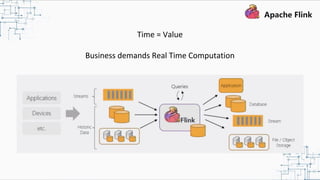
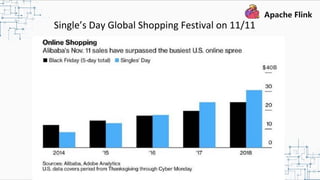
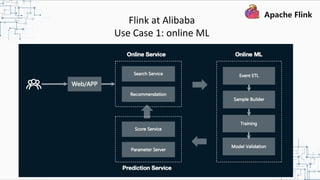
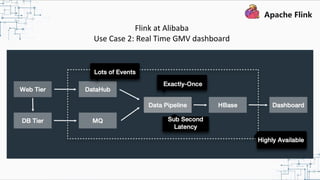
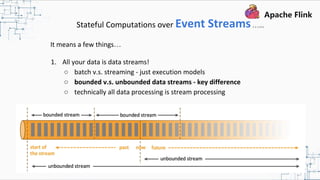
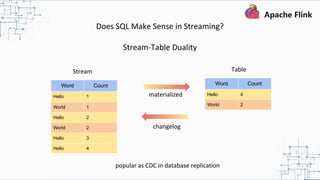
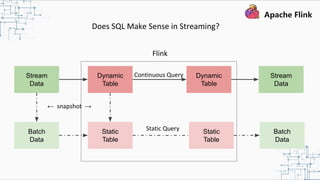
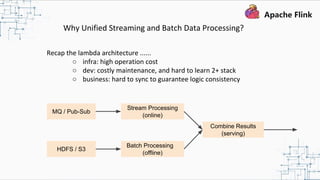
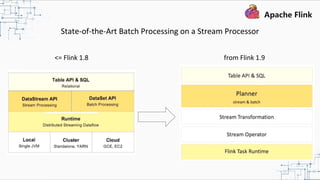
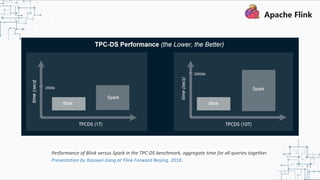
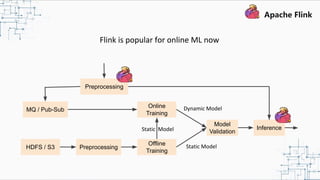
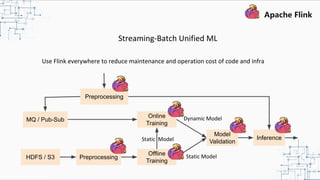
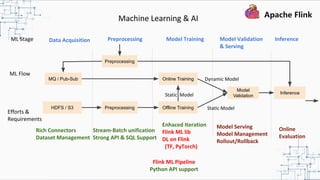
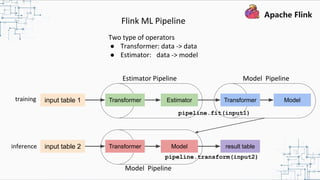
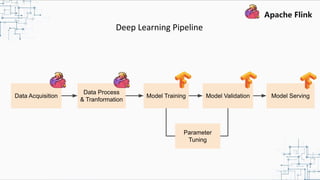
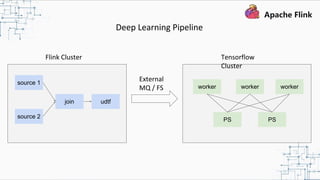
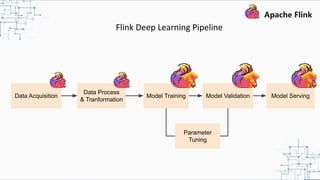
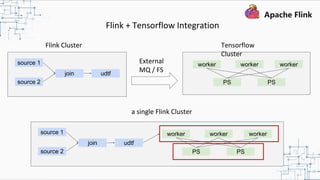
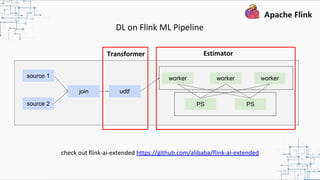
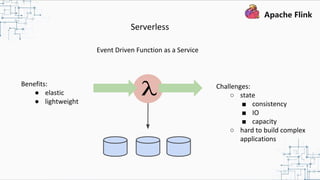
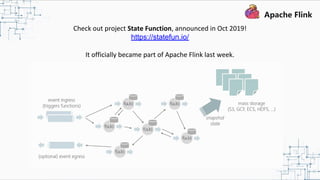
This document provides an overview and summary of Apache Flink. It discusses how Flink enables stateful stream processing and beyond. Key points include that Flink allows for stateful computations over event streams in an expressive, scalable, fault-tolerant way through layered APIs. It also supports batch processing, machine learning, and serving as a stream processor that unifies streaming and batch. The document highlights many use cases of Flink at Alibaba and how it powers critical systems like real-time analytics and recommendations.