Downloaded 164 times




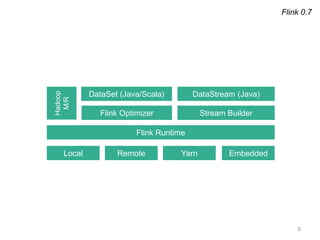
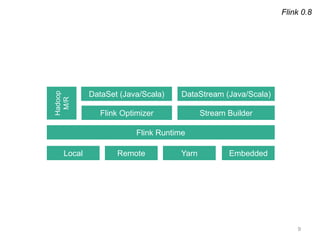
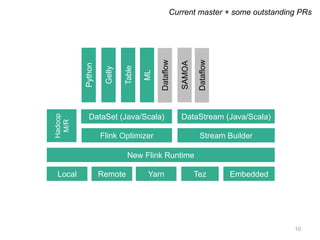

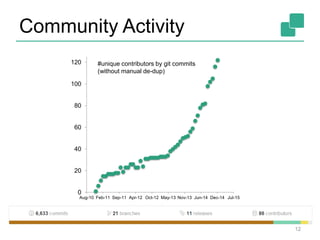

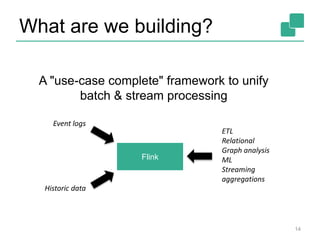
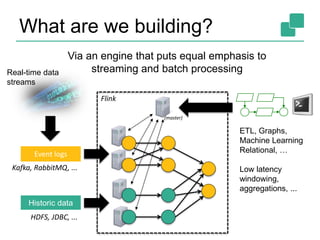

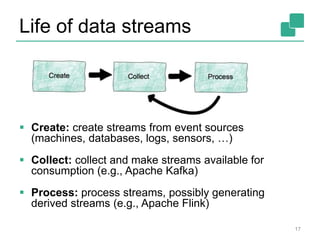
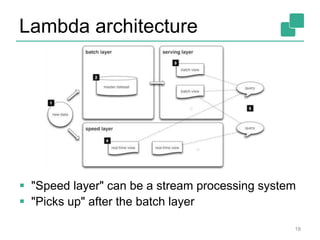
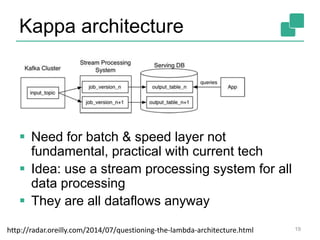








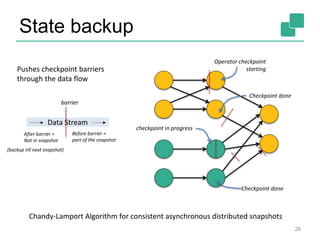



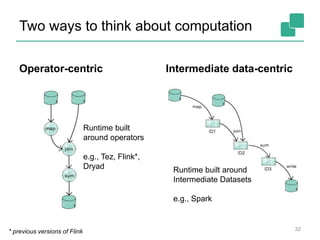
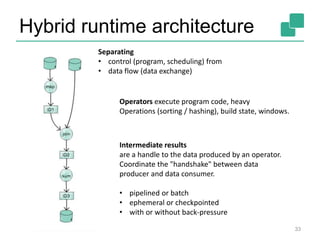


The document provides a retrospective and vision for Apache Flink, highlighting its evolution from Stratosphere to a unified framework for batch and stream processing. It emphasizes the importance of integrating real-time data streaming with various user profiles, production settings, and a strong open-source ecosystem. Key features discussed include robust data processing, hybrid runtime architecture, and advanced streaming capabilities to enhance adoption and functionality.























































































