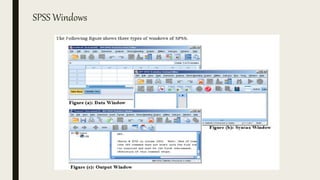
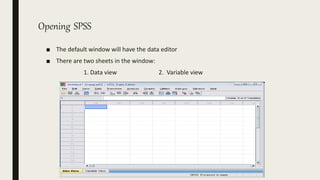
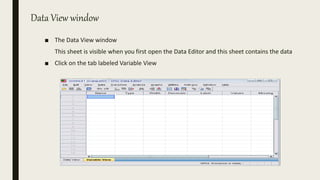
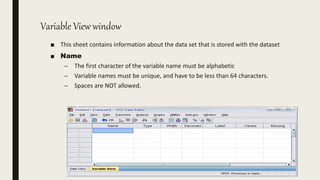
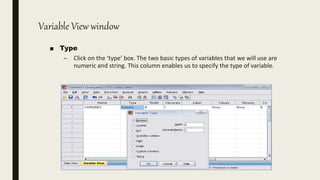
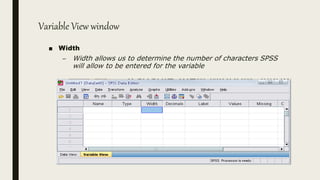
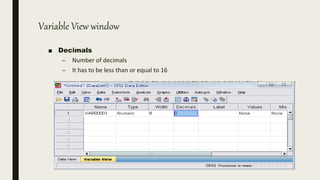
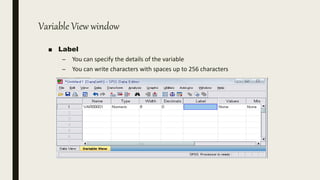
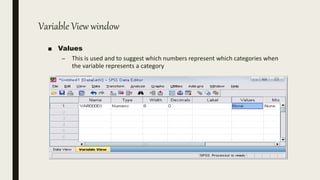
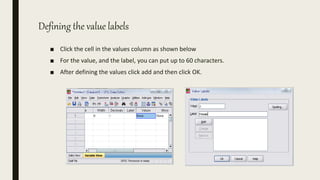
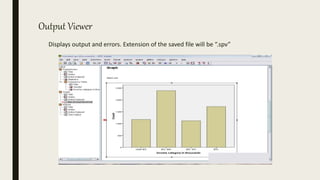
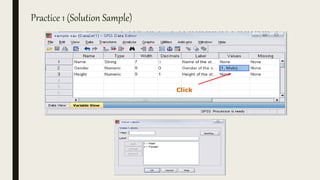
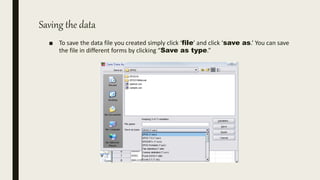
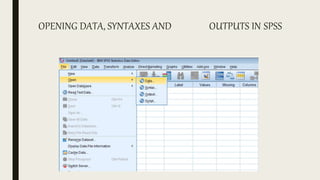
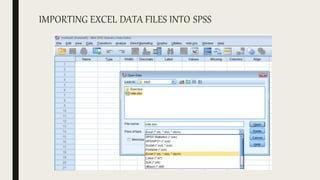
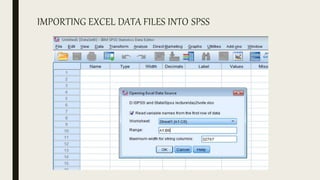
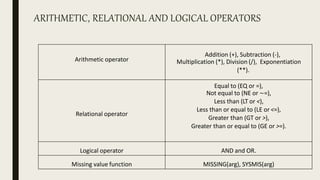
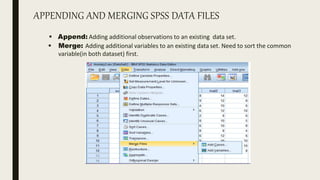
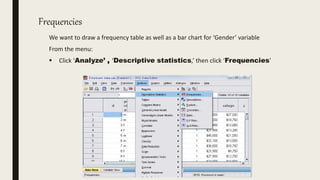
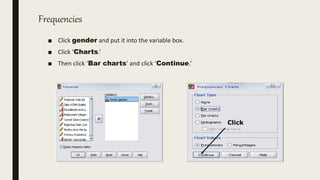
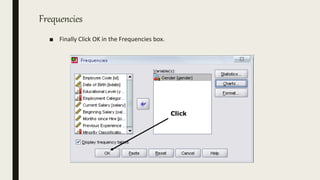
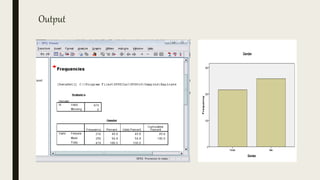
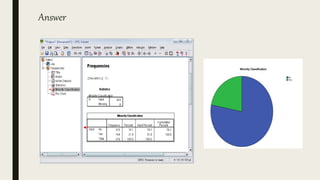
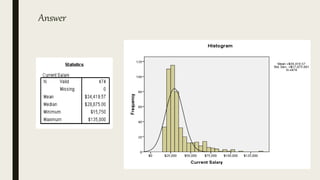
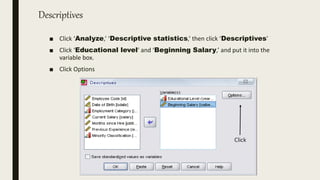
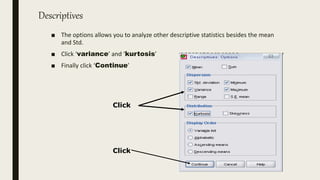
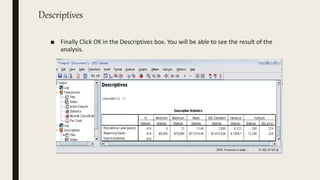
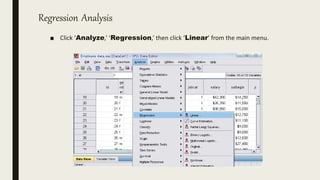
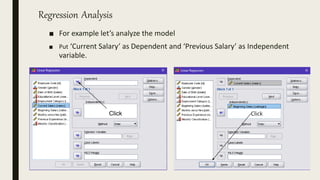
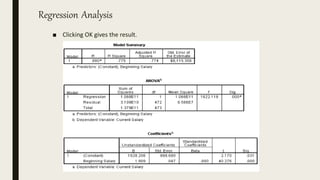
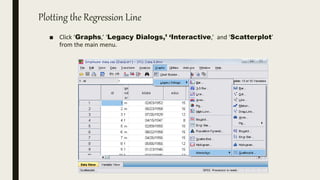
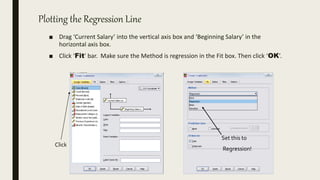
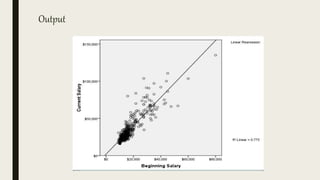
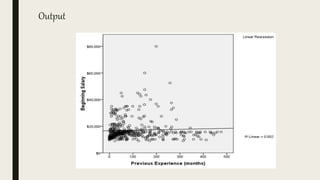
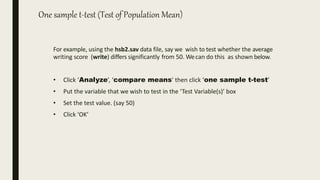
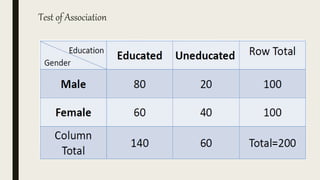
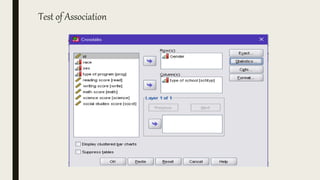
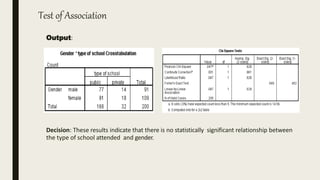
This document serves as an introductory guide to SPSS, a statistical software package used for data analysis, developed in 1968 and acquired by IBM in 2009. It covers essential topics such as data management, basic analysis, hypothesis testing, and provides practical examples for using SPSS functionalities, including variable naming rules and common statistical tests. The document aims to familiarize users with navigating SPSS and performing various analyses effectively.