Downloaded 16 times


![Word count in Flink
5
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(1,MINUTES)).every(Time.of(30,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/flinkpastpresentfuture-150512152136-lva1-app6892/75/Apache-Flink-Past-Present-and-Future-5-2048.jpg)


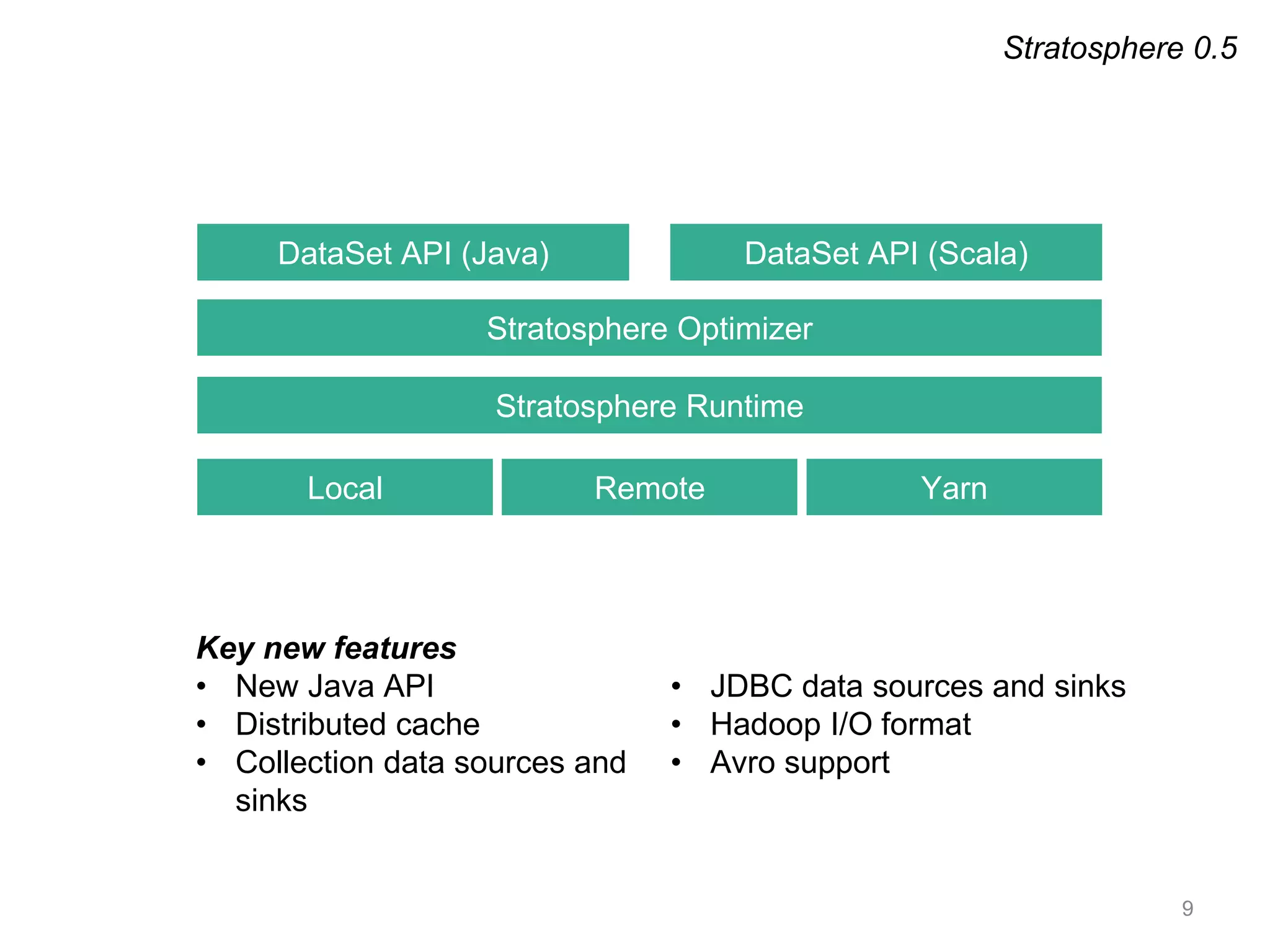
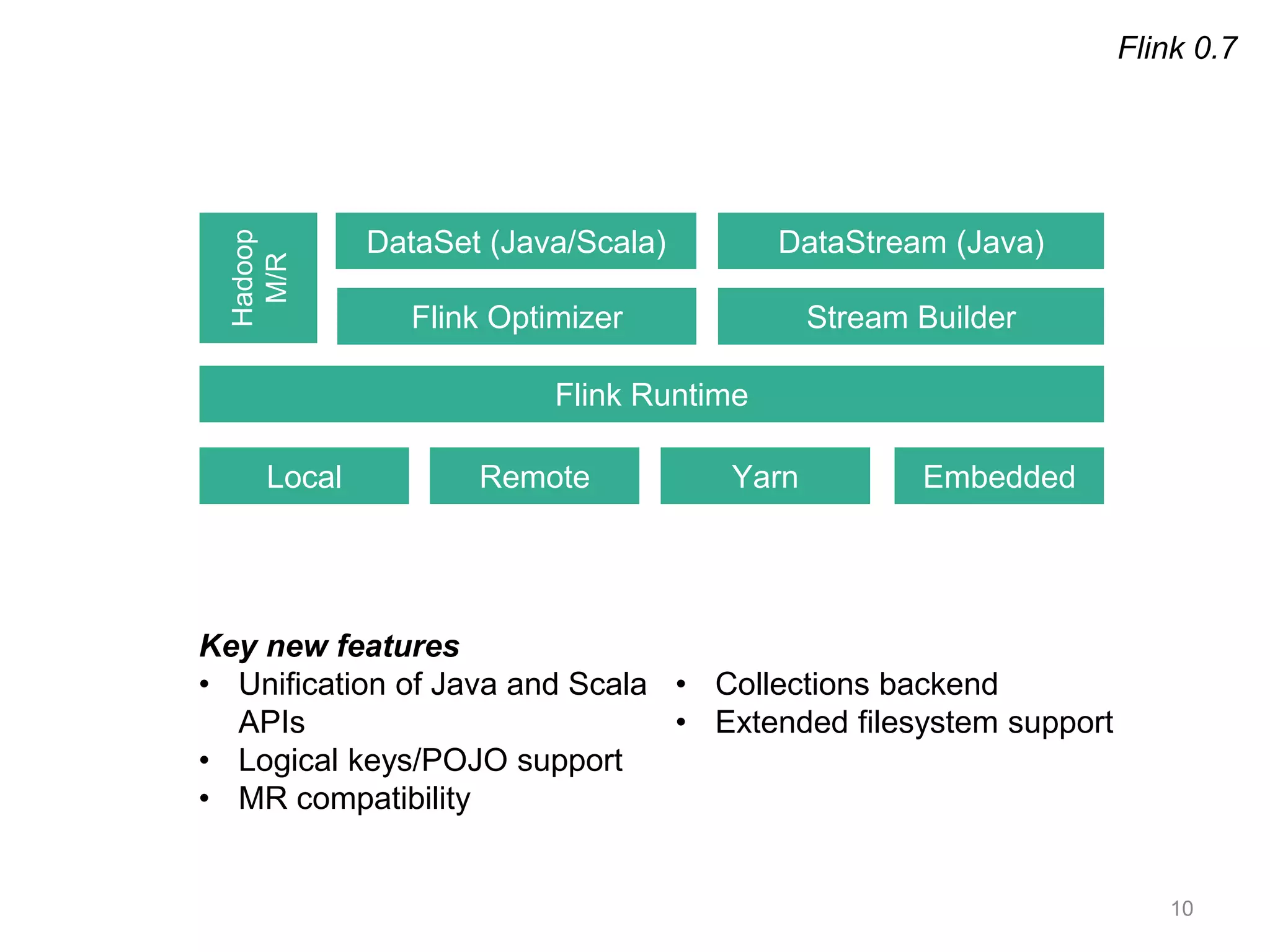
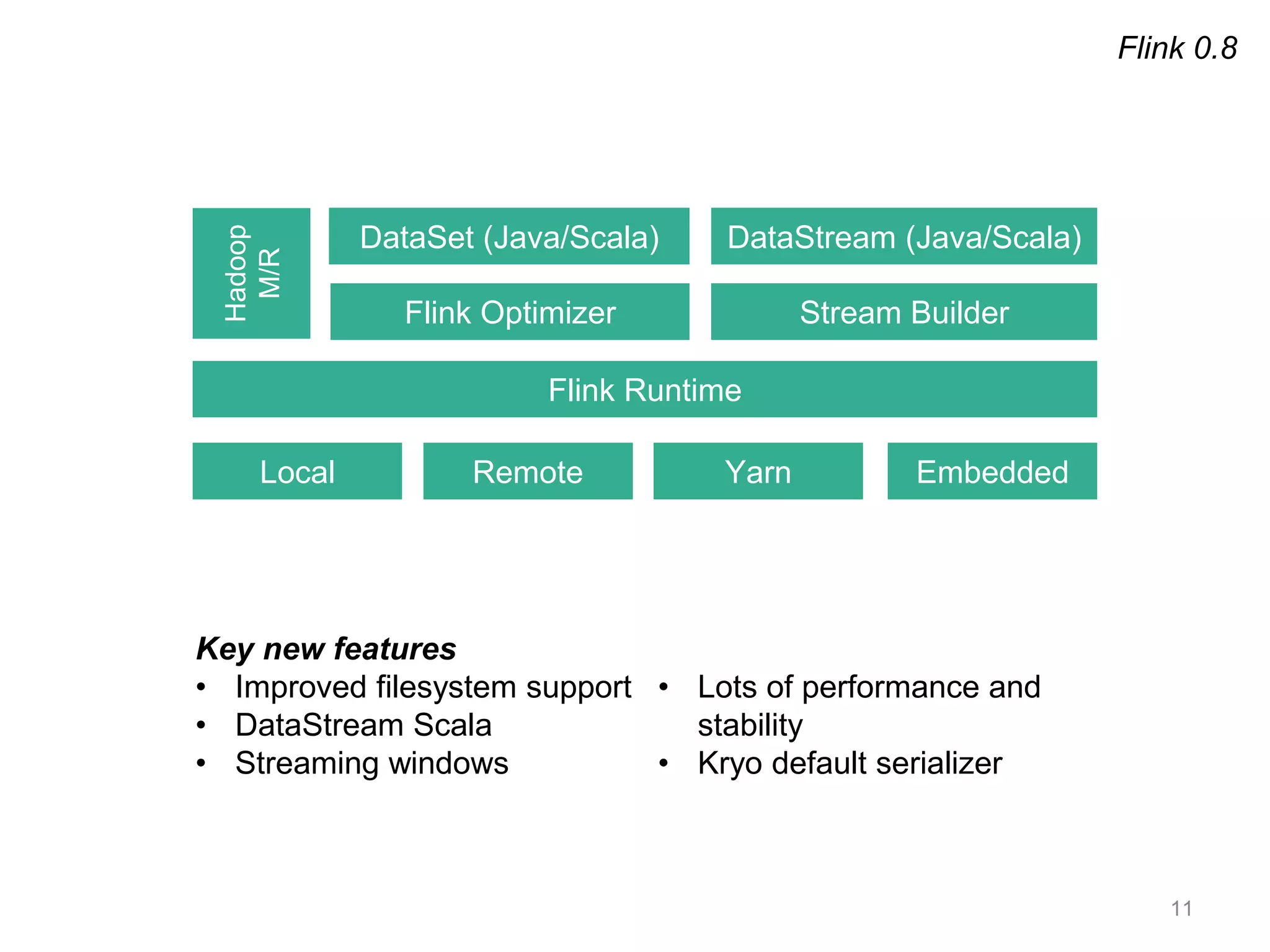
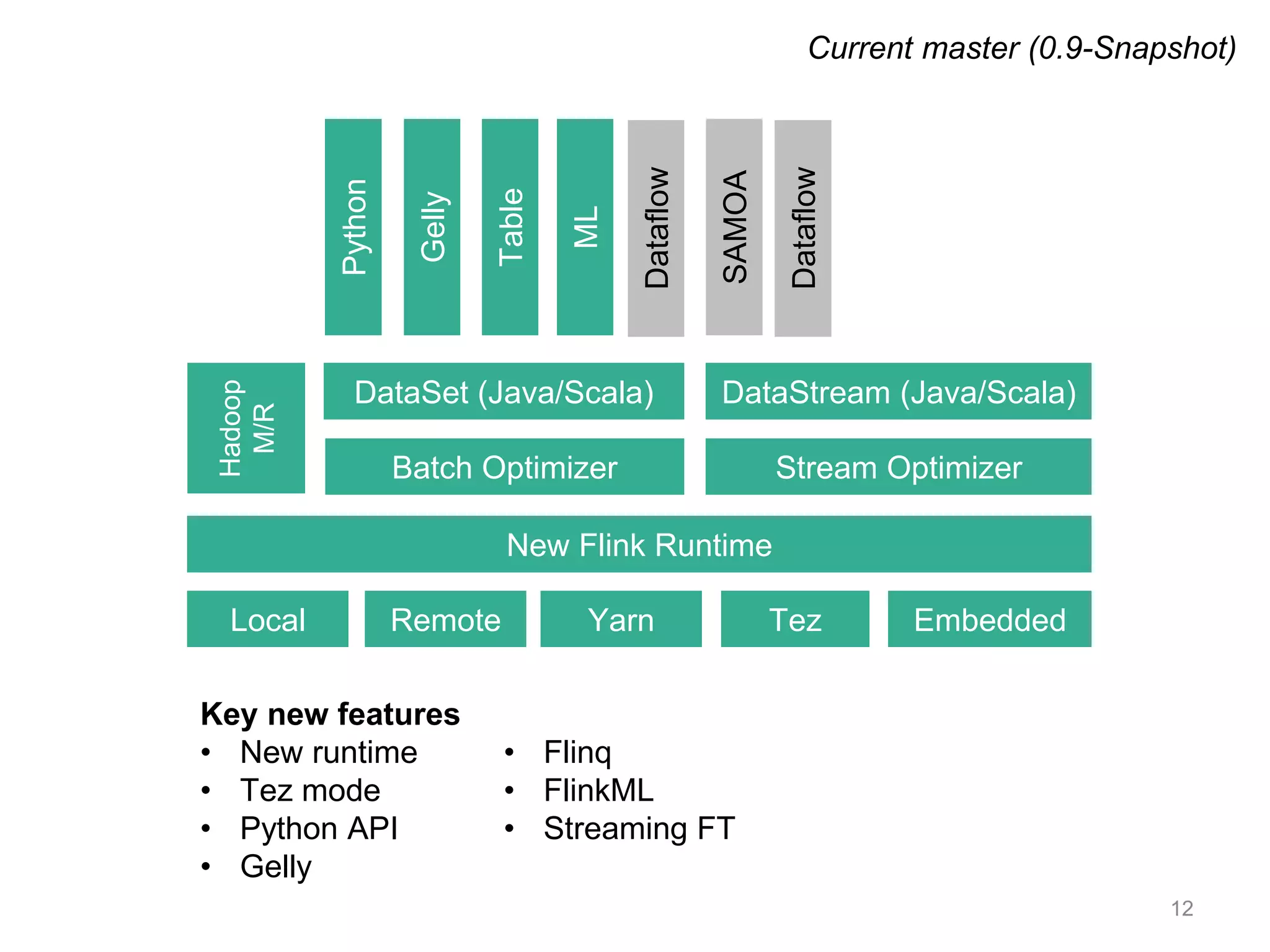
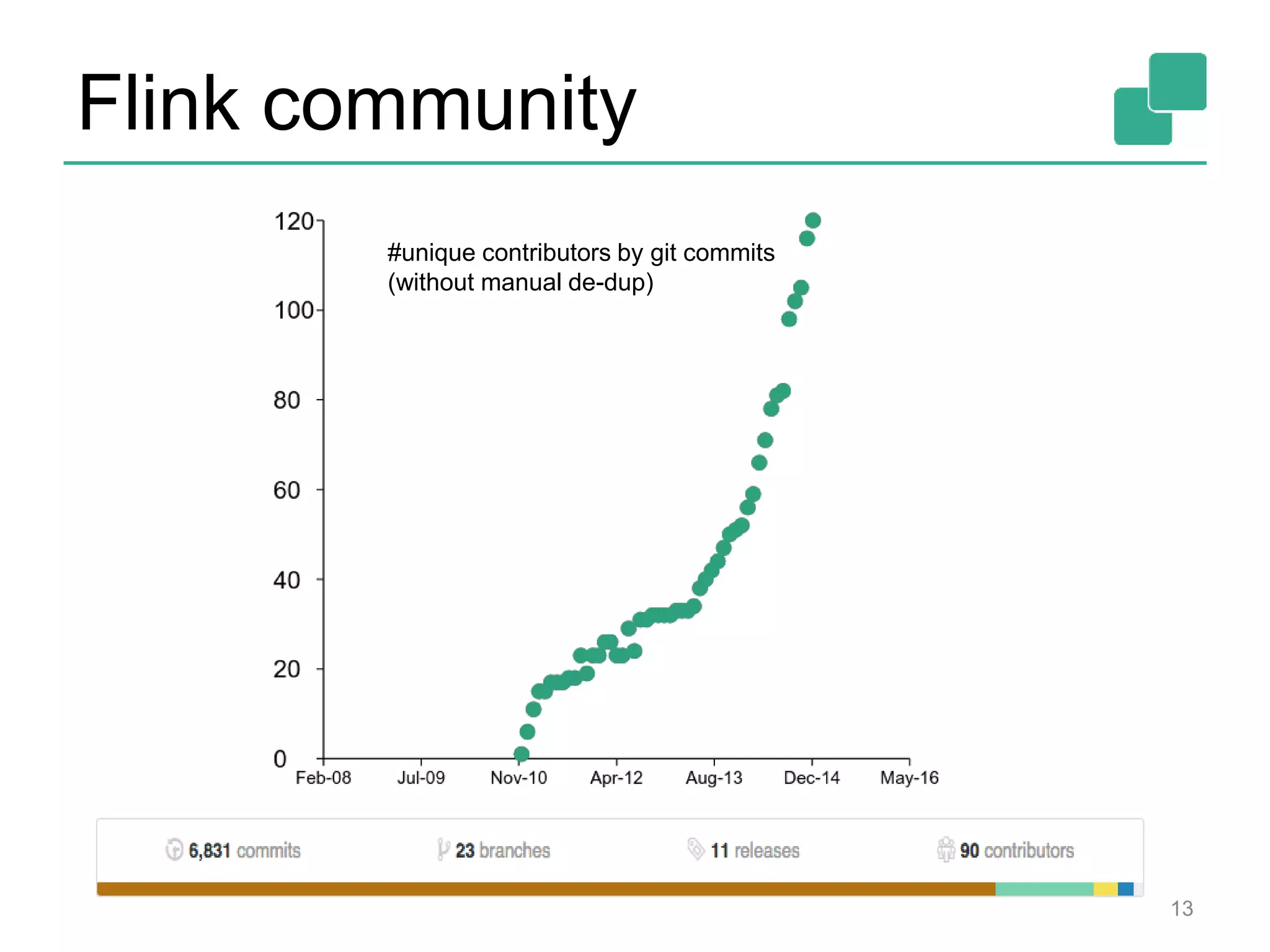


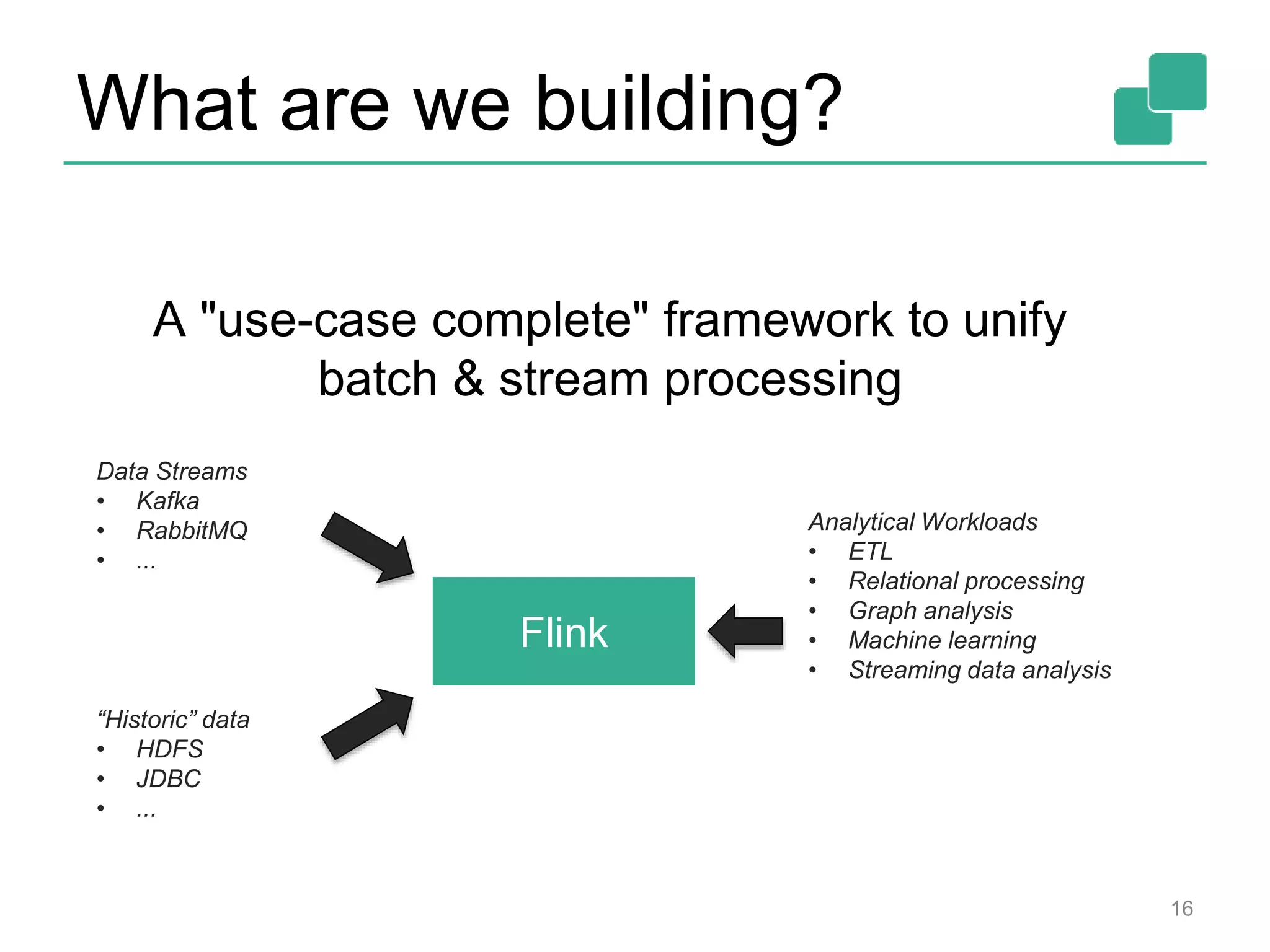
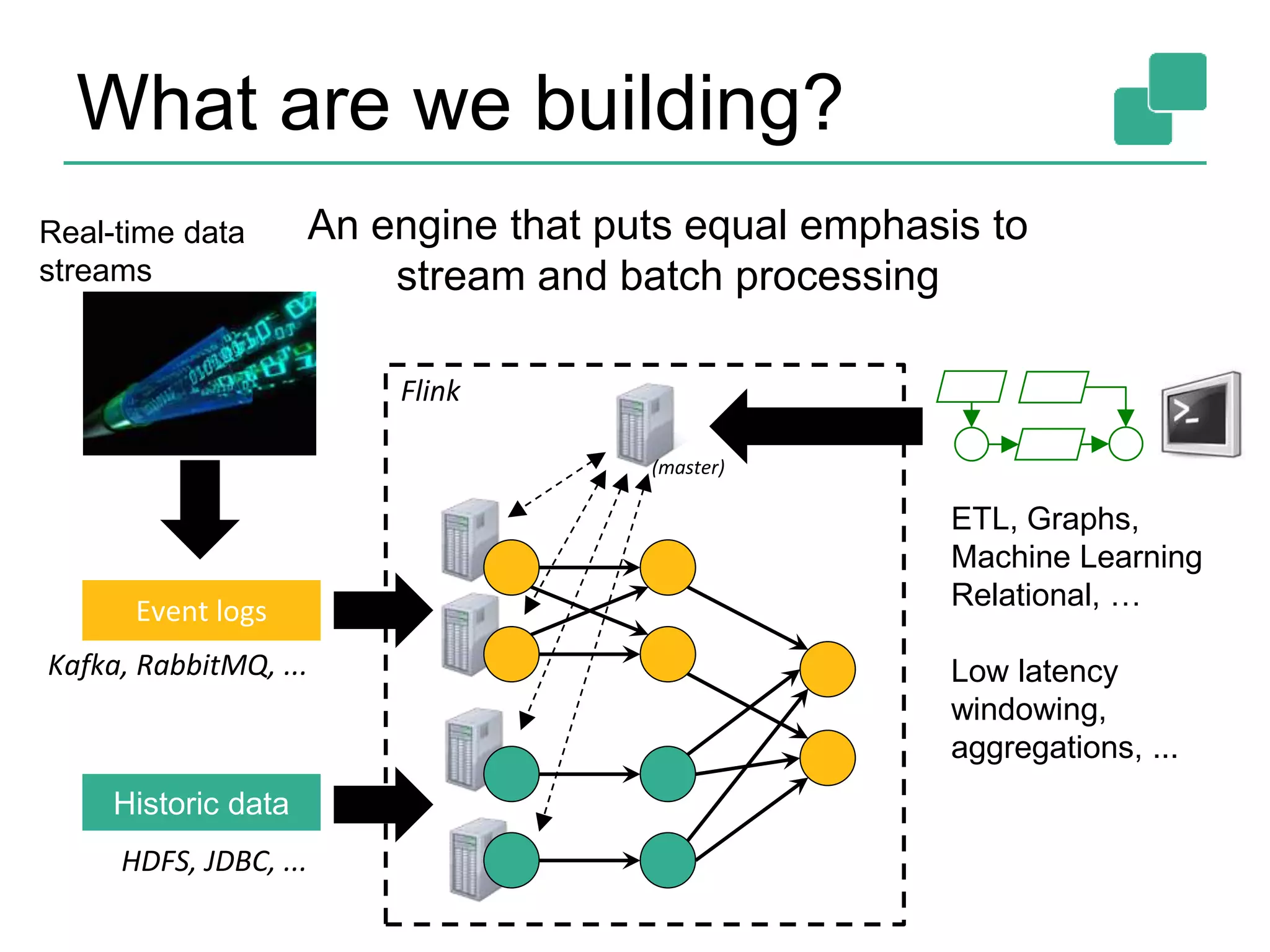

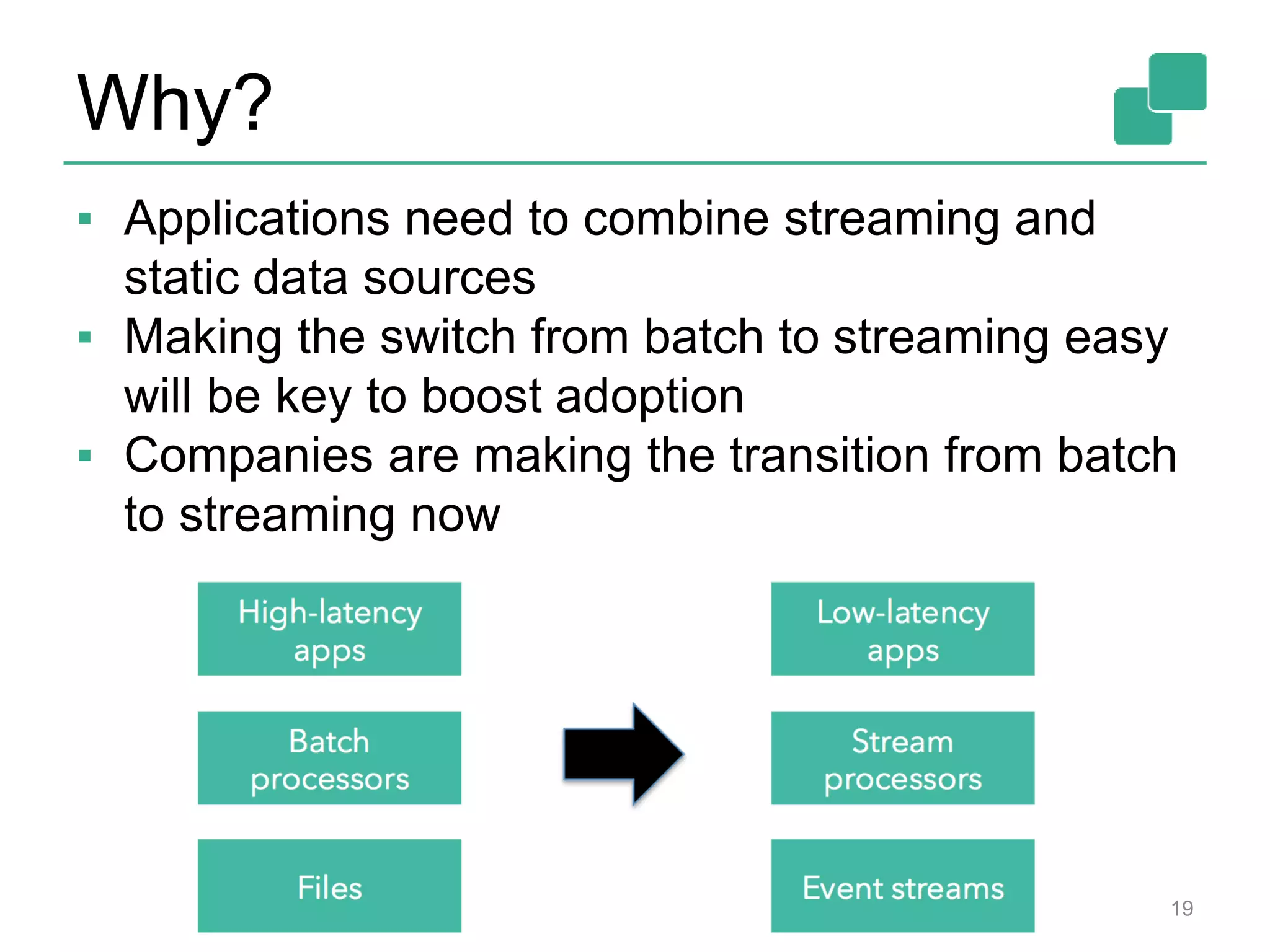
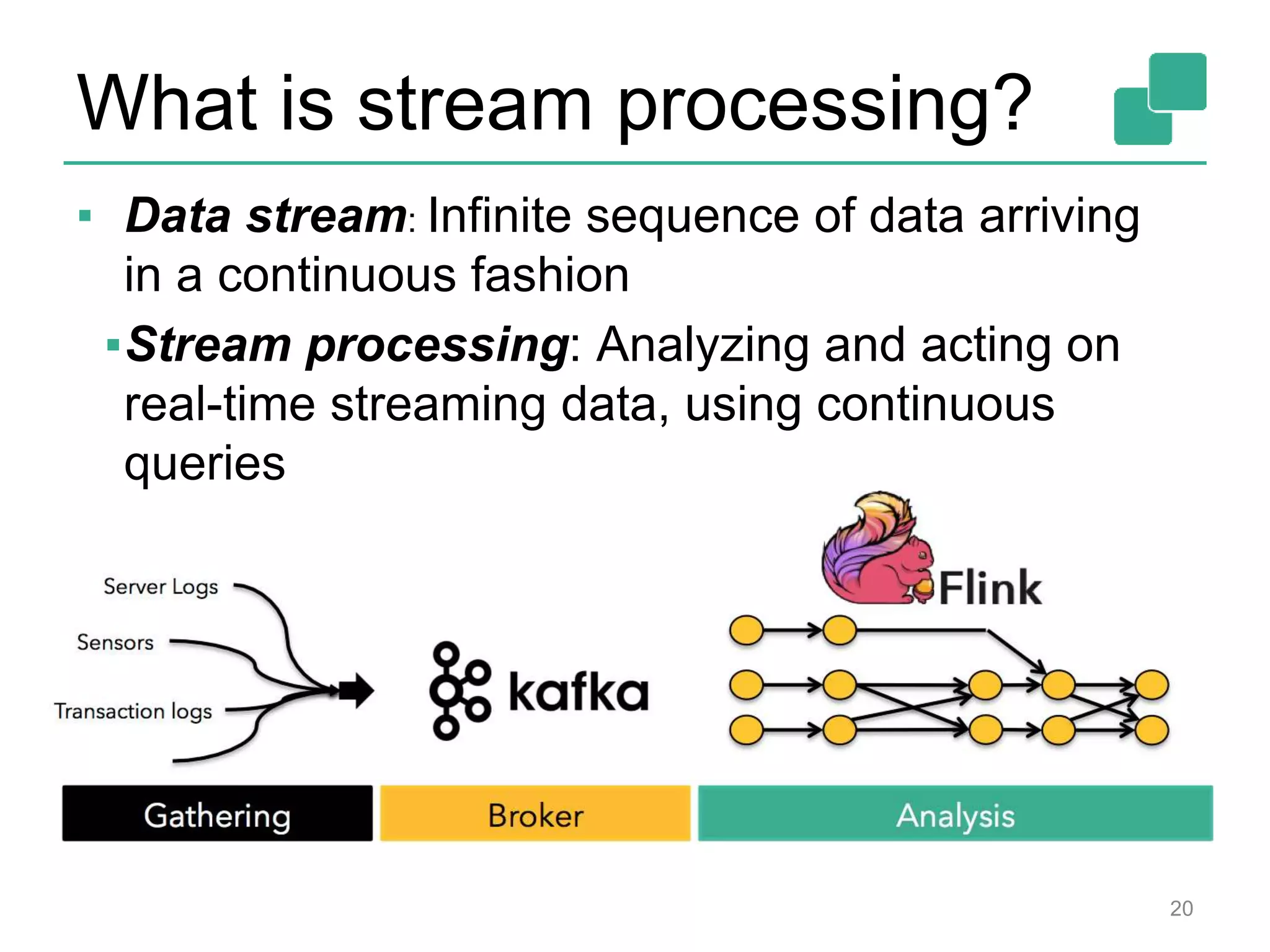
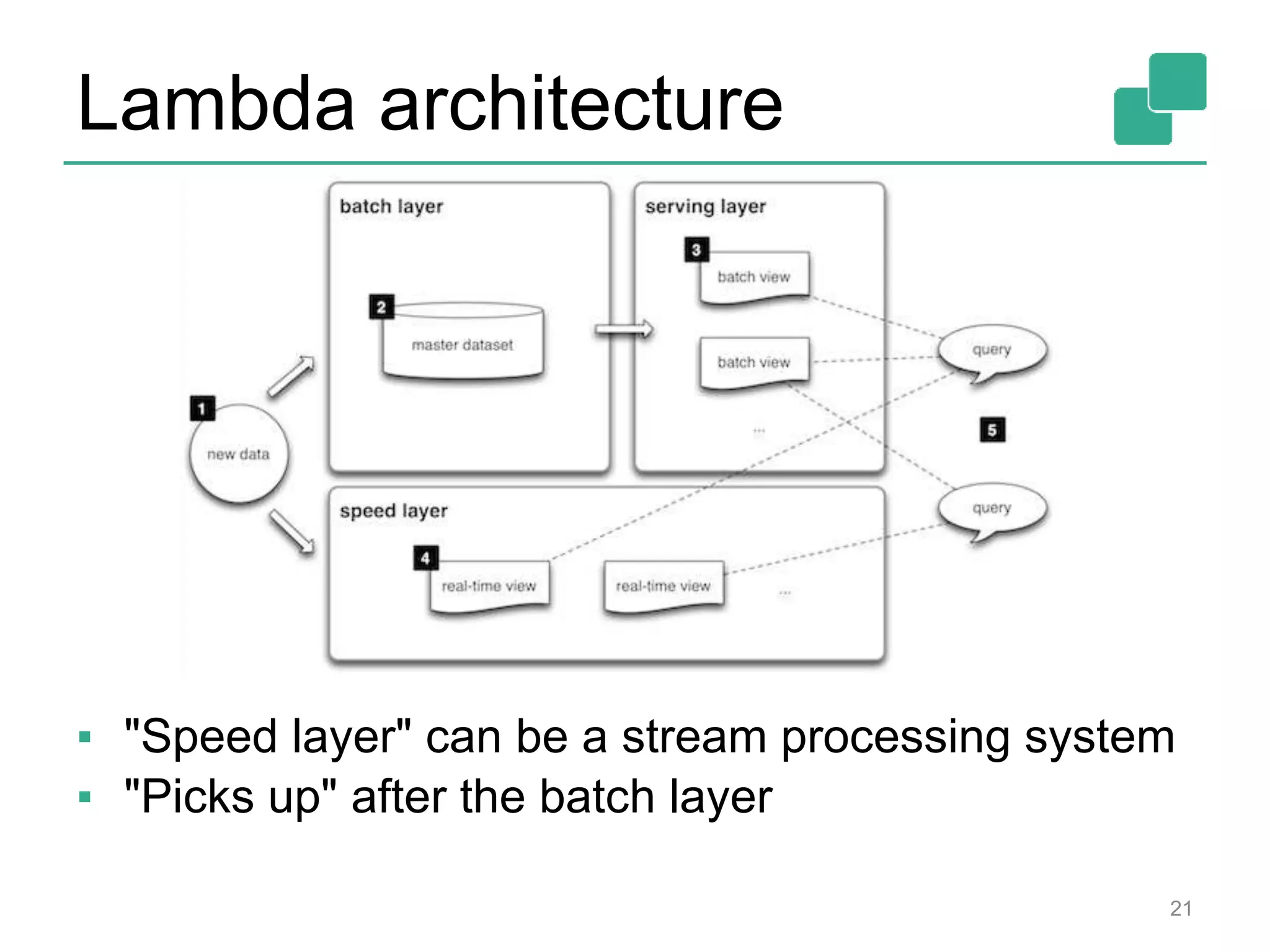
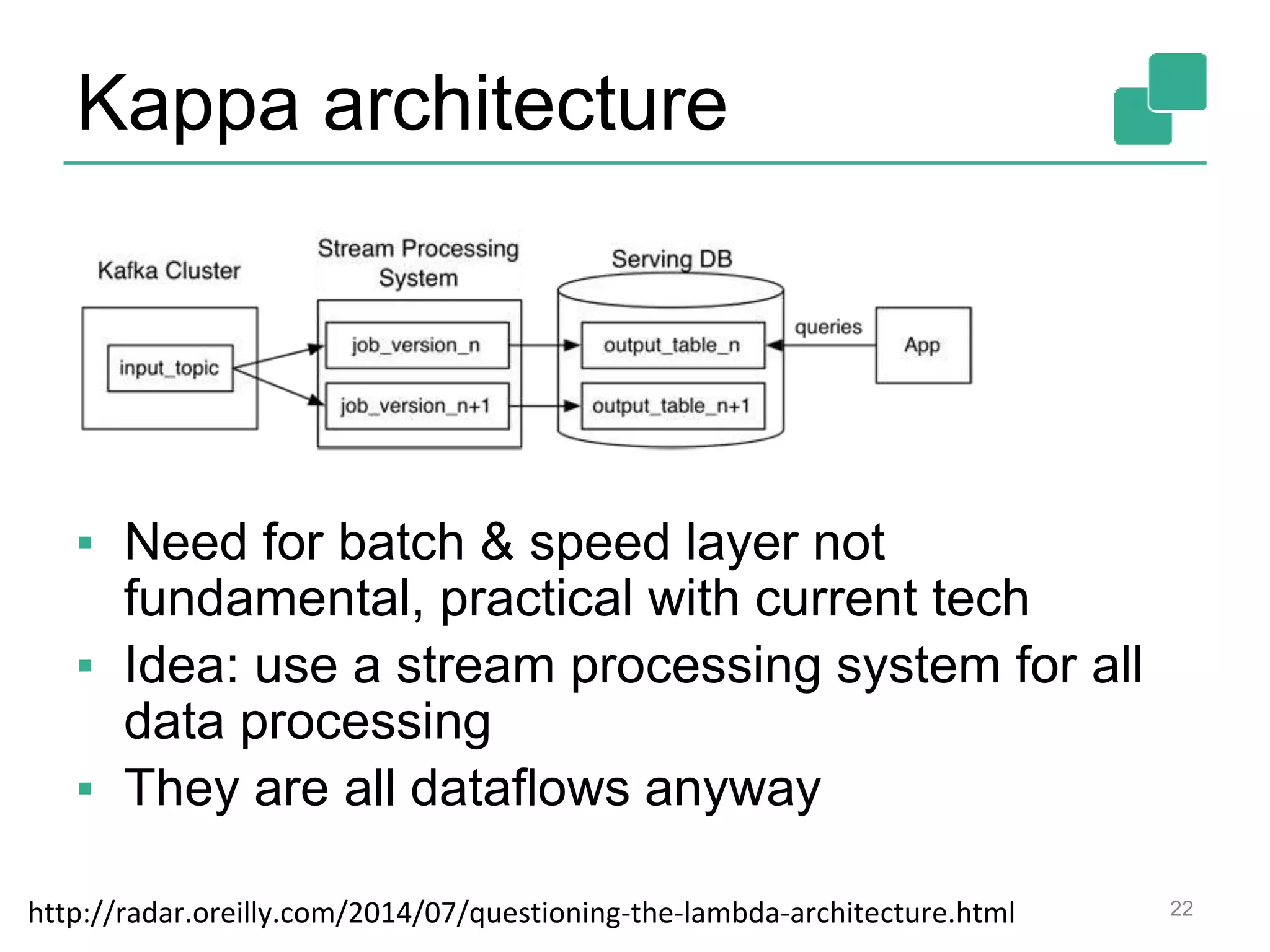






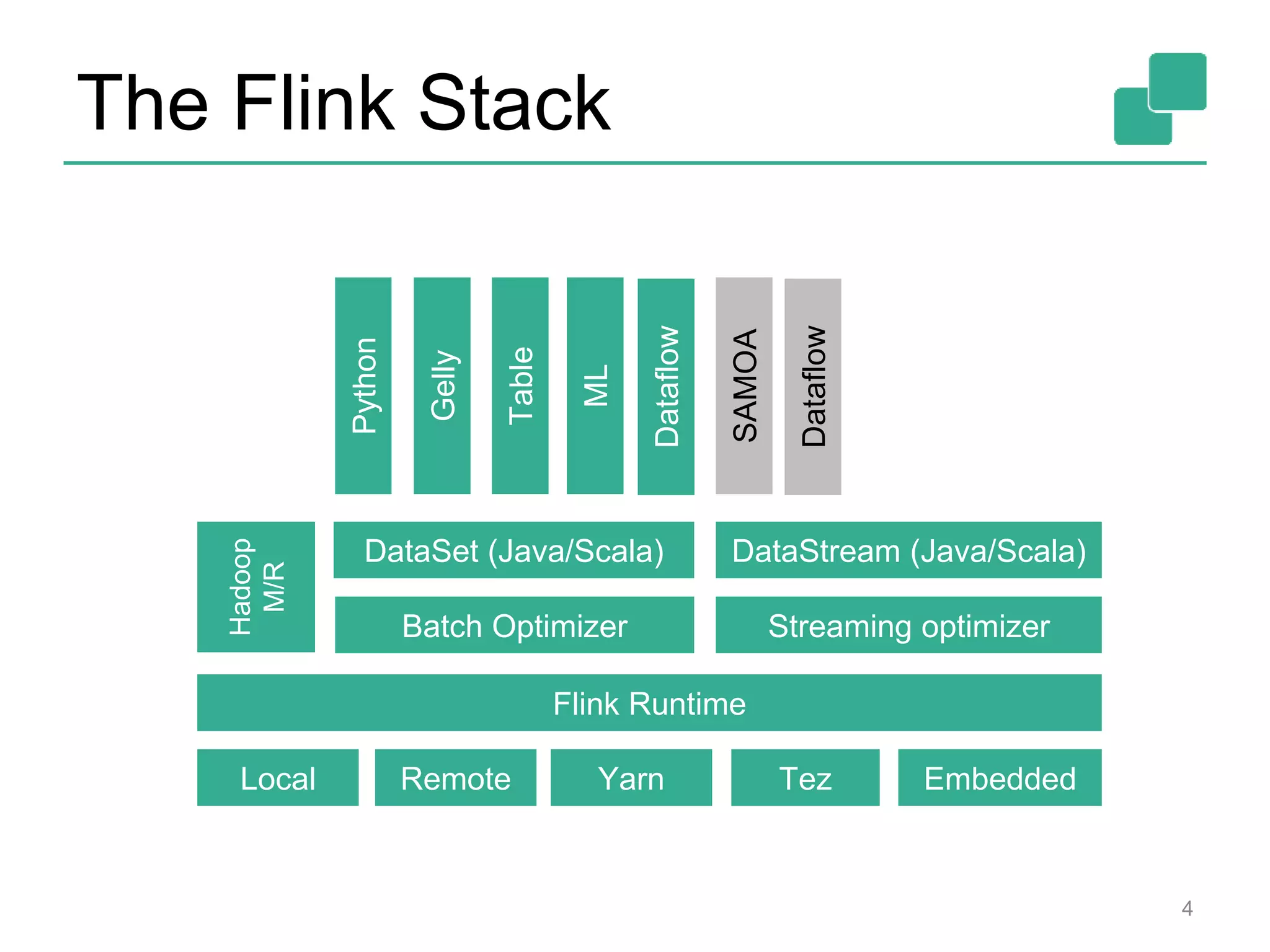
Apache Flink is a distributed data flow processing system that focuses on large-scale data analytics with unified real-time stream and batch processing. It provides expressive APIs in Java, Scala, and Python, making it suitable for various tasks such as ETL jobs, graph analysis, and machine learning. The project has seen significant improvements, emphasizing integration of batch and stream processing to facilitate adoption in modern applications.









































































