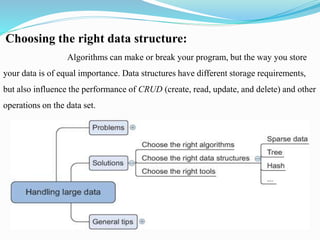
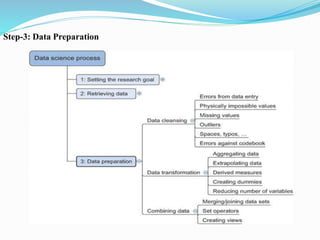
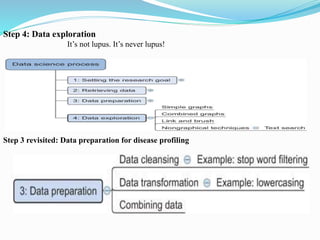
The document discusses the challenges of handling large data sets, including memory overload and the importance of selecting appropriate algorithms and data structures. It explores techniques for efficient data processing, such as using frameworks like Hadoop and Spark, as well as comparing relational and NoSQL databases. Additionally, it presents case studies demonstrating data analysis and modeling techniques in real-world scenarios.

























![Step 4 revisited: Data exploration for disease profiling
searchBody={
"fields":["name"],
"query":{
"filtered" : {
"filter": {
'term': {'name':'diabetes'}
}
}
},
"aggregations" : {
"DiseaseKeywords" : {
"significant_terms" : { "field" : "fulltext", "size" : 30 }
},
"DiseaseBigrams": {
"significant_terms" : { "field" : "fulltext.shingles",
"size" : 30 }
}
}
}
client.search(index=indexName,doc_type=docType,
body=searchBody, from_ = 0, size=3)](https://image.slidesharecdn.com/handlinglargedataonasinglesystem-200224174857/85/data-science-chapter-4-5-6-28-320.jpg)

































![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)


































