
![Hello Steven Noels Outerthought scalable content apps Lily repository smart data, at scale, made easy HBase / SOLR NoSQLSummer @stevenn [email_address] Wim Van Leuven Lives software, applications and development group dynamics Cloud and BigData enthusiast wannabe entrepreneur using all of the above @wimvanleuven [email_address]](https://image.slidesharecdn.com/bigdatasai-110404060700-phpapp01/85/Big-Data-2-320.jpg)









































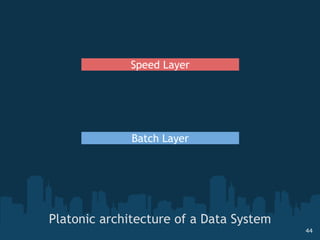


















The document discusses the challenges and opportunities presented by big data, highlighting the massive projected growth of data volumes and the need for innovative data systems. It introduces concepts such as NoSQL databases and the CAP theorem, while emphasizing the importance of real-time analytics and scalable architectures to effectively manage and utilize data. The text concludes with observations on the evolving landscape of data technologies and the significance of community-driven knowledge sharing in the big data ecosystem.








































































































