It outlines the architecture and key constructs of Apache Storm, including its ability to handle high-volume streaming data, processing guarantees, and various use cases in business and IT operations. The document emphasizes the importance of stream processing in managing real-time data and improving operational efficiency.















![Discover.hdp2.2.h base.final[2]](https://cdn.slidesharecdn.com/ss_thumbnails/discover-141218155001-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



























































































