Downloaded 30 times







![Fault Tolerance: Delivery Guarantees
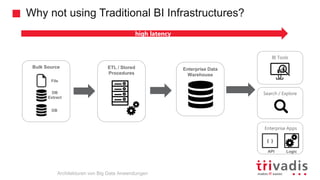
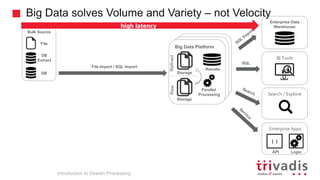
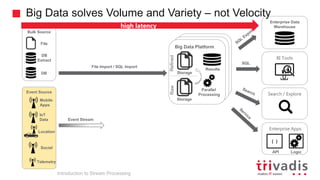
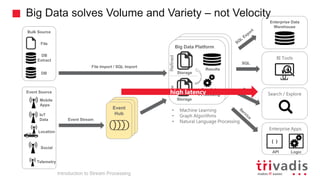
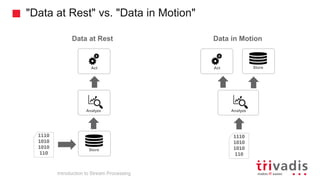
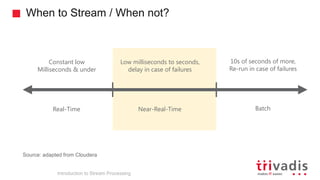
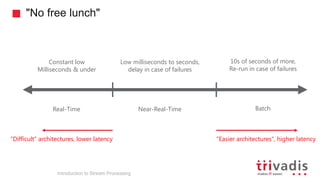
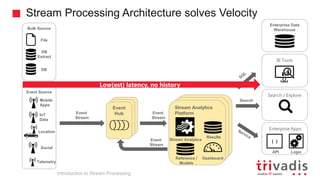
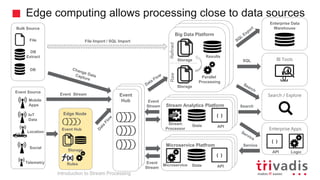
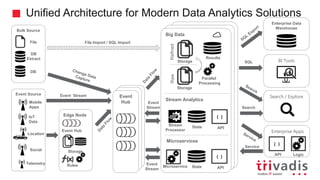
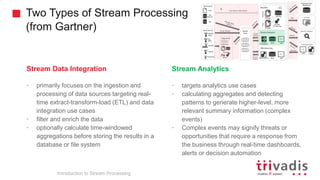
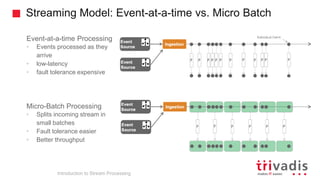
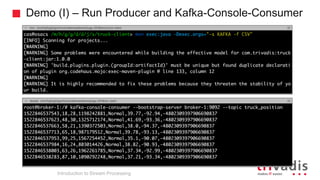
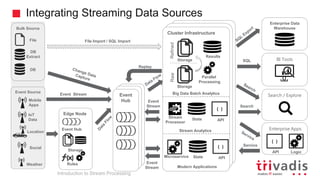
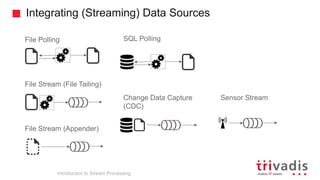
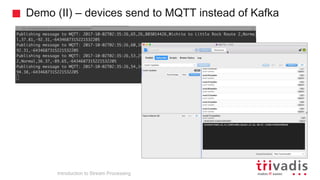
Introduction to Stream Processing
• At most once (fire-and-forget) - means the message is sent, but the sender
doesn’t care if it’s received or lost. Imposes no additional overhead to ensure
message delivery, such as requiring acknowledgments from consumers. Hence, it
is the easiest and most performant behavior to support.
• At least once - means that retransmission of a message will occur until an
acknowledgment is received. Since a delayed acknowledgment from the receiver
could be in flight when the sender retransmits the message, the message may be
received one or more times.
• Exactly once - ensures that a message is received once and only once, and is
never lost and never repeated. The system must implement whatever
mechanisms are required to ensure that a message is received and processed
just once
[ 0 | 1 ]
[ 1+ ]
[ 1 ]](https://image.slidesharecdn.com/introduction-to-stream-processing-v1-180913135428/85/Introduction-to-Stream-Processing-23-320.jpg)

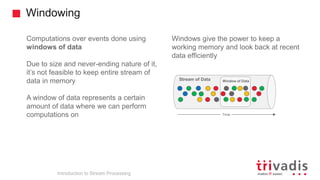
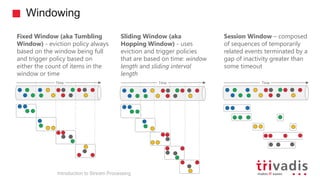
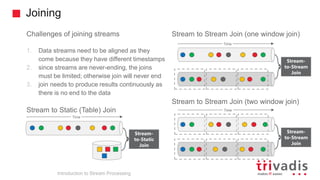


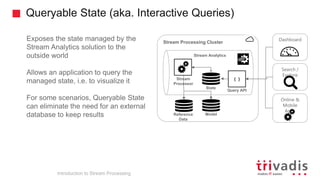

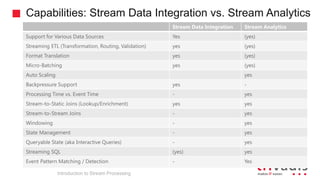

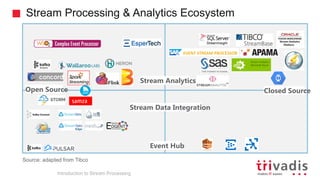

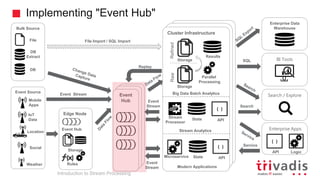
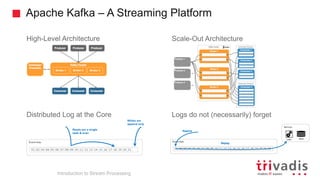







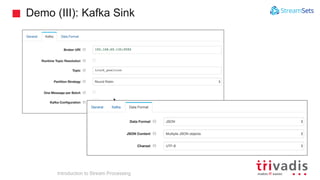
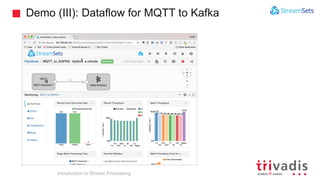
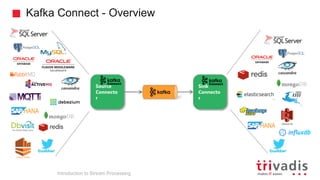
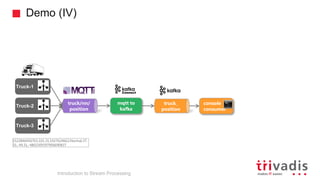



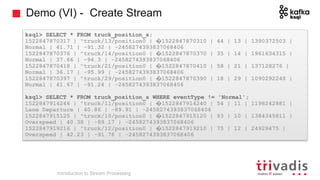
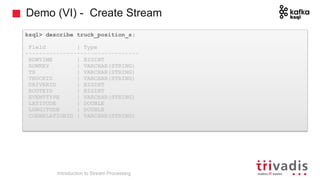
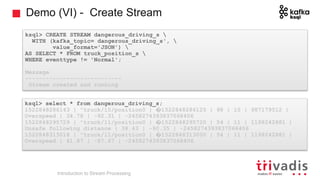
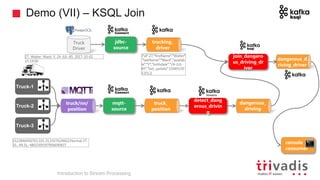
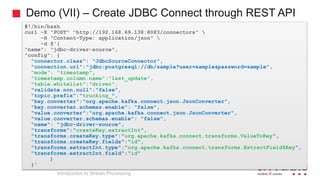
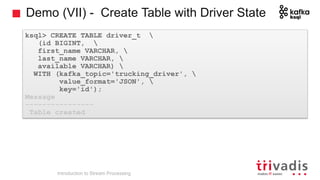
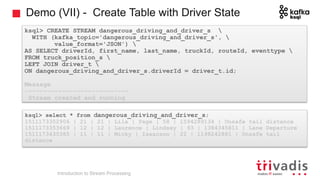

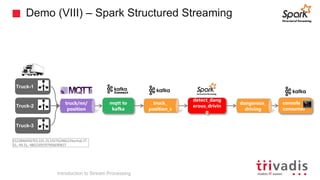






The document is an introduction to stream processing, highlighting its motivation, capabilities, and implementation strategies. It discusses the differences between traditional data processing and stream processing, covering use cases, architecture, data integration, and key concepts like event streams and state management. Additionally, it examines tools like Apache Kafka and techniques for managing data flow in real-time applications.



































![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)




![[WSO2Con USA 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/wso2conusa2018theriseofstreamingsql-180717041454-thumbnail.jpg?width=640&height=640&fit=bounds)


![[WSO2Con EU 2018] Streaming SQL in the Real World](https://cdn.slidesharecdn.com/ss_thumbnails/wso2coneu2018streamingsqlintherealworld-181113090808-thumbnail.jpg?width=640&height=640&fit=bounds)











































