Download as PDF, PPTX









![Insertion Sort
Statement Running Time of Each Step
InsertionSort (A, n) {
for i = 2 to n { c1n
key = A[i] c2(n-1)
j = i - 1; c3(n-1)
while (j > 0) and (A[j] > key) { c4T
A[j+1] = A[j] c5(T-(n-1))
j = j - 1 c6(T-(n-1))
} 0
A[j+1] = key c7(n-1)
} 0
}
T = t2 + t3 + … + tn where ti is number of while expression evaluations for the ith for loop iteration
12Ramakant Soni, Asst. Professor, CS Dept., BKBIET Pilani](https://image.slidesharecdn.com/algo06-sept-2016-160907051036/85/What-is-Algorithm-An-Overview-12-320.jpg)



![MERGE (A, left, mid, right )
1. n1 ← mid − left + 1
2. n2 ← right − mid
3. Create arrays L[1 . . n1 + 1] and R[1 . . n2 + 1]
4. FOR i ← 1 TO n1
5. DO L[i] ← A[left + i − 1]
6. FOR j ← 1 TO n2
7. DO R[j] ← A[mid + j ]
8. L[n1 + 1] ← ∞
9. R[n2 + 1] ← ∞
10. i ← 1
11. j ← 1
12. FOR k ← left TO right
13. DO IF L[i ] ≤ R[ j]
14. THEN A[k] ← L[i]
15. i ← i + 1
16. ELSE A[k] ← R[j]
17. j ← j + 1
Merge Sort
Source: http://www.personal.kent.edu
16Ramakant Soni, Asst. Professor, CS Dept., BKBIET Pilani](https://image.slidesharecdn.com/algo06-sept-2016-160907051036/85/What-is-Algorithm-An-Overview-16-320.jpg)



![Quick Sort
Quicksort(A, p, r)
{ if (p < r)
{ q = Partition(A, p, r);
Quicksort(A, p, q);
Quicksort(A, q+1, r);
}
}
Another divide-and-conquer algorithm
• The array A[p .. r] is partitioned into two non-empty subarrays A[p .. q] and A[q+1 ..r]
Invariant: All elements in A[p .. q] are less than all elements in A[q+1..r]
• The subarrays are recursively sorted by calls to quicksort
Unlike merge sort, no combining step: two subarrays form an already-sorted array
Actions that takes place in the partition() function:
• Rearranges the subarray in place
• End result:
• Two subarrays
• All values in first subarray all values in second
• Returns the index of the “pivot” element separating the two subarrays
20Ramakant Soni, Asst. Professor, CS Dept., BKBIET Pilani](https://image.slidesharecdn.com/algo06-sept-2016-160907051036/85/What-is-Algorithm-An-Overview-20-320.jpg)


![Linear Search
23Ramakant Soni, Asst. Professor, CS Dept., BKBIET Pilani
function find_Index (array, target)
{
for(var i = 0; i < array.length; ++i)
{
if (array[i] == target)
{
return i;
}
}
return -1;
}
• A linear search searches an element or value from an array till the
desired element or value is not found and it searches in a
sequence order.
• It compares the element with all the other elements given in the
list and if the element is matched it returns the value index else it
return -1.
• Running Time: T(n)= a(n-1) + b
Example: Search 5 in given data 5](https://image.slidesharecdn.com/algo06-sept-2016-160907051036/85/What-is-Algorithm-An-Overview-23-320.jpg)
![Binary Search
24Ramakant Soni, Asst. Professor, CS Dept., BKBIET Pilani
binary_search(A, low, high)
low = 1, high = size(A)
while low <= high
mid = floor(low + (high-low)/2)
if target == A[mid]
return mid
else if target < A[mid]
binary_search(A, low, mid-1)
else
binary_search(A, mid+1, high)
else
“target was not found”
Binary Search is an instance of divide-and-conquer paradigm.
Given an ordered array of n elements, the basic idea of binary search
is that for a given element we "probe" the middle element of the
array.
We continue in either the lower or upper segment of the array,
depending on the outcome of the probe until we reached the
required (given) element.
Complexity Analysis:
Binary Search can be accomplished in logarithmic time in the worst
case , i.e., T(n) = θ(log n).](https://image.slidesharecdn.com/algo06-sept-2016-160907051036/85/What-is-Algorithm-An-Overview-24-320.jpg)

![Algorithm to check Palindrome
26Ramakant Soni, Asst. Professor, CS Dept., BKBIET Pilani
A palindrome is a word, phrase, number, or other sequence of characters which reads the same backward or
forward.
function isPalindrome (text)
if text is null
return false
left ← 0
right ← text.length - 1
while (left < right)
if text[left] is not text[right]
return false
left ← left + 1
right ← right - 1
return true
Complexity:
The first function isPalindrome has a time
complexity of O(n/2) which is equal to O(n)
Palindrome Example:
CIVIC
LEVEL
RADAR
RACECAR
MOM](https://image.slidesharecdn.com/algo06-sept-2016-160907051036/85/What-is-Algorithm-An-Overview-26-320.jpg)

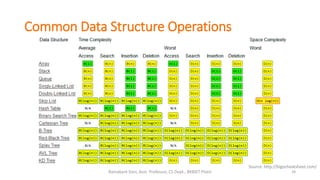



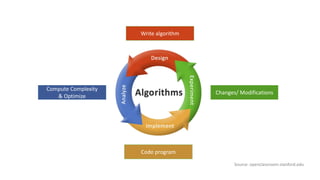
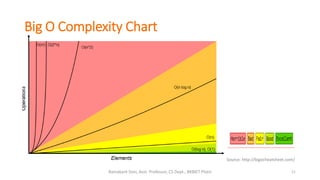
The document provides an introduction to algorithms, including definitions, examples, and applications across various fields such as travel routing, disease curing, and programming. It covers algorithm analysis, including time and space complexity, and details specific algorithms like insertion sort, merge sort, quick sort, linear search, and binary search. Additionally, it discusses asymptotic notations and the master theorem for analyzing divide-and-conquer algorithms.



































![Use case specification dan activity diagram [INTERNAL EDUCATIONAL PURPOSED]](https://cdn.slidesharecdn.com/ss_thumbnails/usecasespecificationdanactivitydiagrama06sikursus-170326115038-thumbnail.jpg?width=640&height=640&fit=bounds)















































