Download as PDF, PPTX









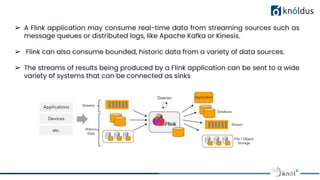




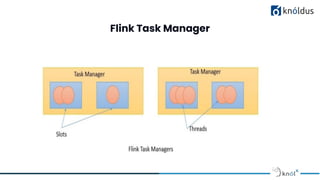

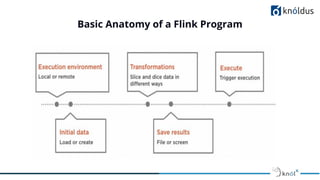





The document presents an introduction to Apache Flink, emphasizing its role as a big data framework for stateful computations on both bounded and unbounded data streams. It discusses the evolution of big data, challenges associated with it, and highlights Flink's advantages such as real-time stream processing, high performance, and fault tolerance. The presentation also outlines Flink's architecture, features, and provides guidelines for session etiquette.























































































