Download as PDF, PPTX
























![© 2019 Ververica 42
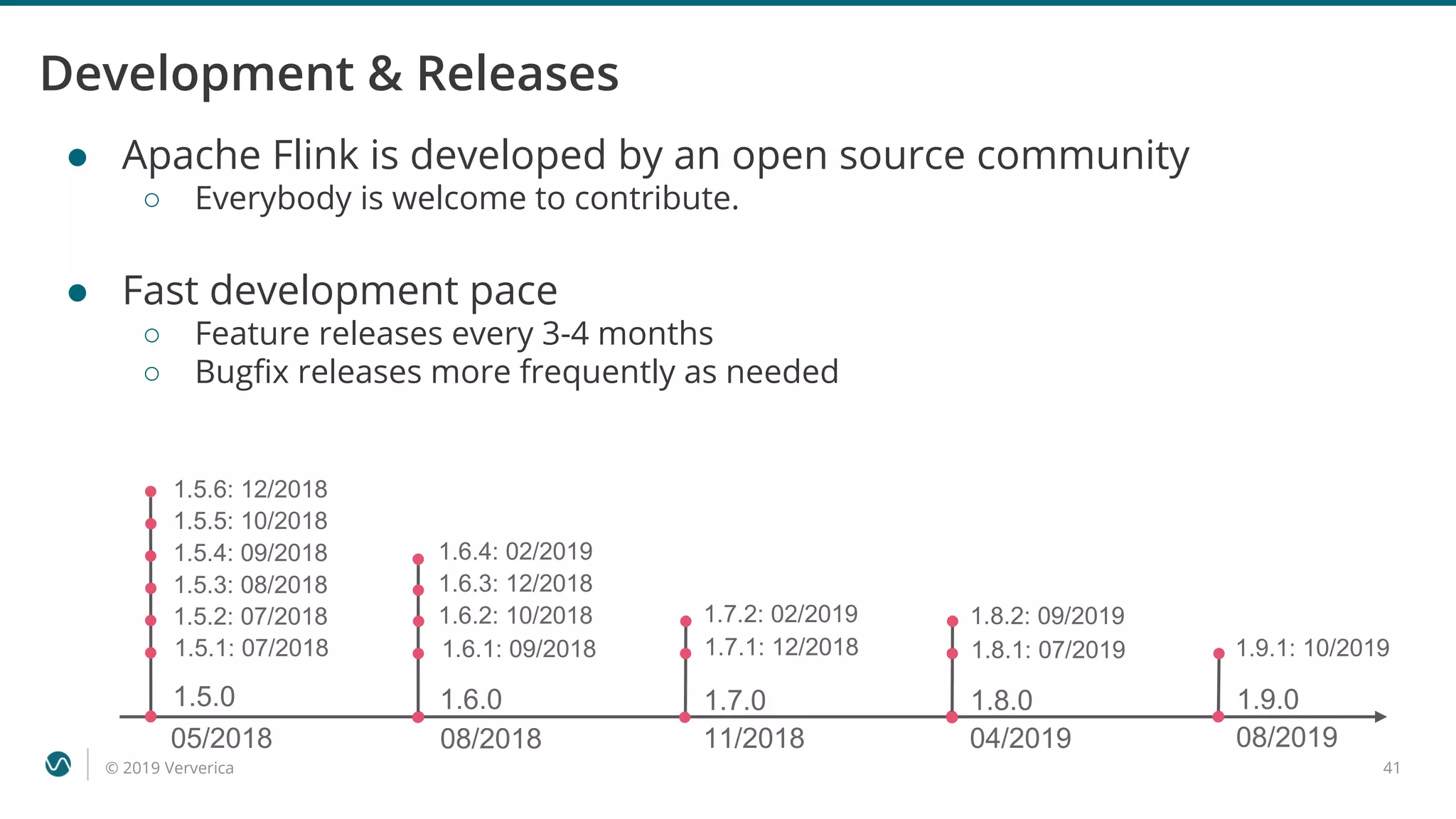
Growing & Active Community
● Flink’s community is very active and growing
● The community is answering many questions every day
○ In 2018, we had the most active user mailing lists of all 200+ ASF projects
○ ~4000 questions on Stack Overflow: [apache-flink], [flink-streaming], [flink-sql]](https://image.slidesharecdn.com/stream-processing-with-apache-flink-ververicatimowalther-191112103056/75/Stream-processing-with-Apache-Flink-Timo-Walther-Ververica-42-2048.jpg)







Apache Flink is a powerful open-source platform for stream and batch processing, offering scalable and fault-tolerant stateful computations. It provides a unified environment for processing both real-time and recorded data with strong consistency guarantees. The platform is supported by a growing community and a wide array of deployment options and APIs, catering to various analytics and event-driven application needs.










































































