Downloaded 26 times

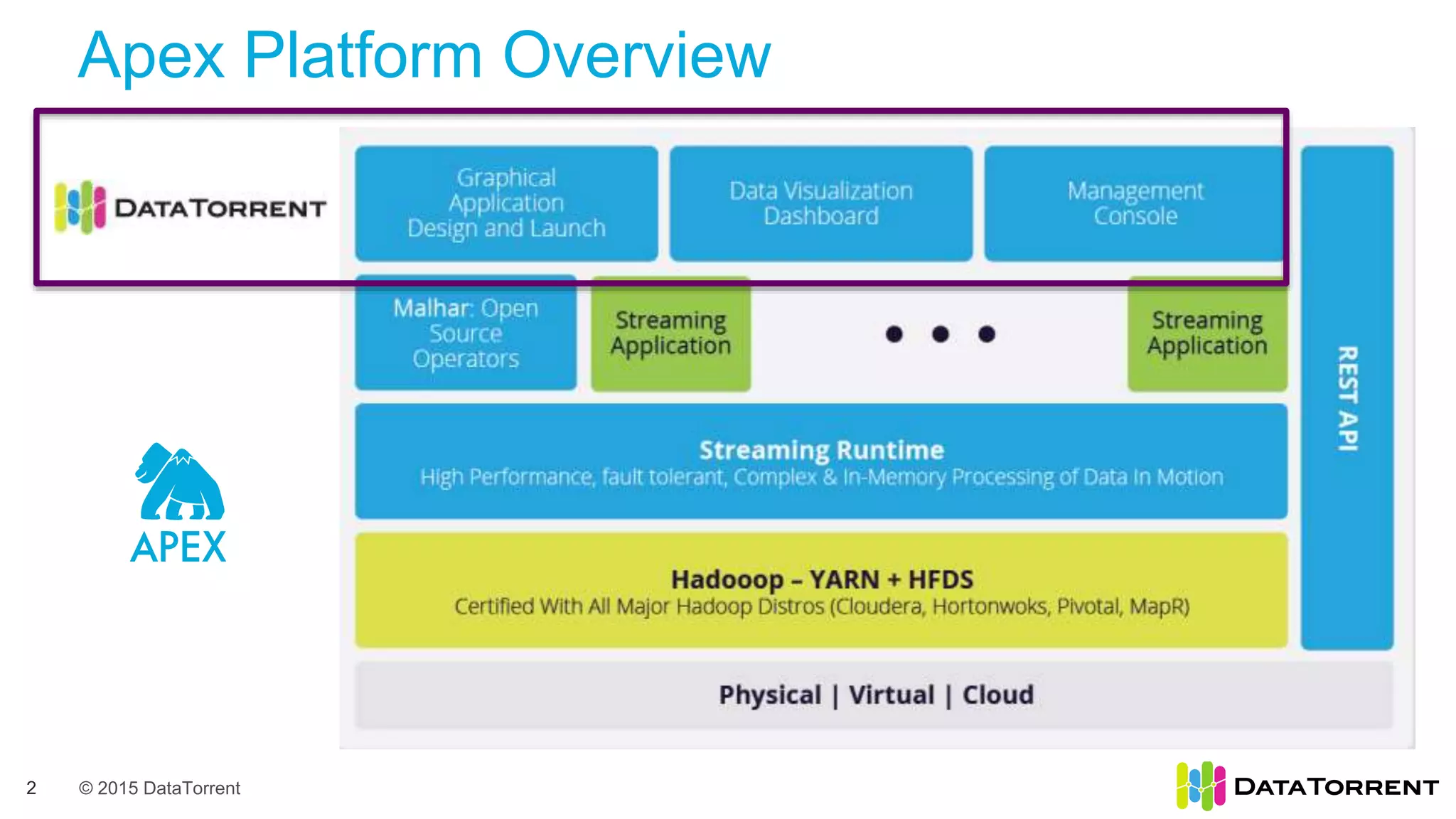

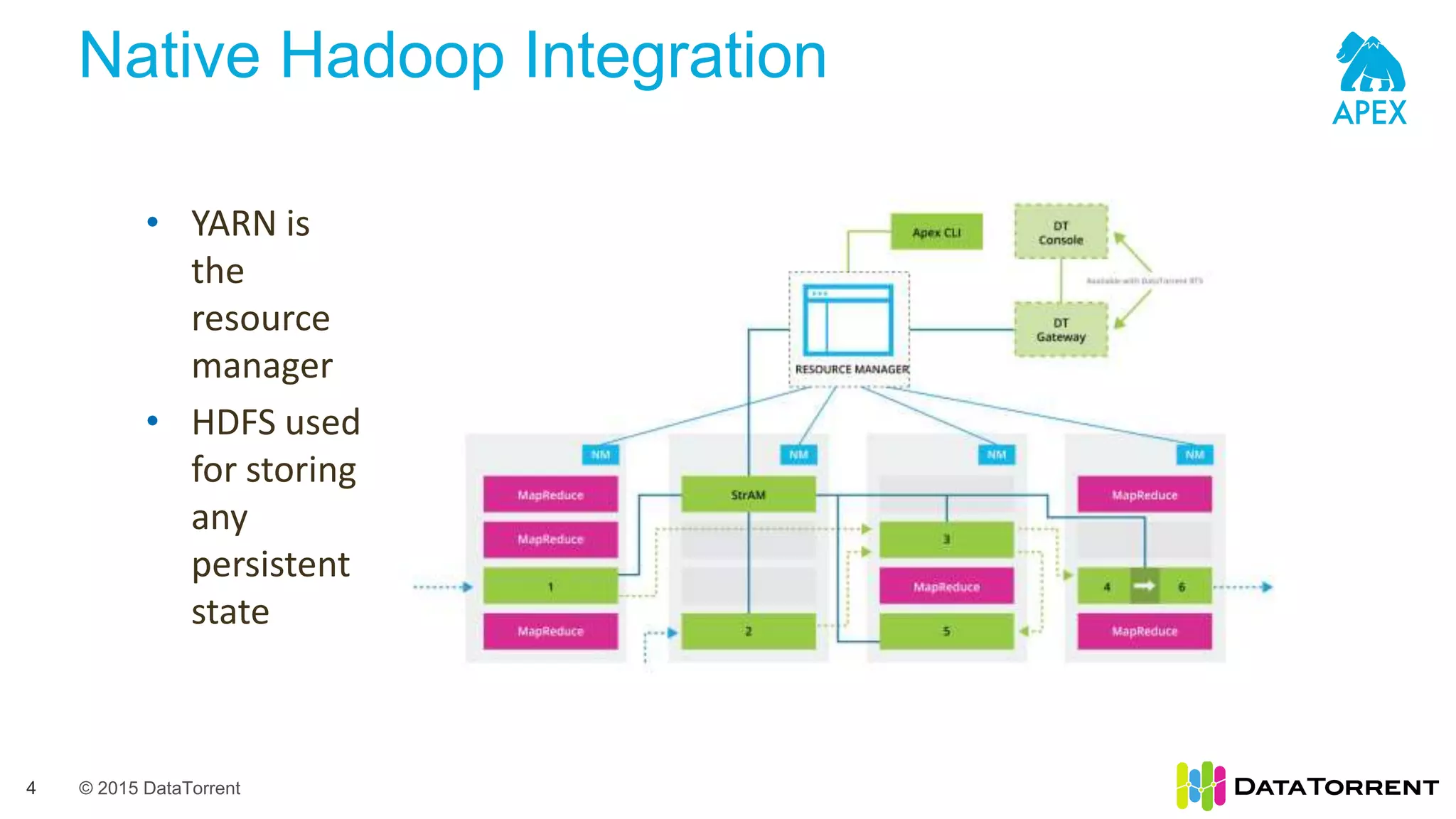
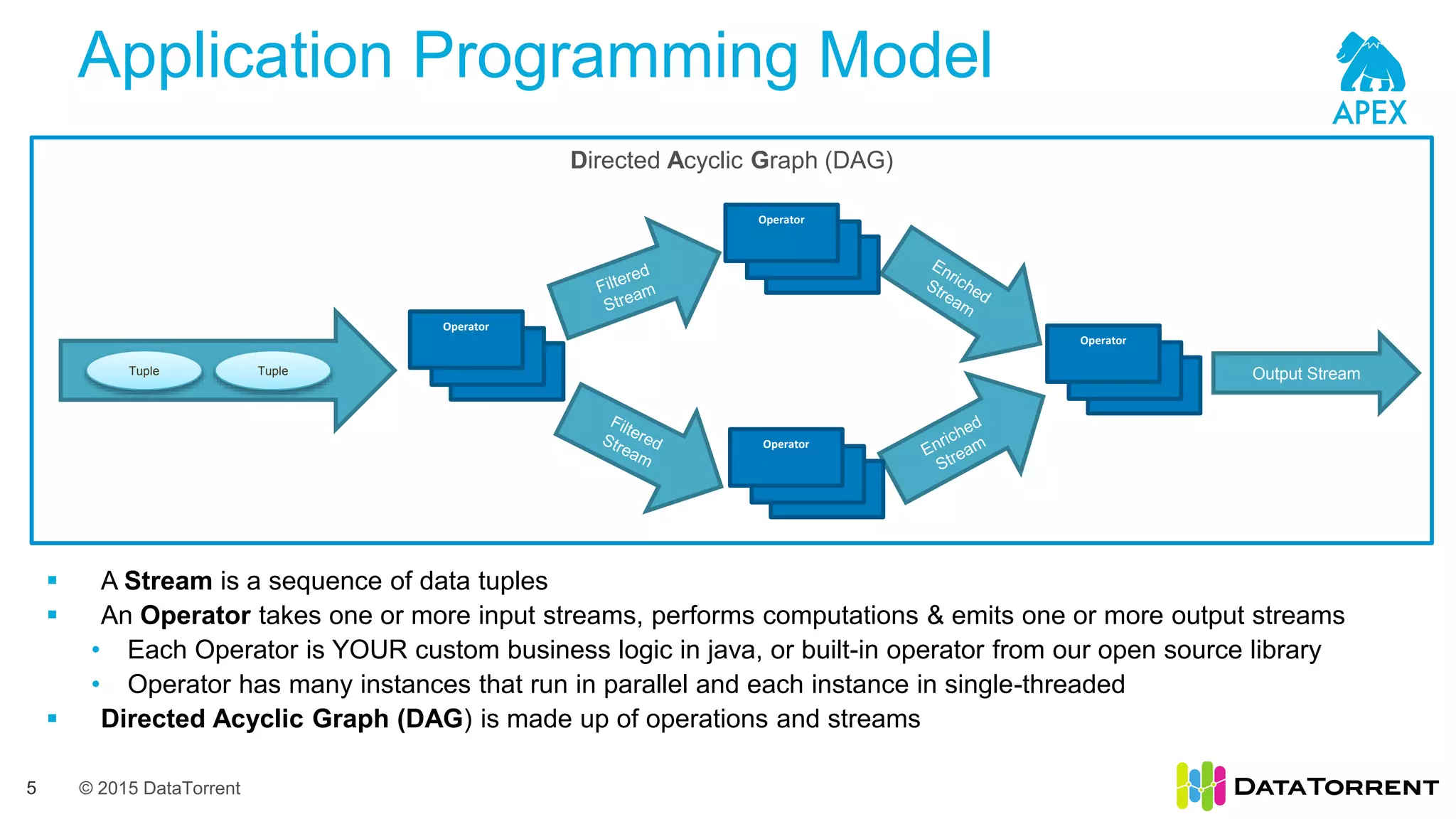
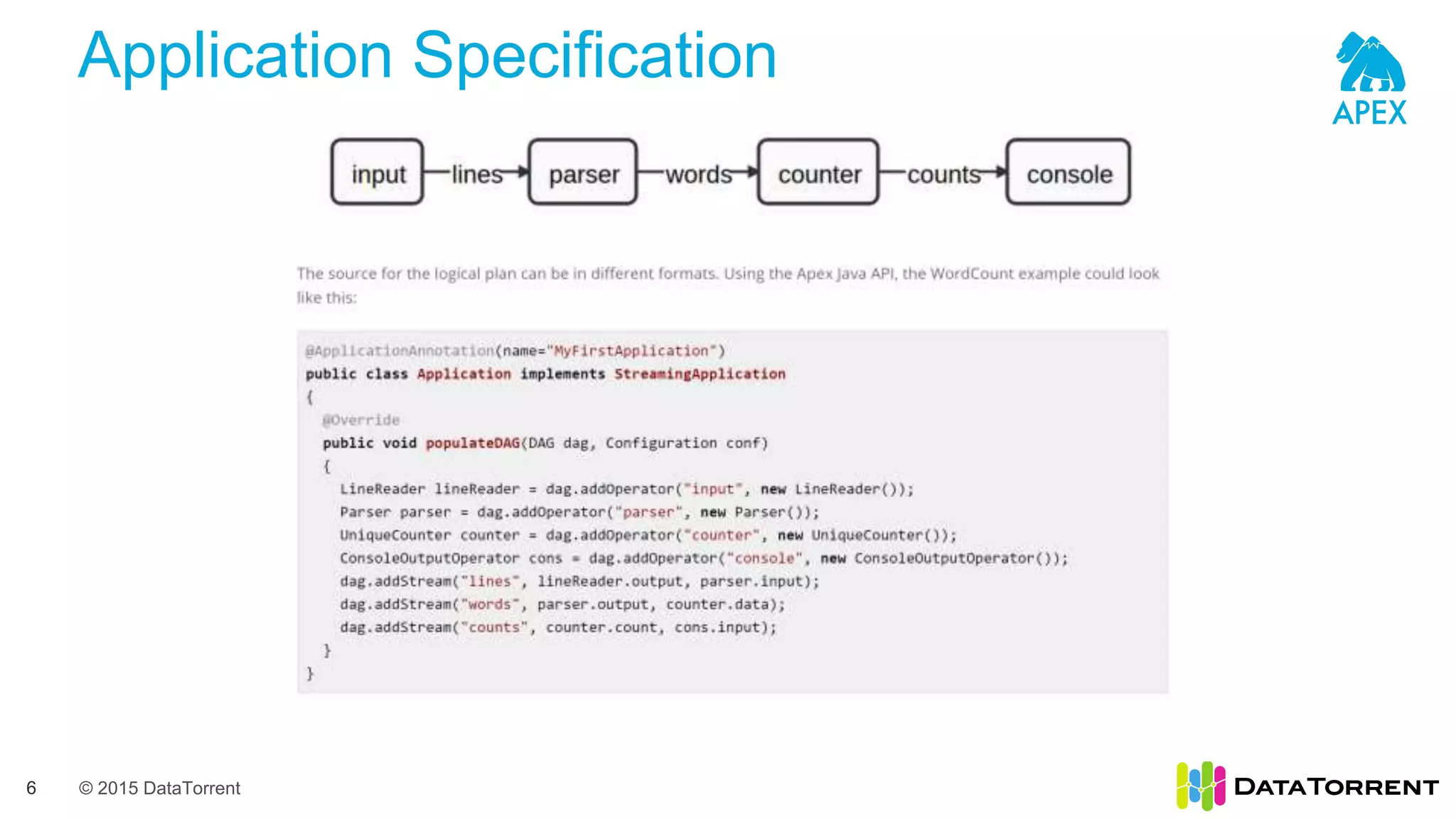
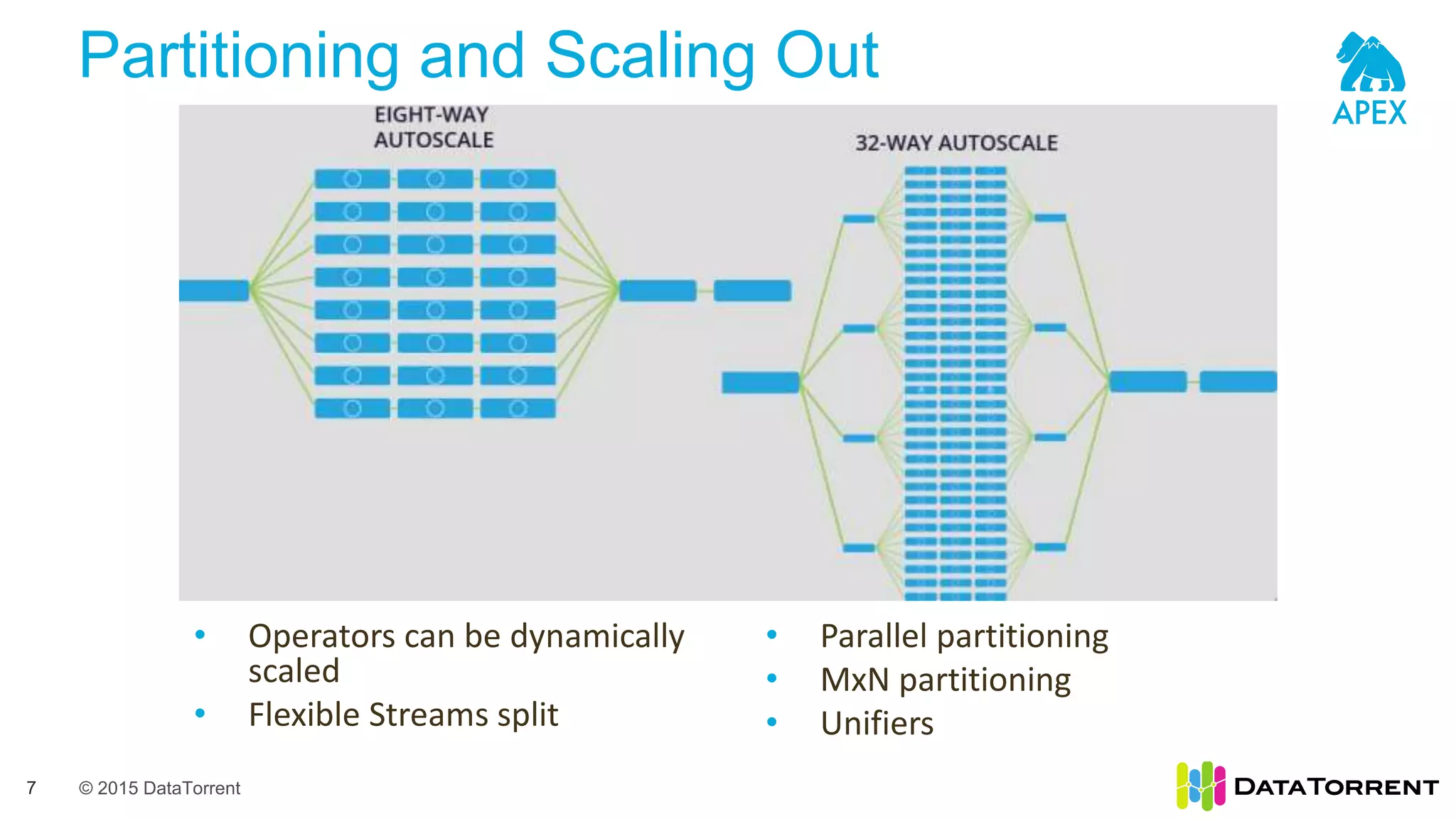
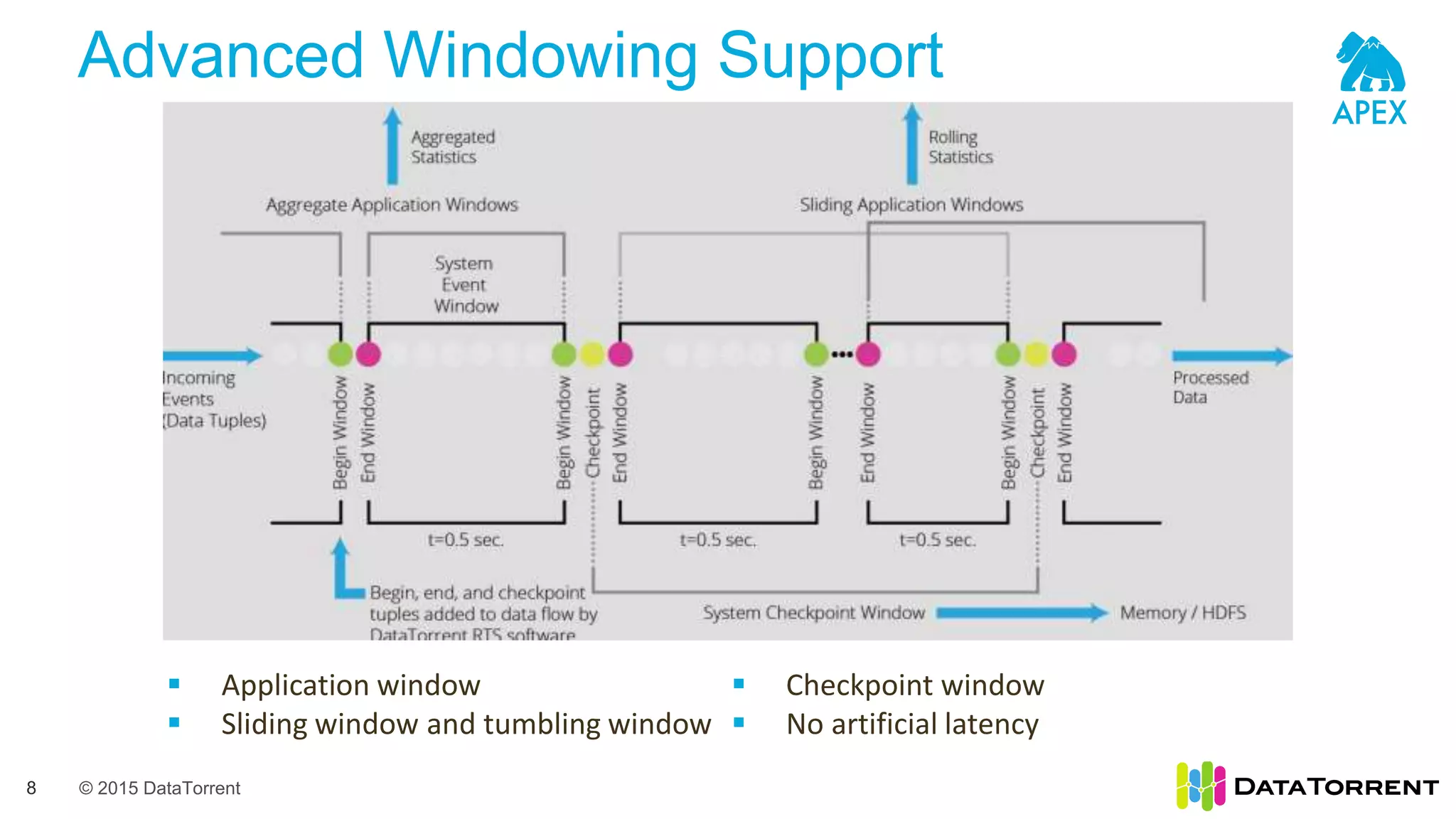
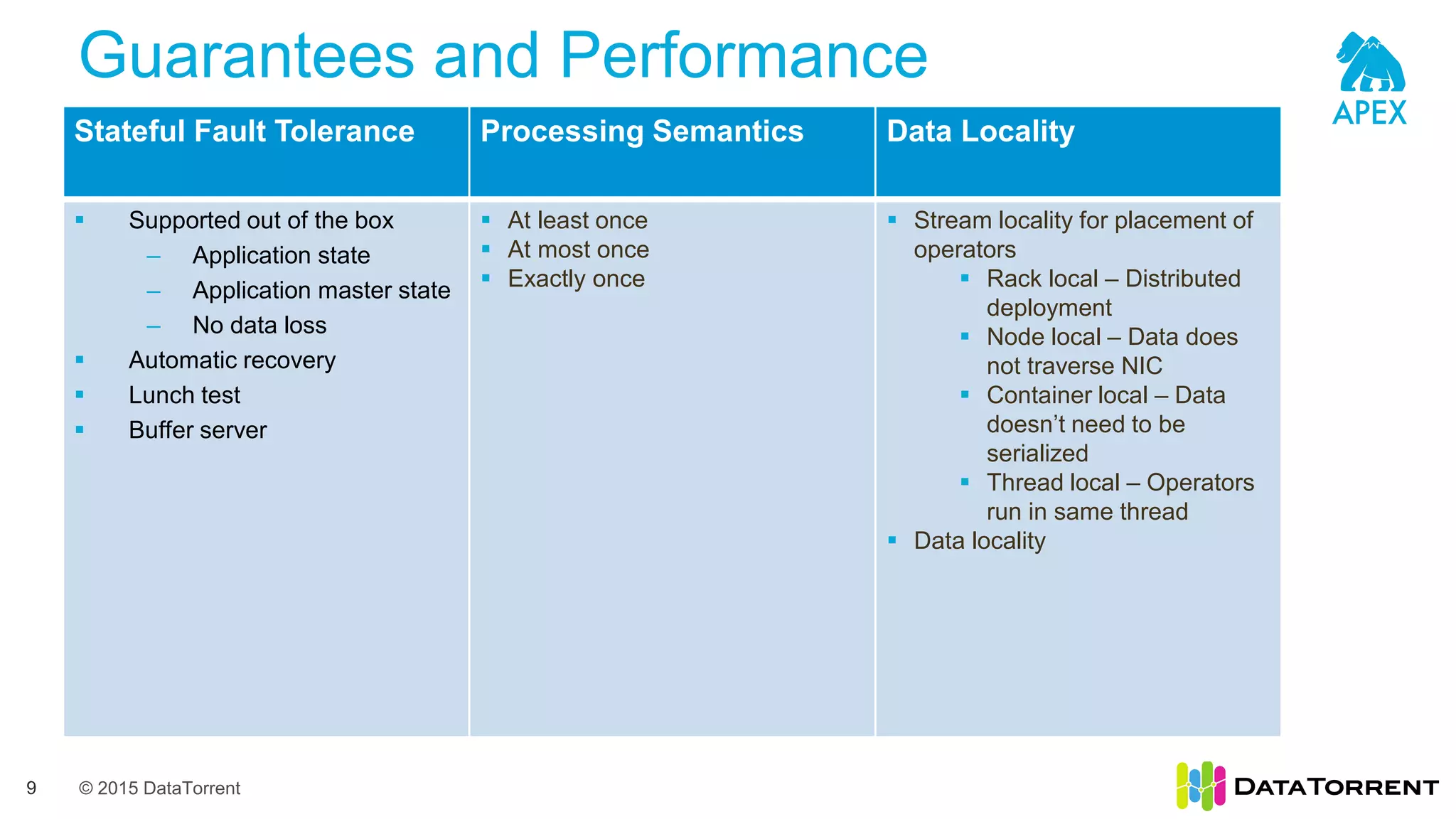

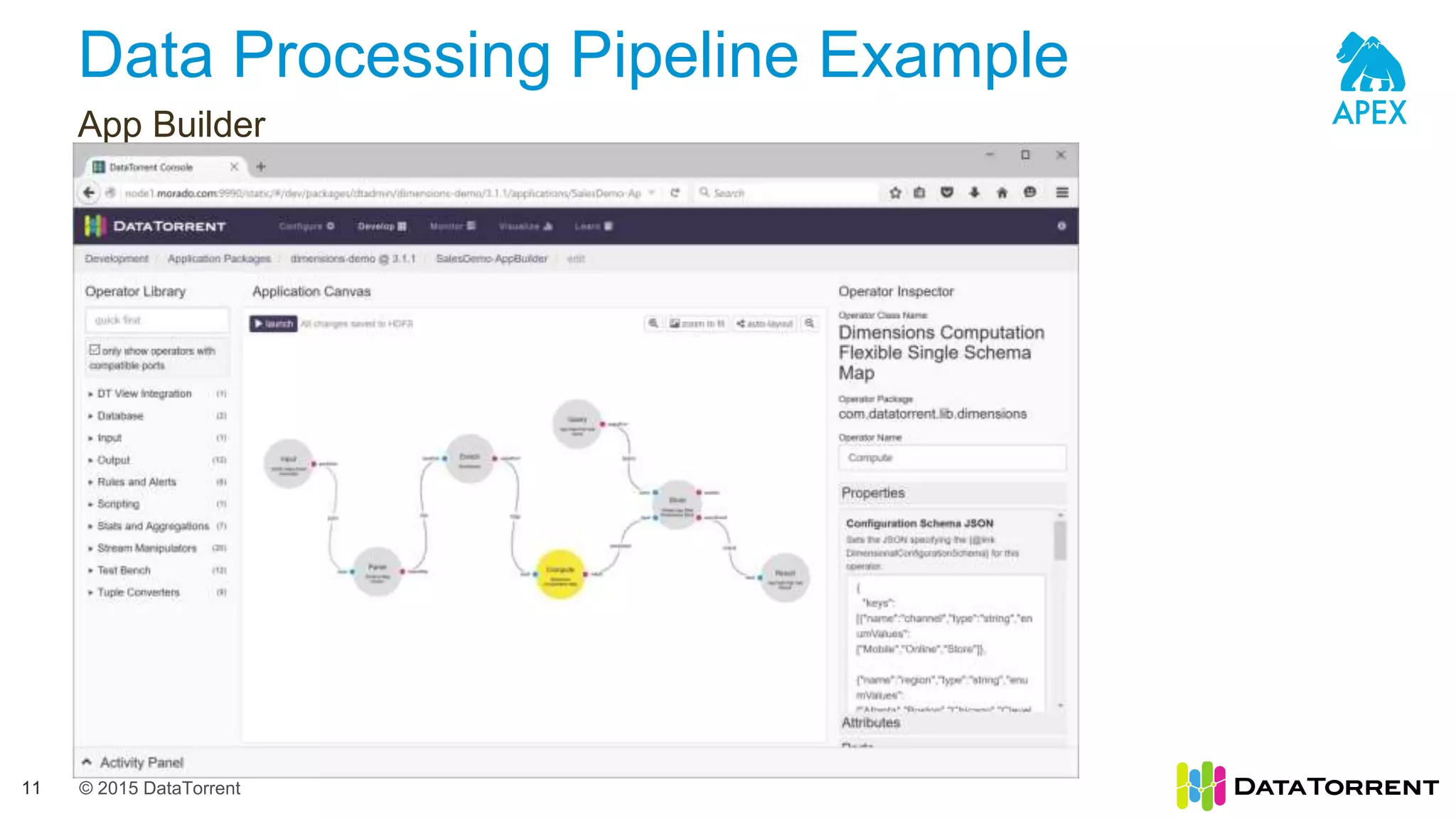
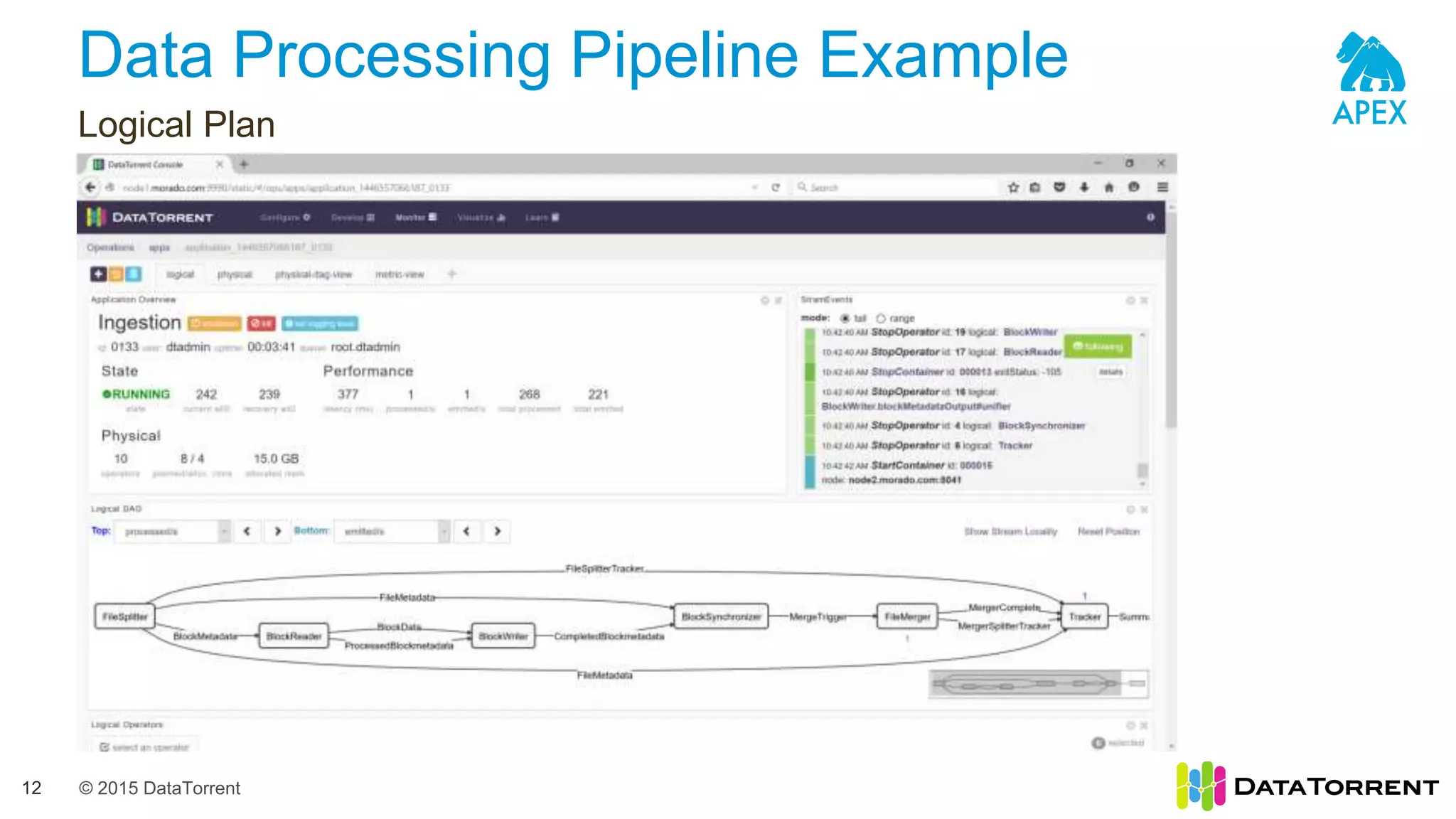
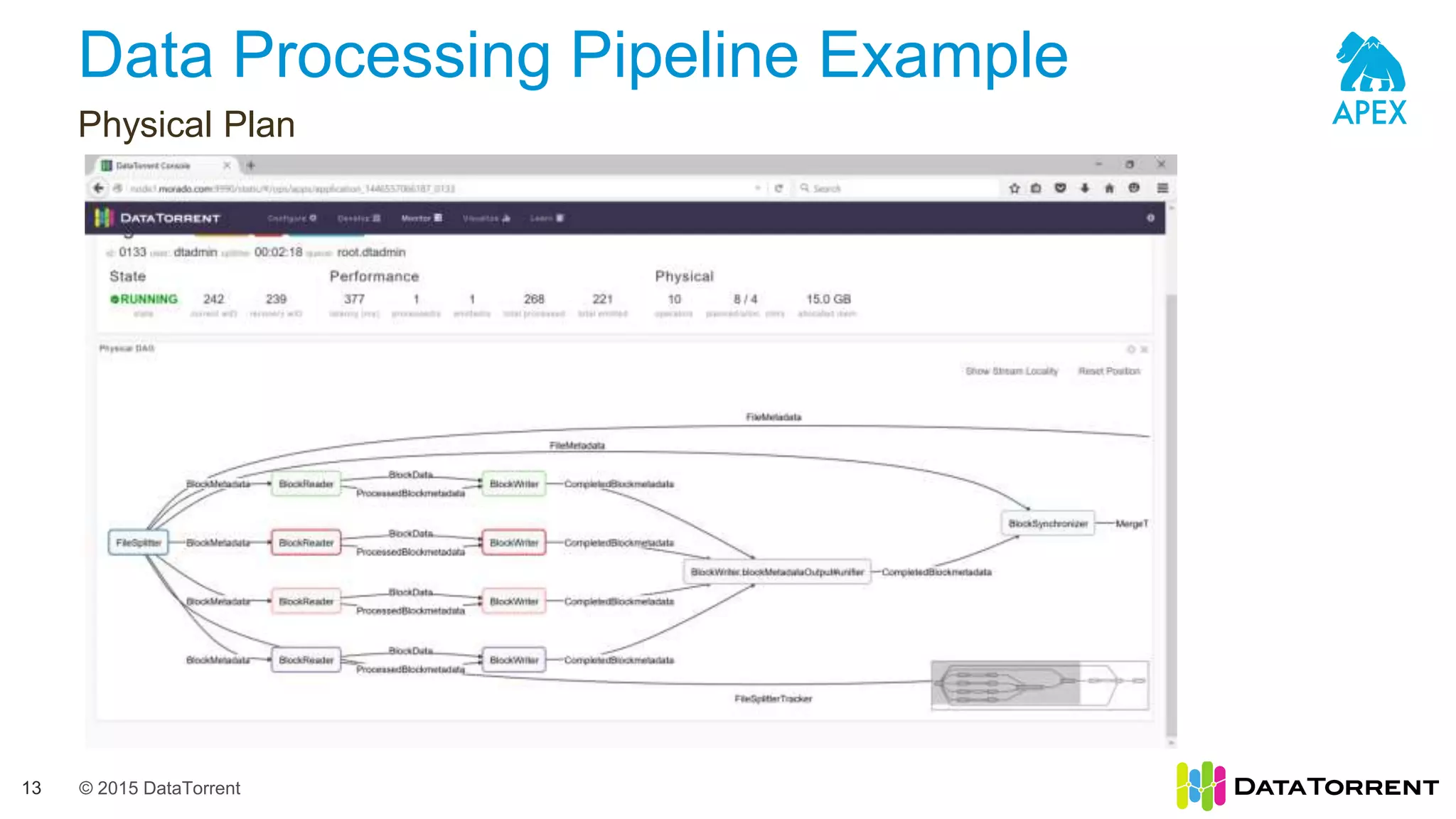
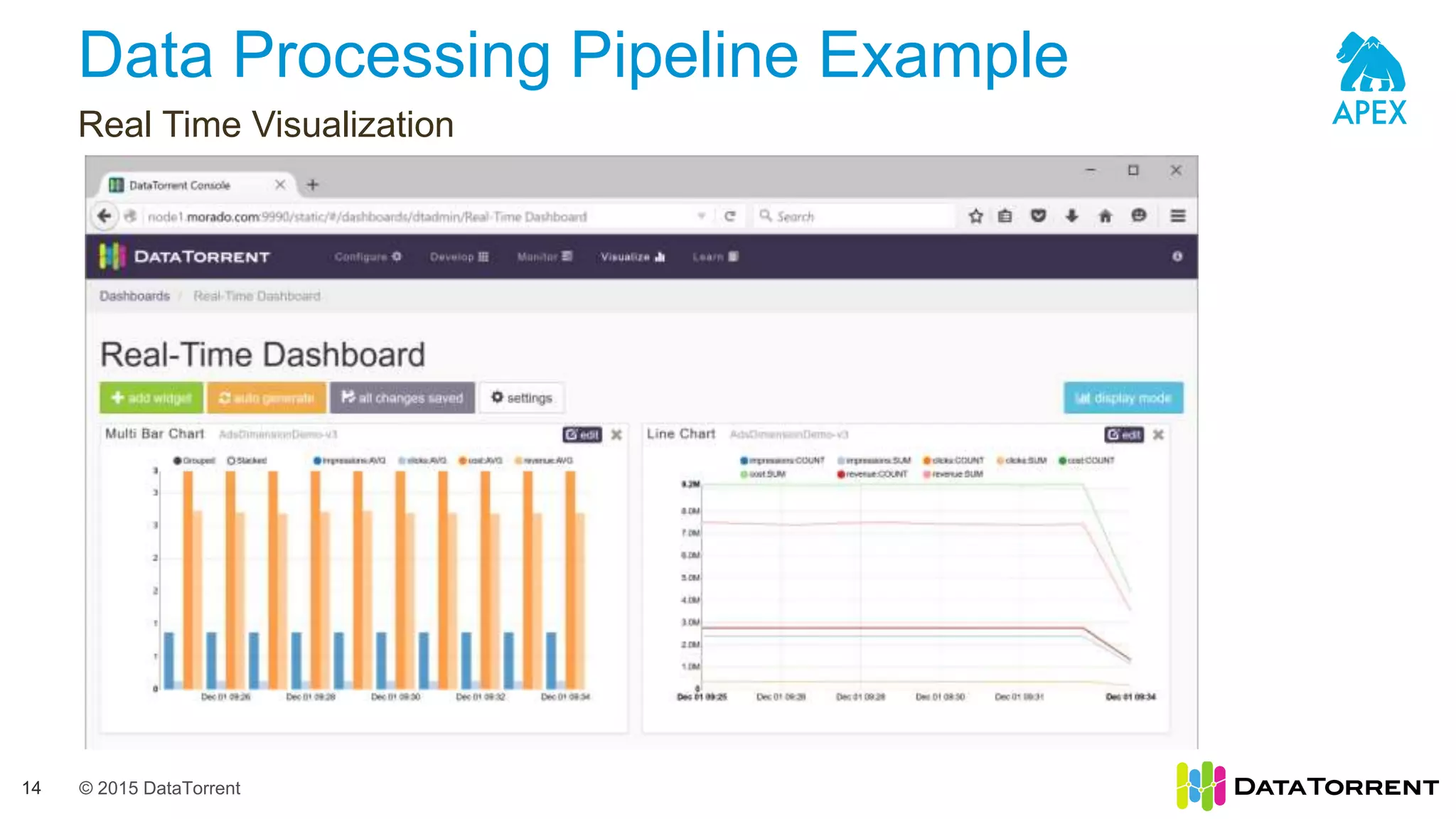

The document introduces Apache Apex, an open source unified streaming and batch processing framework. It discusses how Apex integrates with native Hadoop components like YARN and HDFS. It then describes Apex's programming model using directed acyclic graphs of operators and streams to process data. The document outlines Apex's support for scaling applications through partitioning, windowing, fault tolerance, and guarantees on processing semantics. It provides an example of building an application pipeline and shows the logical and physical plans. In closing, it directs the reader to Apache Apex community resources for more information.























































































