Downloaded 49 times



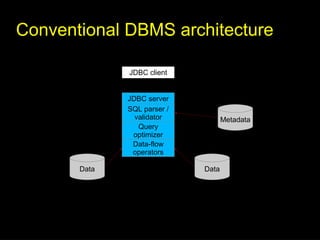

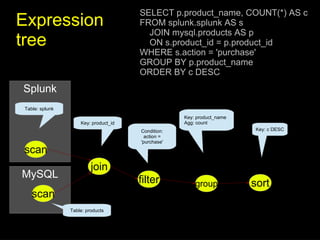




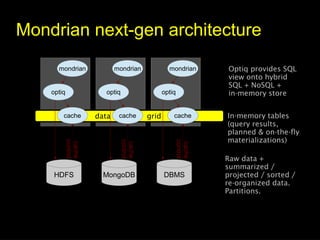



The document discusses 'SQL on Big Data' with a focus on technologies such as Optiq, Apache Drill, and Cascading, emphasizing their capabilities for querying large datasets and supporting distributed data processing. It highlights the evolution and challenges of big data management, mentioning the need for efficient data querying while maintaining flexibility and scaling ability. The presentation covers various architecture components and optimization techniques for integrating SQL with big data systems.























































































