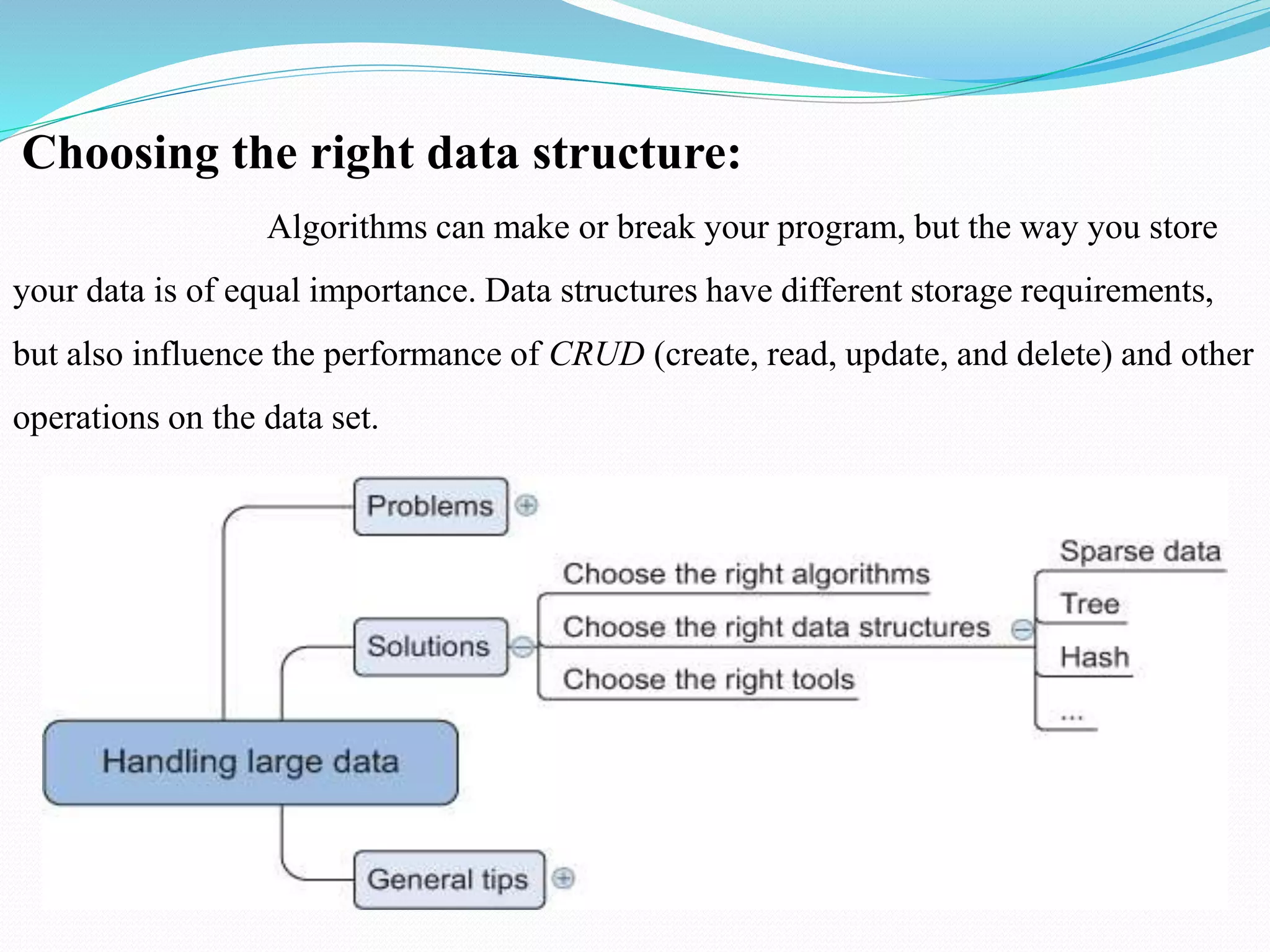
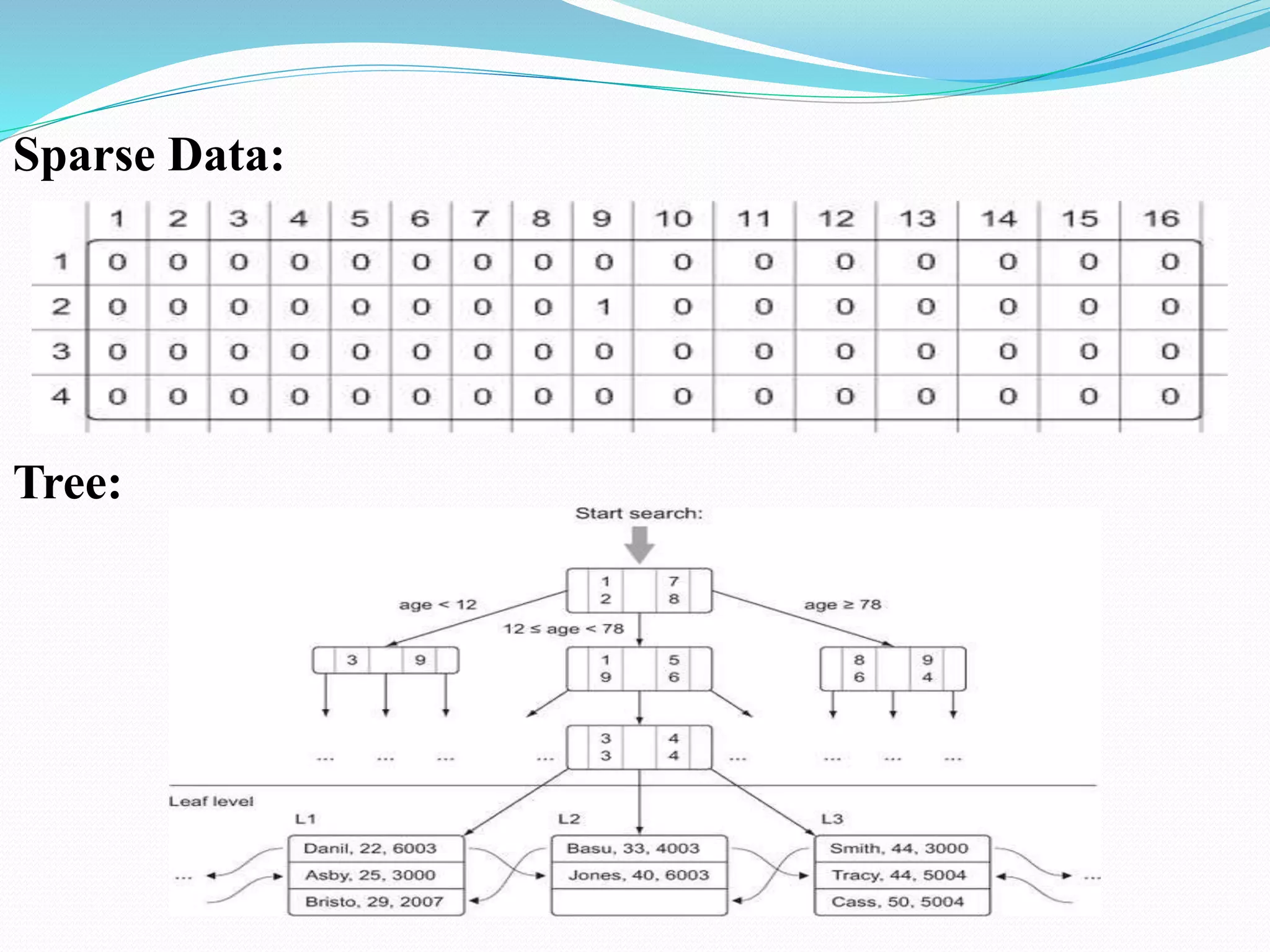
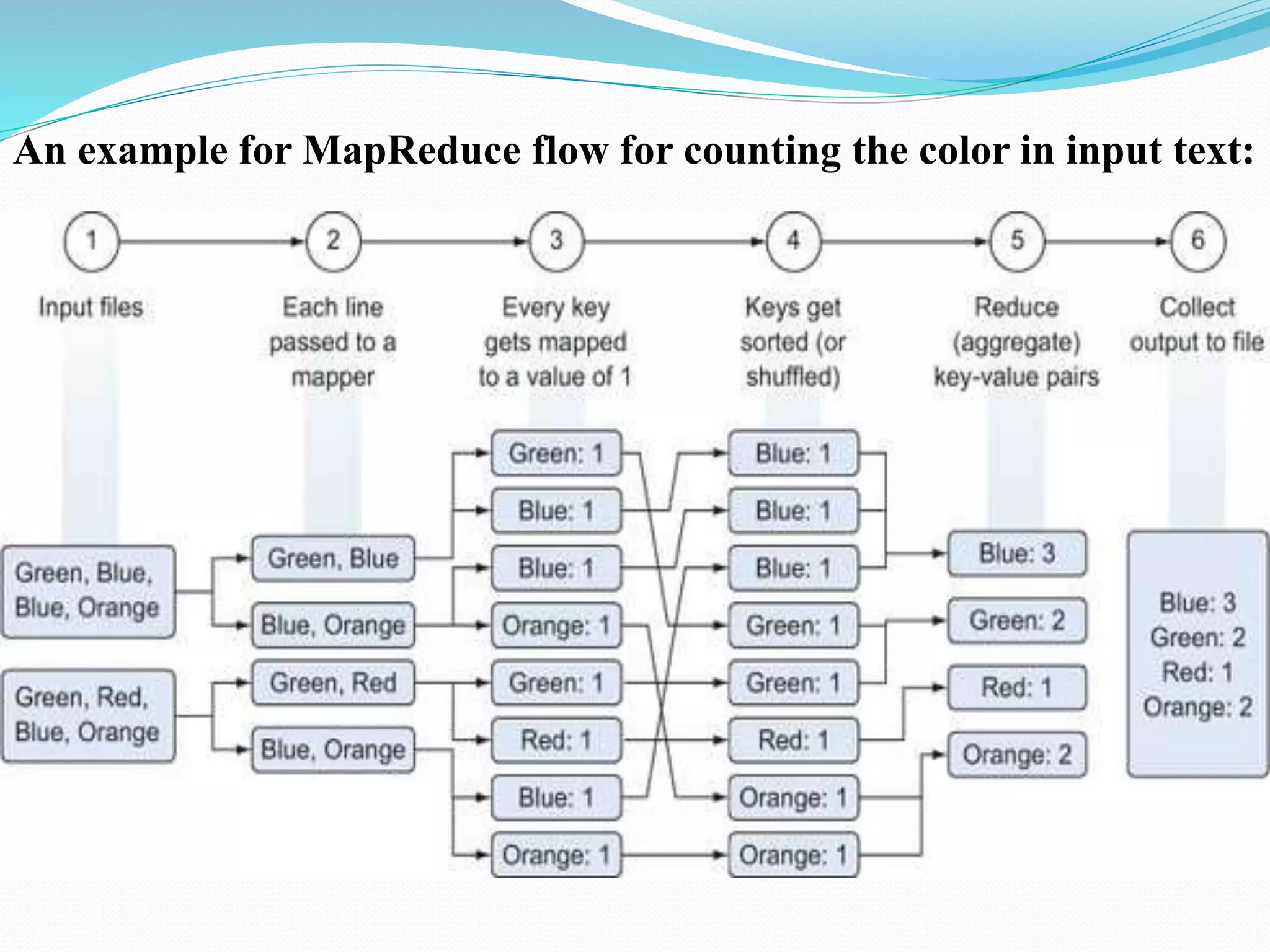
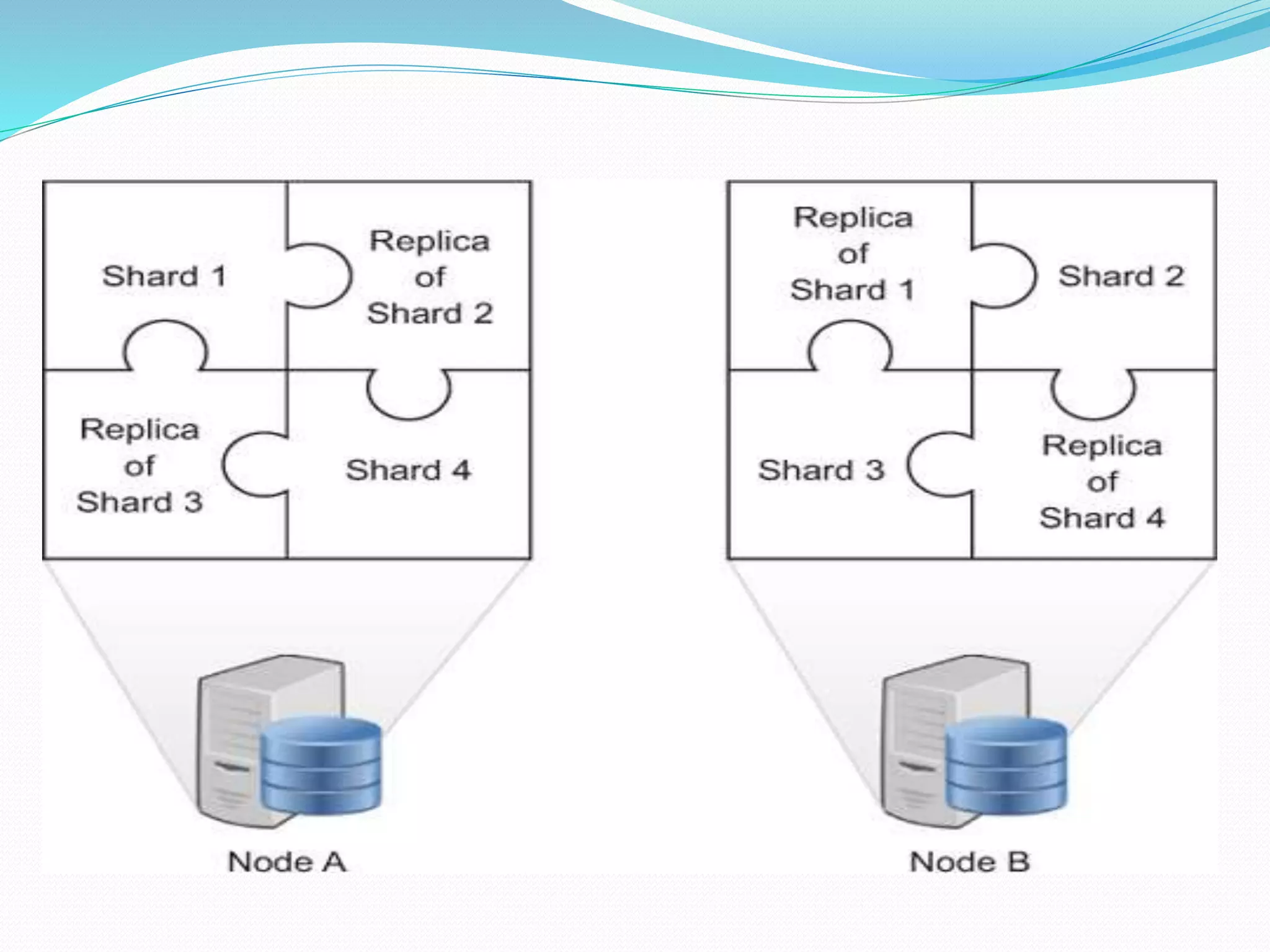
The document discusses challenges and solutions for handling large data sets, emphasizing the importance of selecting the right algorithms and data structures. It also presents case studies demonstrating practical applications, such as predicting malicious URLs and building a recommender system, while introducing big data technologies like Hadoop and Spark. Furthermore, it outlines the evolution towards NoSQL databases and the differences from traditional relational databases.























![Step 4 revisited: Data exploration for disease profiling
searchBody={
"fields":["name"],
"query":{
"filtered" : {
"filter": {
'term': {'name':'diabetes'}
}
}
},
"aggregations" : {
"DiseaseKeywords" : {
"significant_terms" : { "field" : "fulltext", "size" : 30 }
},
"DiseaseBigrams": {
"significant_terms" : { "field" : "fulltext.shingles",
"size" : 30 }
}
}
}
client.search(index=indexName,doc_type=docType,
body=searchBody, from_ = 0, size=3)](https://image.slidesharecdn.com/datascienceunit2-200227174411/75/Data-science-unit2-29-2048.jpg)













































![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)






















