Download to read offline





![10
Optimized Execution
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Optimizer
Type extraction
stack
Task
scheduling
Dataflow
metadata
Pre-flight (Client)
Master
Worker
Data Source
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
Dataflow Graph
Independent of
batch or
streaming job
deploy
operators
track
intermediate
results](https://image.slidesharecdn.com/introductiontoflink-meetupvienna-151022122019-lva1-app6891/75/Introduction-to-Apache-Flink-at-Vienna-Meet-Up-10-2048.jpg)


![19
Expressive APIs
19
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/introductiontoflink-meetupvienna-151022122019-lva1-app6891/75/Introduction-to-Apache-Flink-at-Vienna-Meet-Up-19-2048.jpg)


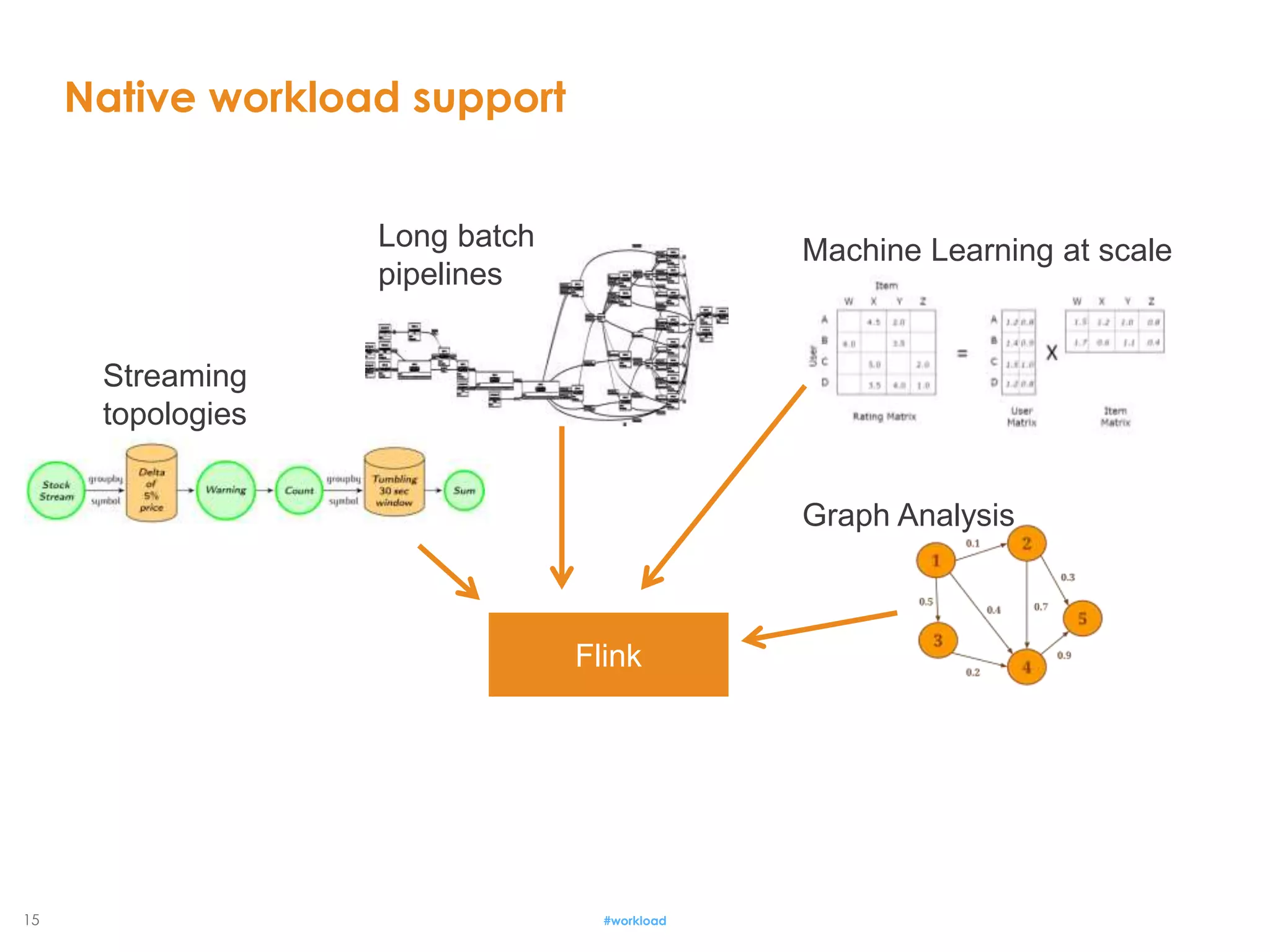
The document provides an introduction to Apache Flink, emphasizing its capabilities as a native streaming data flow engine. It contrasts streaming and batch processing, highlighting the evolution of technologies and the growing demand for real-time data processing in business. Flink's architecture supports various workloads, including streaming topologies, batch pipelines, and machine learning, making it a versatile solution for modern data processing needs.



































































