




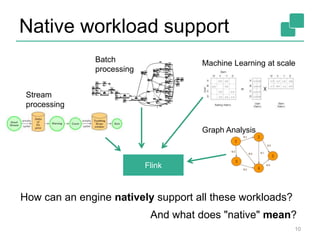



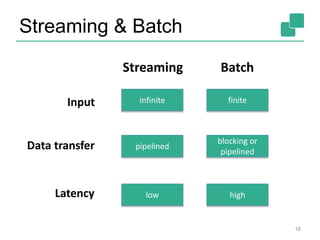




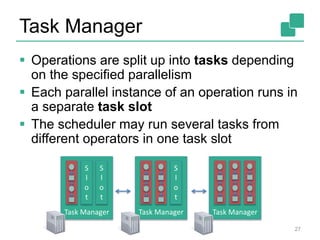
![Client
Optimize
Construct job graph
Pass job graph to job manager
Retrieve job results
25
Job Manager
Client
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Optimizer
Type
extraction
Data
Source
orders.tbl
Filter
Map
DataSourc
e
lineitem.tbl
Join
Hybrid Hash
build
HT
probe
hash-part [0] hash-part [0]
GroupRed
sort
forward](https://image.slidesharecdn.com/flinkoverview-151019150526-lva1-app6891/85/Apache-Flink-Training-System-Overview-24-320.jpg)
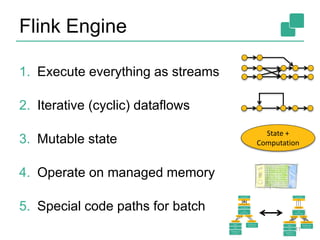
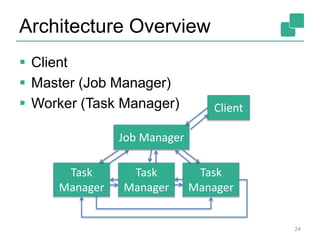
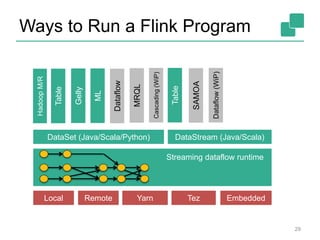
![Job Manager
Parallelization: Create Execution Graph
Scheduling: Assign tasks to task managers
State: Supervise the execution
26
Job Manager
Data
Source
orders.tbl
Filter
Map
DataSour
ce
lineitem.tbl
Join
Hybrid Hash
build
HT
prob
e
hash-part [0] hash-part [0]
GroupRed
sort
forwar
d
Task Manager
Task Manager
Task Manager
Task Manager
Data
Source
orders.tbl
Filter
Map
DataSour
ce
lineitem.tbl
Join
Hybrid Hash
build
HT
prob
e
hash-part [0] hash-part [0]
GroupRed
sort
forwar
d
Data
Source
orders.tbl
Filter
Map
DataSour
ce
lineitem.tbl
Join
Hybrid Hash
build
HT
prob
e
hash-part [0] hash-part [0]
GroupRed
sort
forwar
d
Data
Source
orders.tbl
Filter
Map
DataSour
ce
lineitem.tbl
Join
Hybrid Hash
build
HT
prob
e
hash-part [0] hash-part [0]
GroupRed
sort
forwar
d
Data
Source
orders.tbl
Filter
Map
DataSour
ce
lineitem.tbl
Join
Hybrid Hash
build
HT
prob
e
hash-part [0] hash-part [0]
GroupRed
sort
forwar
d](https://image.slidesharecdn.com/flinkoverview-151019150526-lva1-app6891/85/Apache-Flink-Training-System-Overview-25-320.jpg)





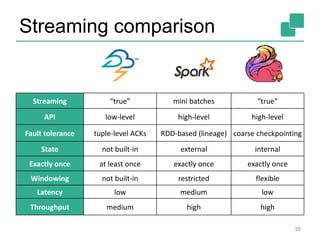


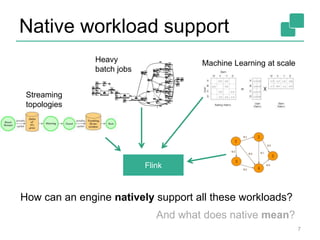
This document provides an overview of Apache Flink, an open-source stream processing framework. It discusses Flink's capabilities in supporting streaming, batch, and iterative processing natively through a streaming dataflow model. It also describes Flink's architecture including the client, job manager, task managers, and various execution setups like local, remote, YARN, and embedded. Finally, it compares Flink to other stream and batch processing systems in terms of their APIs, fault tolerance guarantees, and strengths.











































































































