Downloaded 88 times




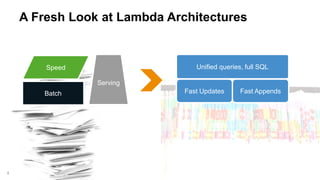
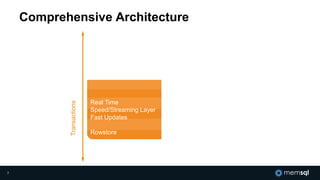
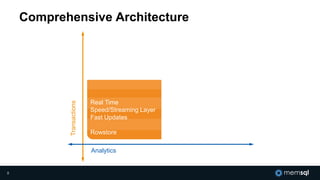
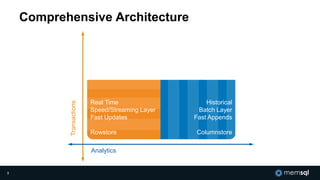
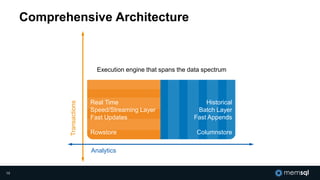
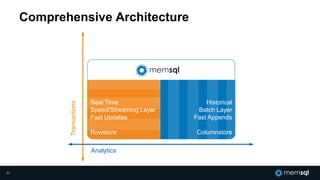




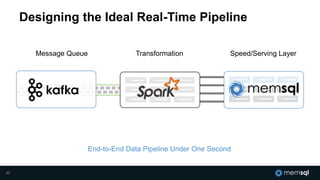




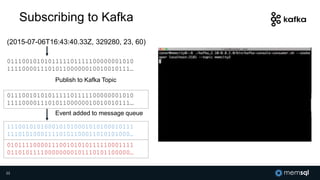
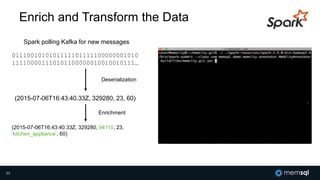



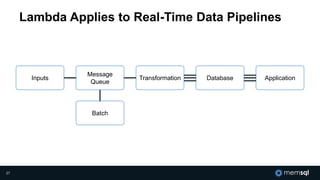
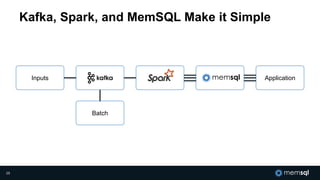

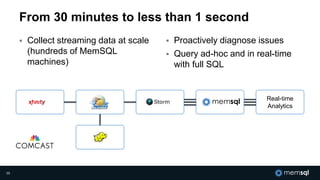

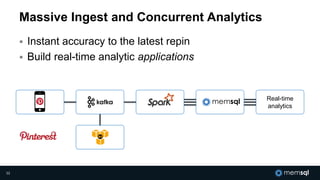

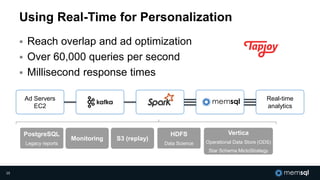



The document discusses MemSQL's strategy for building real-time data pipelines using technologies like Kafka, Spark, and operational databases. It highlights the importance of real-time analytics for businesses to stay competitive and outlines the architecture that supports both transactional and analytical processing. MemSQL aims to enable every company to become a real-time enterprise, offering unified queries and fast data processing capabilities.











































































































