Downloaded 28 times


















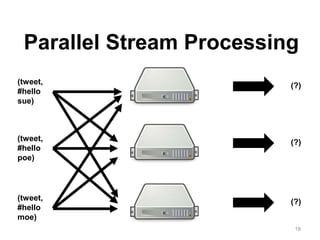
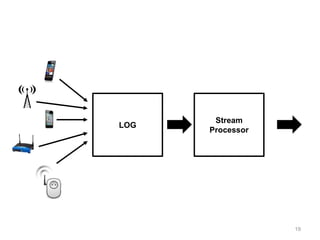
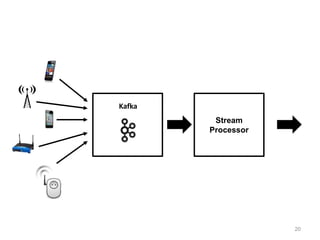
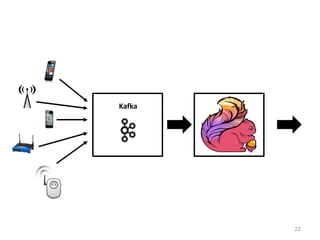

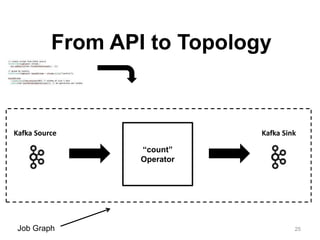
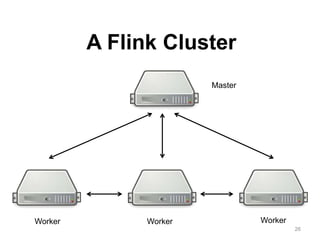
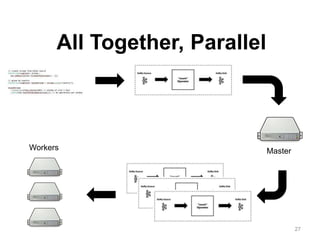
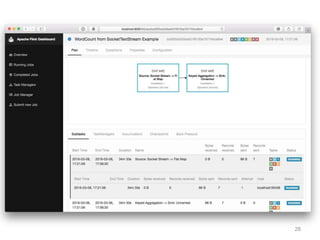


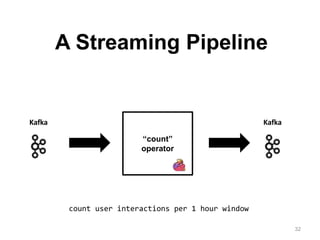
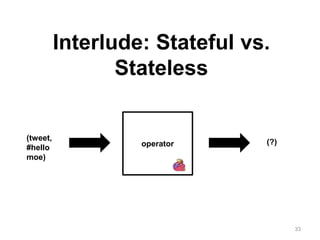
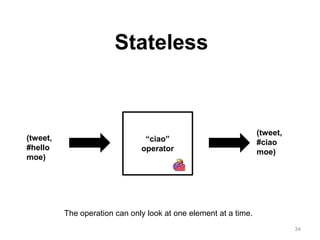
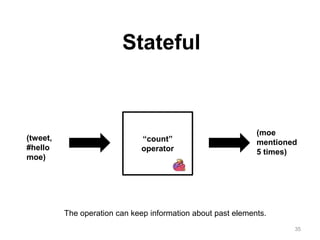
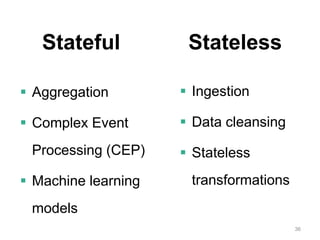

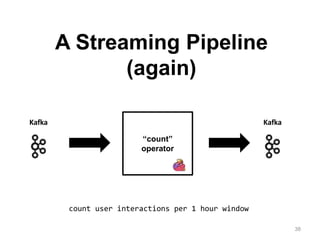


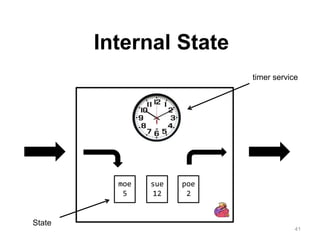
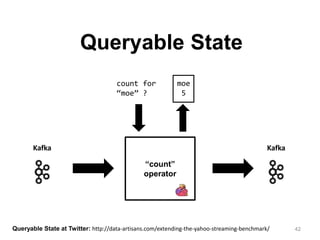
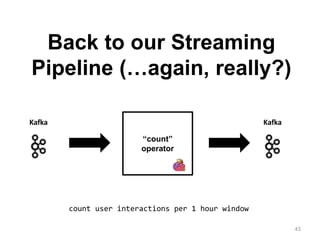



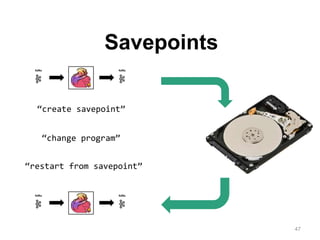











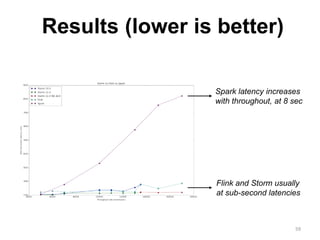

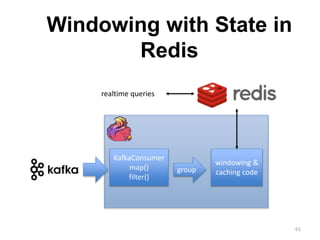
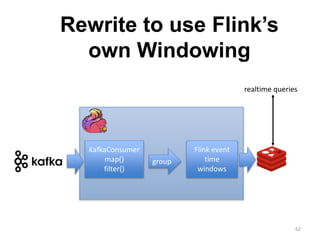
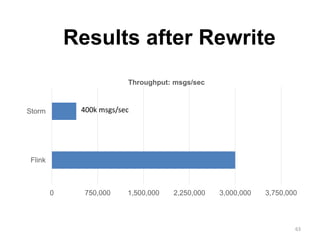
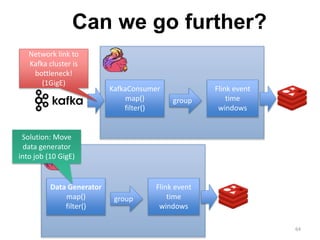





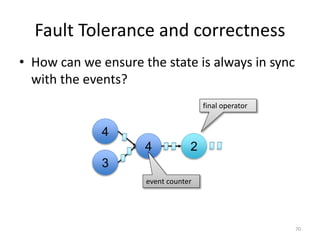
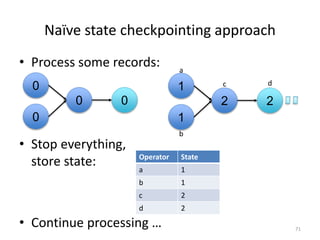
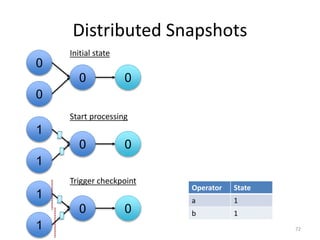
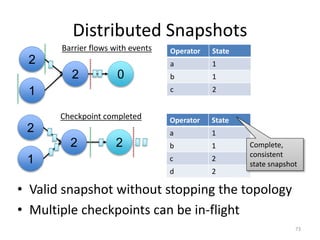

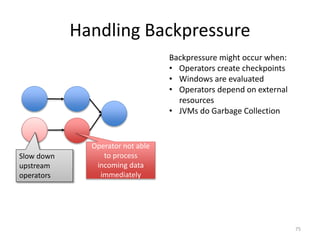
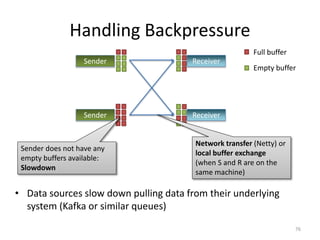
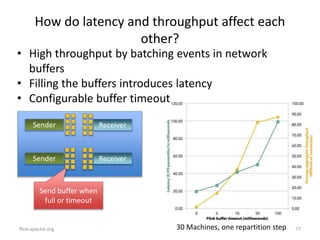
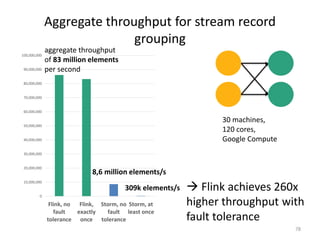
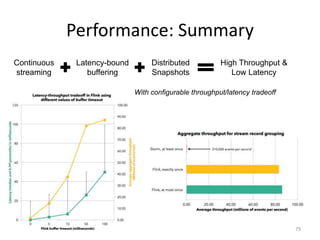
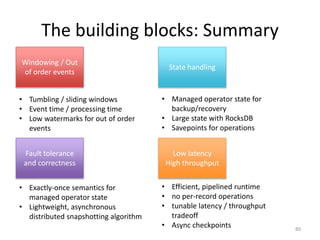
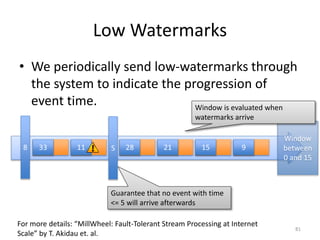
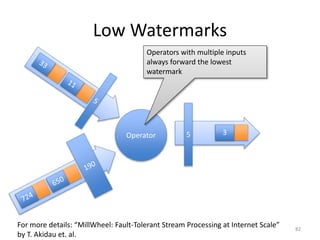

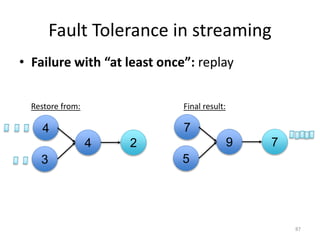
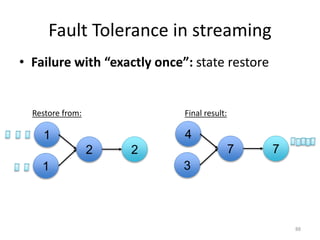
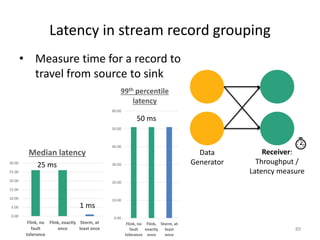

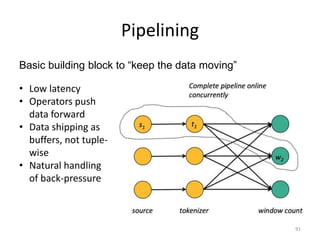

The document discusses Apache Flink, a next-generation stream processor, and its capabilities in stream processing, including stateful and stateless operations. It highlights Flink's unique features such as querying state information, handling backpressure, and high throughput performance compared to other streaming engines. The content also covers future enhancements planned for Flink and its community-driven development model.
















































































