Download as PDF, PPTX






![2015 © Trivadis
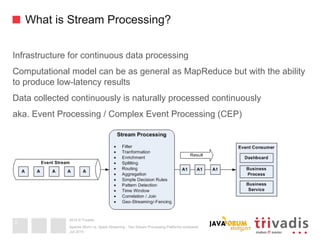
Message Delivery Semantics
At most once [0,1]
• Messages my be lost
• Messages never redelivered
At least once [1 .. n]
• Messages will never be lost
• but messages may be redelivered (might be ok if consumer can handle it)
Exactly once [1]
• Messages are never lost
• Messages are never redelivered
• Perfect message delivery
• Incurs higher latency for transactional semantics
Juli 2015
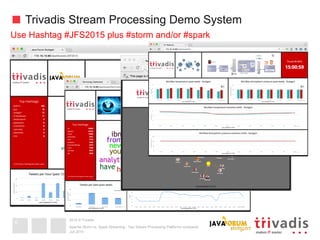
Apache Storm vs. Spark Streaming - Two Stream Processing Platforms compared
15](https://image.slidesharecdn.com/apachestormvsapachespark-v1-151129213245-lva1-app6892/85/Apache-Storm-vs-Spark-Streaming-two-stream-processing-platforms-compared-15-320.jpg)

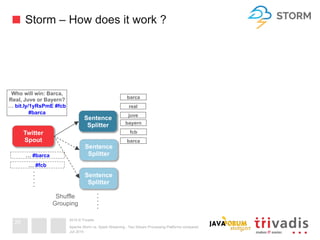
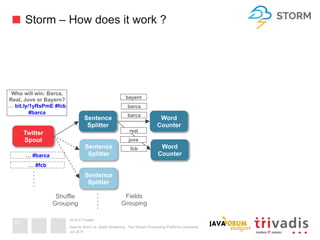
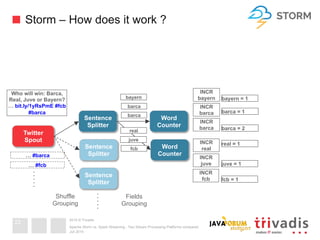
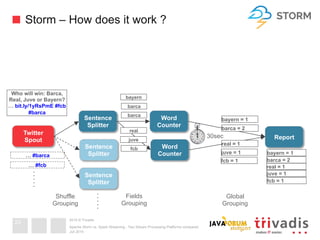






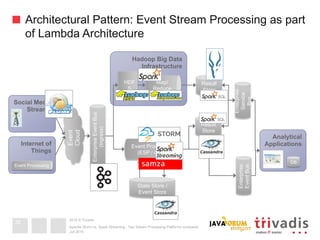
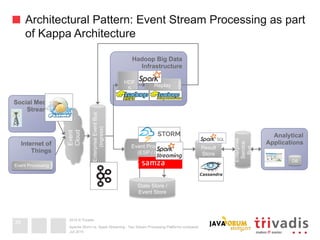
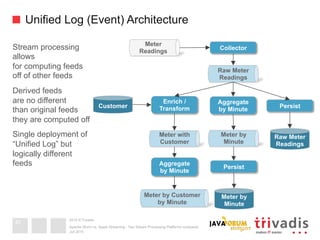
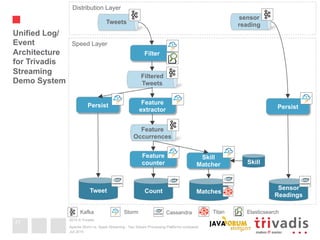

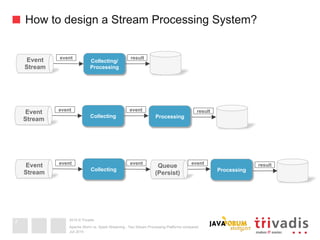
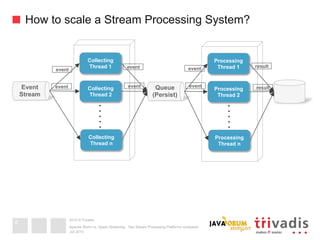
This document compares Apache Storm and Apache Spark Streaming, two stream processing platforms. It provides an overview of stream processing and how to design, scale, and ensure reliability in stream processing systems. It then describes the core concepts and functionality of Apache Storm, including how a basic topology works. It also introduces the Storm Trident high-level abstraction and compares Storm Core and Storm Trident.











































































































