Downloaded 18 times







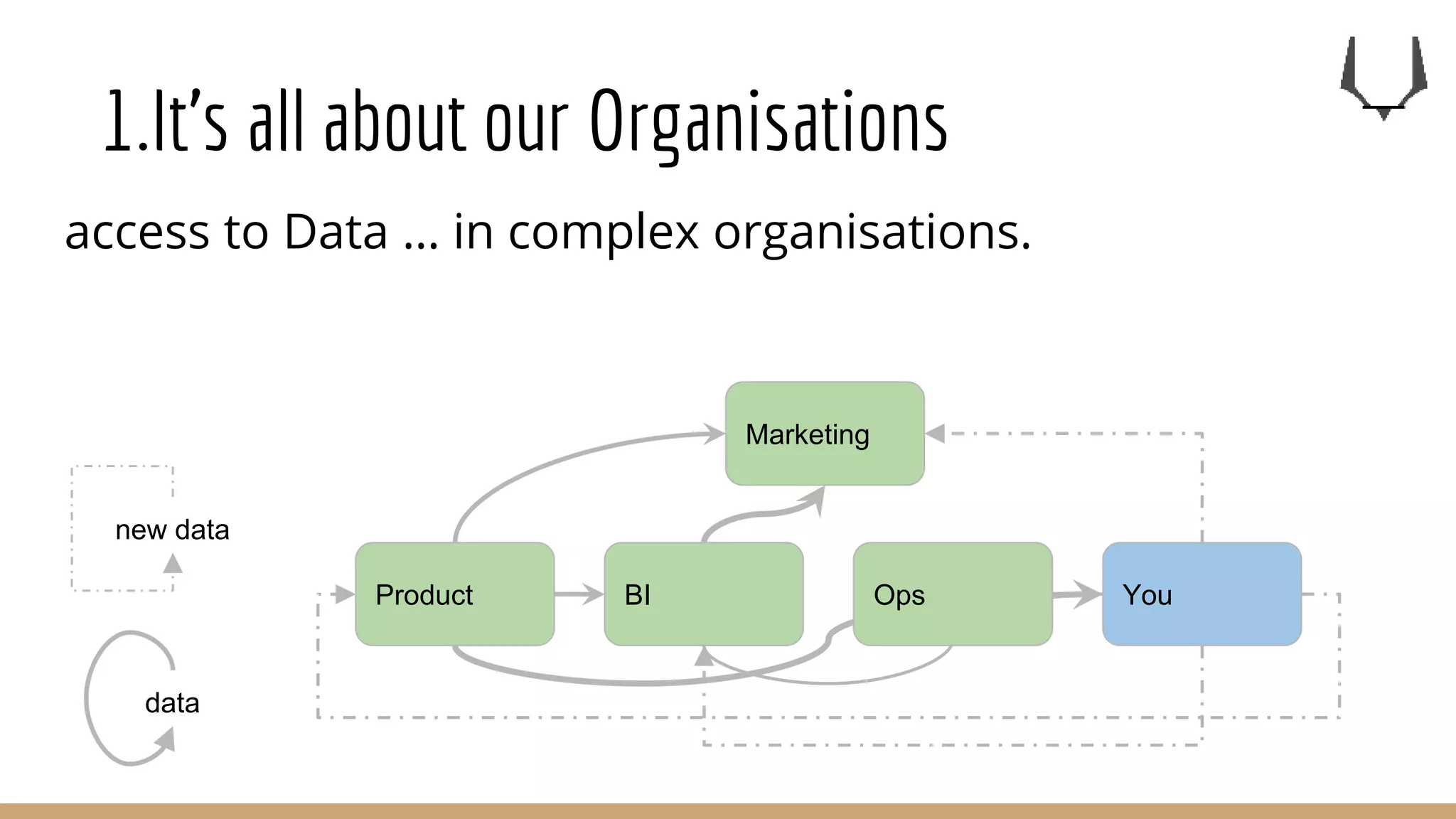
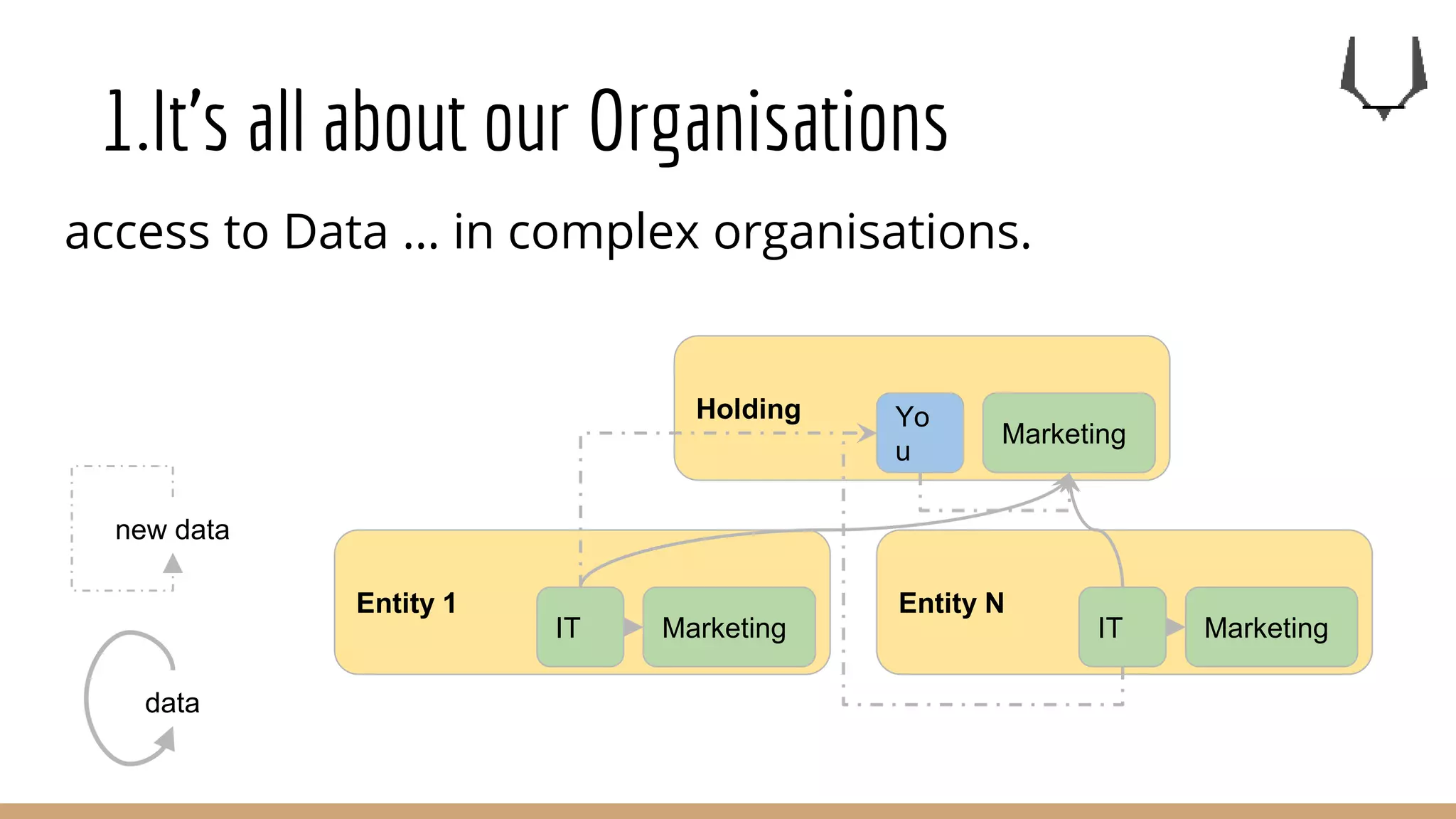
![1.It’s all about our Organisations
Data engineering is not a support
function
for Data Scientists[1].
[1] whatever they are nowadays](https://image.slidesharecdn.com/7keyrecipesfor0bdataengineering-161223164715/75/7-key-recipes-for-data-engineering-8-2048.jpg)
















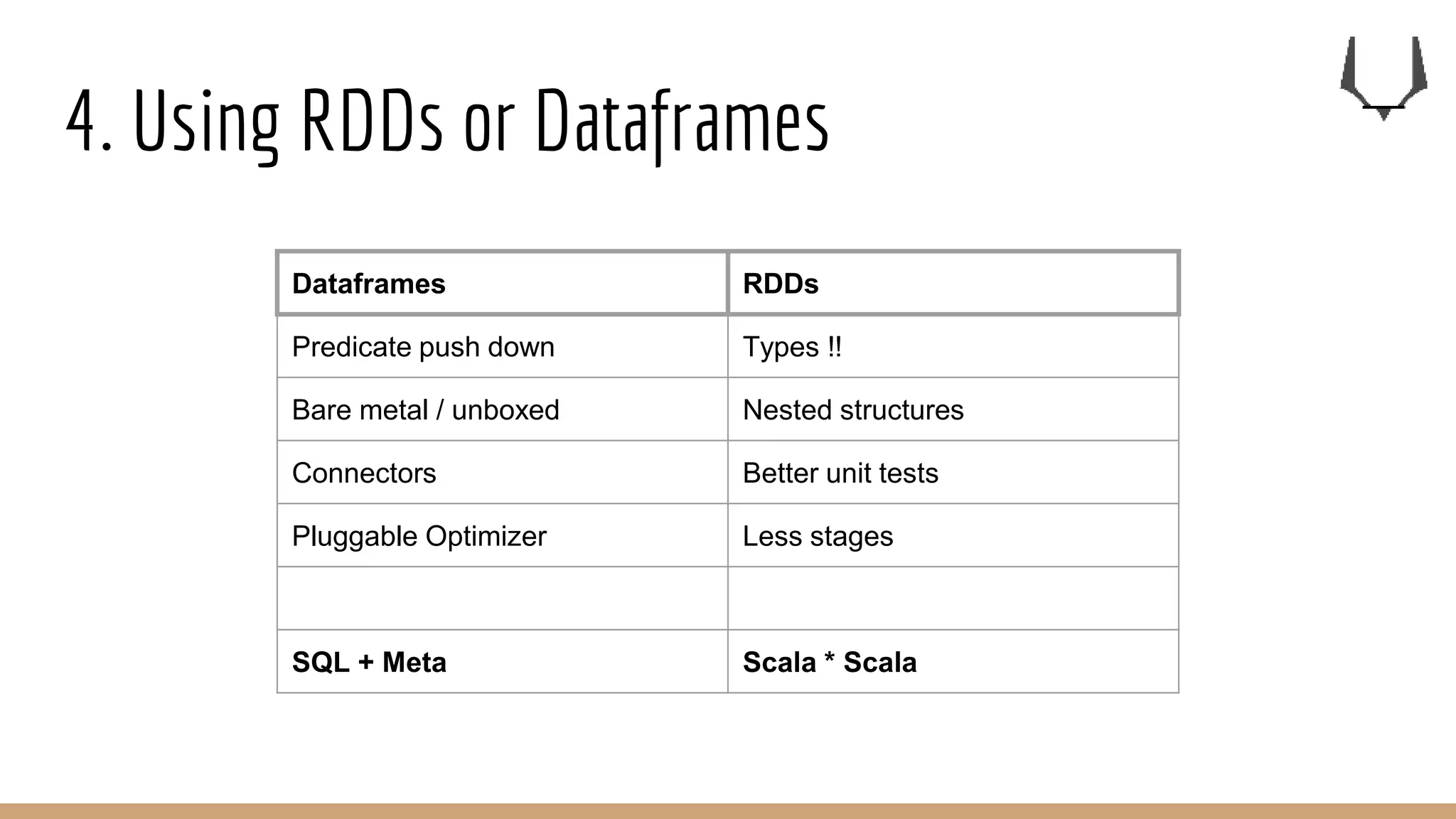





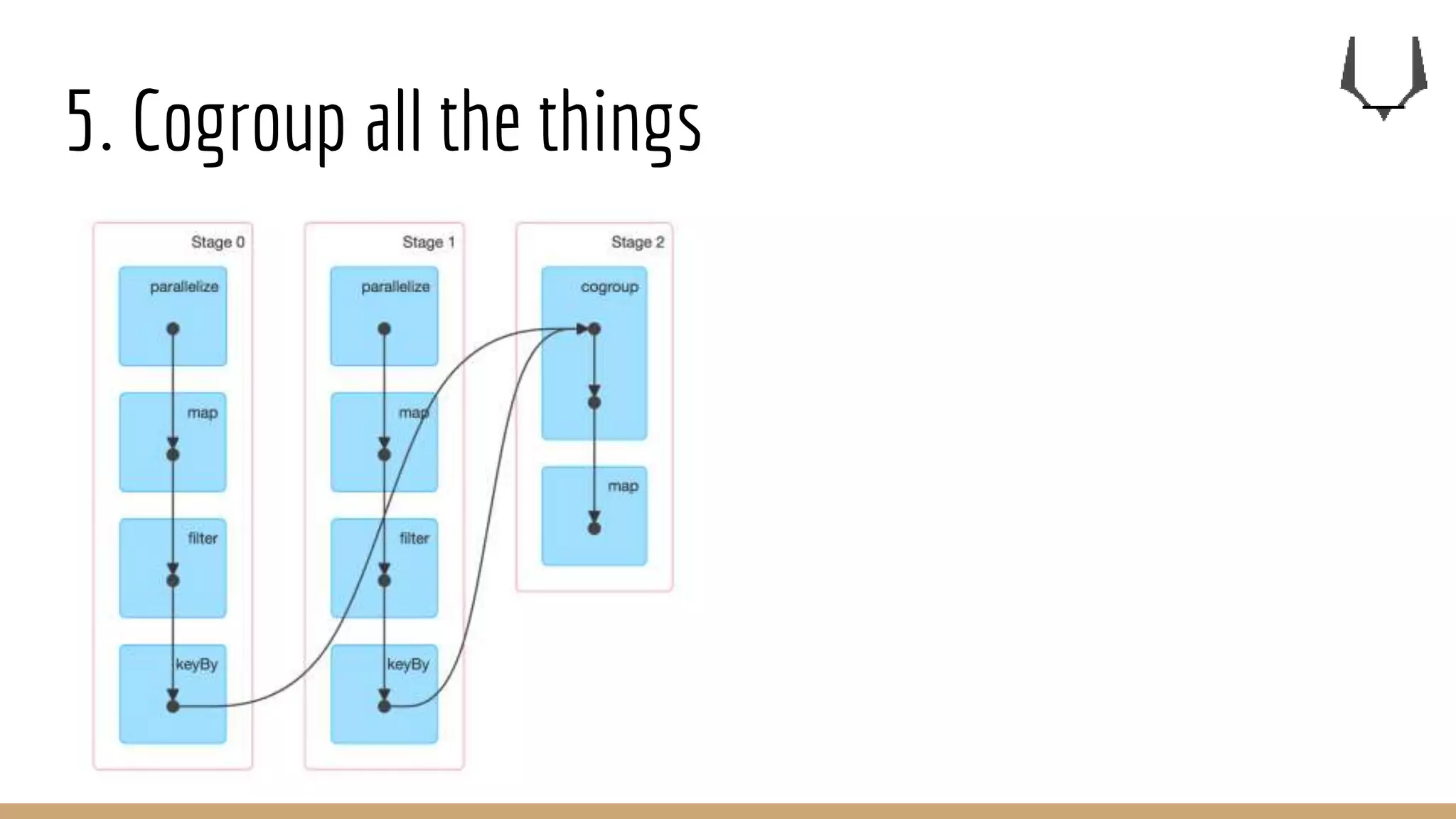
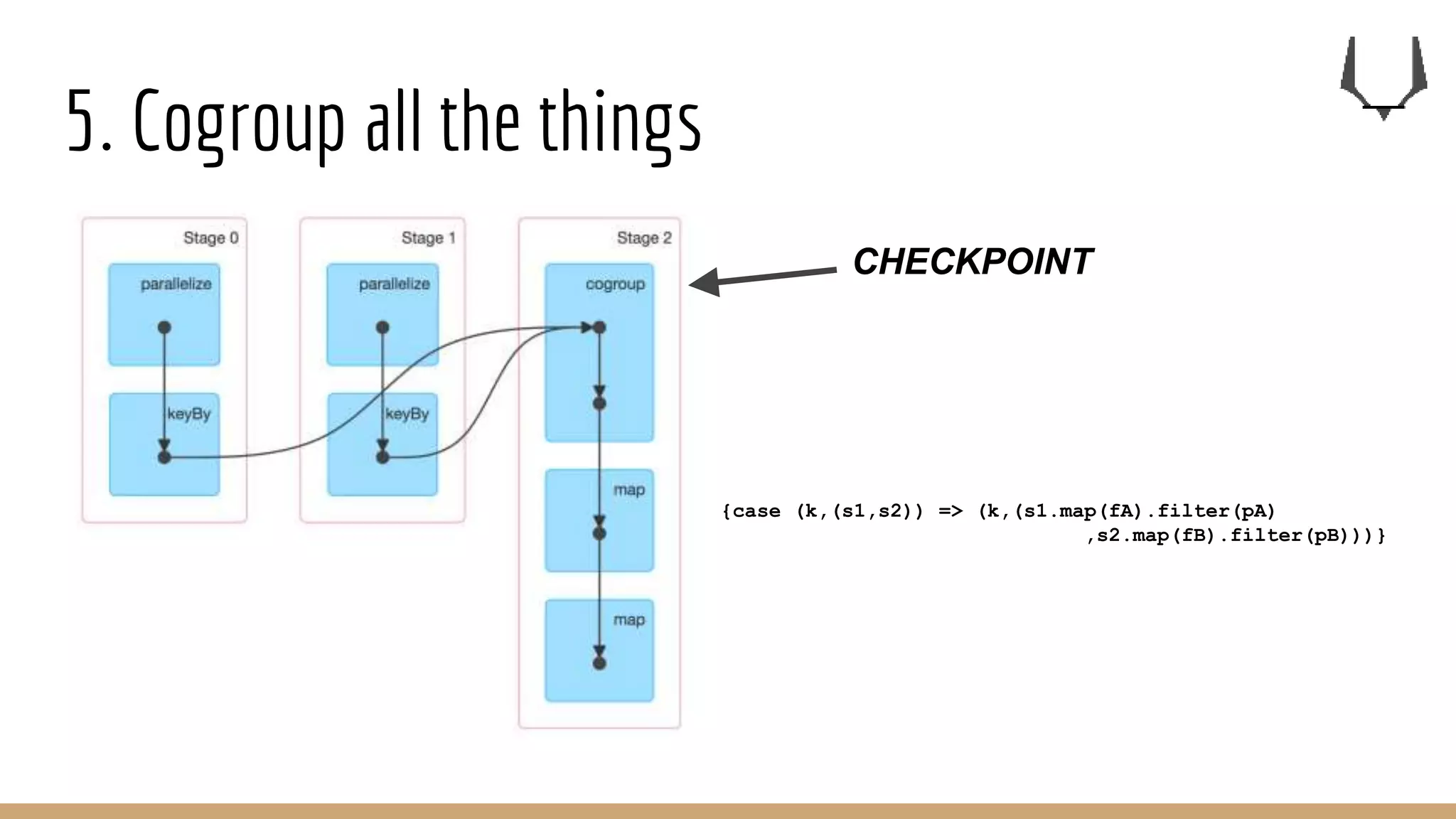
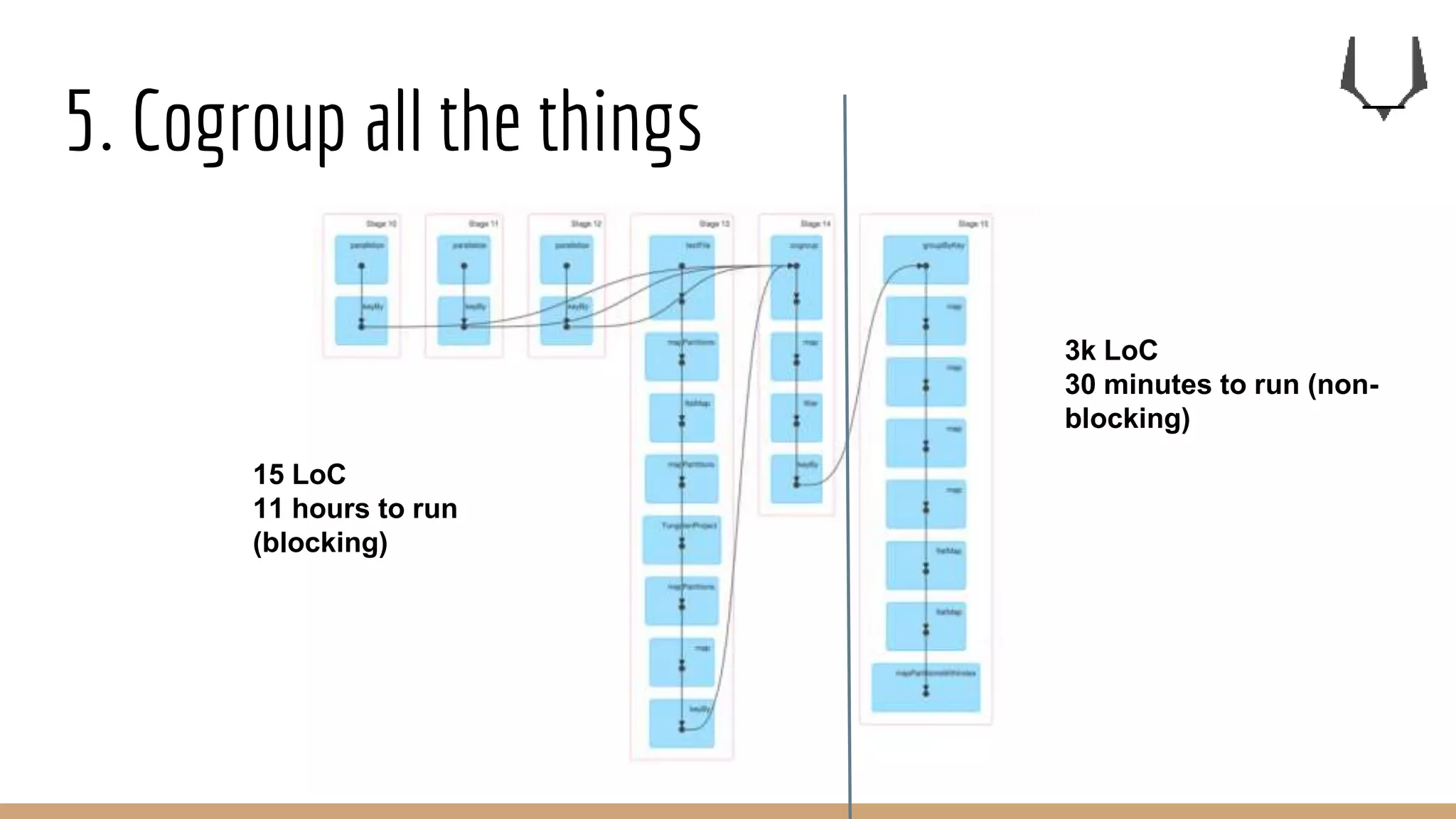
![5. Cogroup all the things
join (left:RDD[(K,A)],right:RDD[(K,B)]):RDD[(K,( A , B ))]
leftJoin (left:RDD[(K,A)],right:RDD[(K,B)]):RDD[(K,( A ,Option[B]))]
rightJoin (left:RDD[(K,A)],right:RDD[(K,B)]):RDD[(K,(Option[A], B) )]
outerJoin (left:RDD[(K,A)],right:RDD[(K,B)]):RDD[(K,(Option[A],Option[B]))]
cogroup (left:RDD[(K,A)],right:RDD[(K,B)]):RDD[(K,( Seq[A], Seq[B]))]
groupBy (rdd:RDD[(K,A)]):RDD[(K,Seq[A])]
On cogroup and groupBy, for a given key:K, there is only one
unique row with that key in the output dataset.](https://image.slidesharecdn.com/7keyrecipesfor0bdataengineering-161223164715/75/7-key-recipes-for-data-engineering-33-2048.jpg)



![6. Inline data quality
case class FixeVisiteur(
devicetype: String,
isrobot: Boolean,
recherche_visitorid: String,
sessions: List[FixeSession]
) {
def recherches: List[FixeRecherche] = sessions.flatMap(_.recherches)
}
object FixeVisiteur {
@autoBuildResult
def build(
devicetype: Result[String],
isrobot: Result[Boolean],
recherche_visitorid: Result[String],
sessions: Result[List[FixeSession]]
): Result[FixeVisiteur] = MacroMarker.generated_applicative
}
Example :](https://image.slidesharecdn.com/7keyrecipesfor0bdataengineering-161223164715/75/7-key-recipes-for-data-engineering-40-2048.jpg)
![6. Inline data quality
case class Annotation(
anchor: Anchor,
message: String,
badData: Option[String],
expectedData: List[String],
remainingData: List[String],
level: String @@ AnnotationLevel,
annotationId: Option[AnnotationId],
stage: String
)
case class Anchor(path: String @@ AnchorPath,
typeName: String)](https://image.slidesharecdn.com/7keyrecipesfor0bdataengineering-161223164715/75/7-key-recipes-for-data-engineering-41-2048.jpg)

![6. Inline data quality
Data quality is available within the output rows.
case class HVisiteur(
visitorId: String,
atVisitorId: Option[String],
isRobot: Boolean,
typeClient: String @@ TypeClient,
typeSupport: String @@ TypeSupport,
typeSource: String @@ TypeSource,
hVisiteurPlus: Option[HVisiteurPlus],
sessions: List[HSession],
annotations: Seq[HAnnotation]
)](https://image.slidesharecdn.com/7keyrecipesfor0bdataengineering-161223164715/75/7-key-recipes-for-data-engineering-43-2048.jpg)









The document outlines seven key recipes for data engineering, emphasizing that it is crucial for organizational data access rather than solely supporting data scientists. It discusses optimization practices, staging of data, the use of RDDs versus DataFrames, and the importance of data quality and creating resilient data pipelines. Jonathan Winandy shares insights and tips gathered from his expertise and experiences in the field.































































































