Download as PDF, PPTX
















![tail
insert
event
buffering
127.0.0.1 - - [11/Dec/2012:07:26:27] "GET / ...
127.0.0.1 - - [11/Dec/2012:07:26:30] "GET / ...
127.0.0.1 - - [11/Dec/2012:07:26:32] "GET / ...
127.0.0.1 - - [11/Dec/2012:07:26:40] "GET / ...
127.0.0.1 - - [11/Dec/2012:07:27:01] "GET / ...
...
28
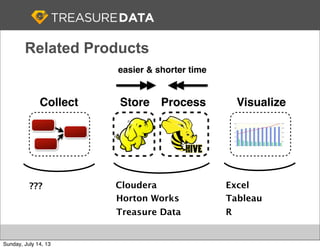
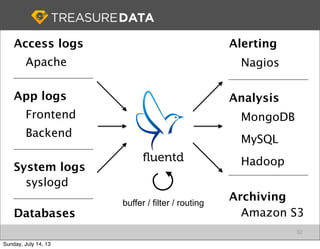
Fluentd
Web Server
Example (apache to monogdb)
2012-12-11 07:26:27
apache.log
{
"host": "127.0.0.1",
"method": "GET",
...
}
Sunday, July 14, 13](https://image.slidesharecdn.com/treasuredatacloudstrategy-130713234601-phpapp01/85/Treasure-Data-Cloud-Strategy-29-320.jpg)
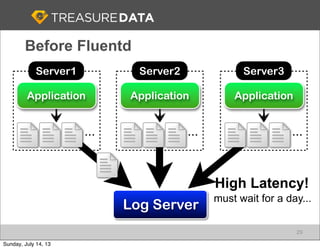
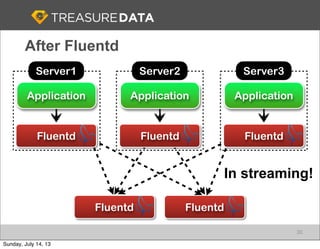
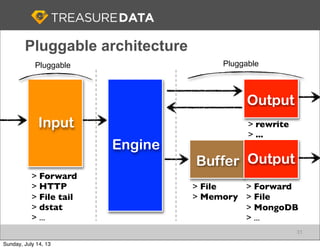


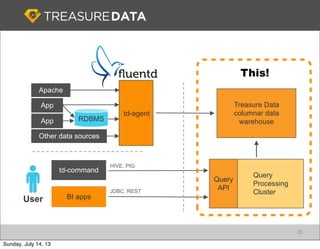


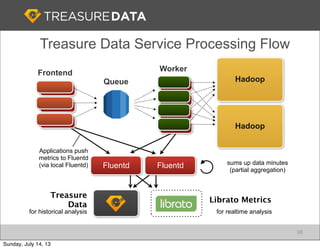
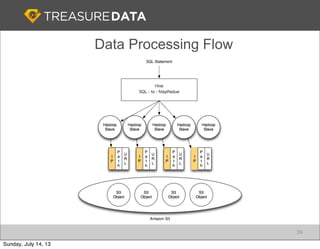
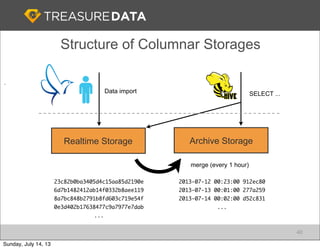
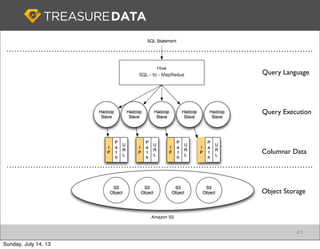
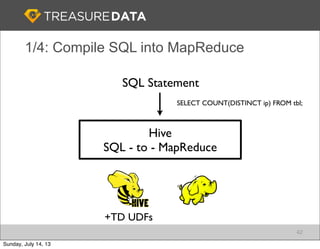
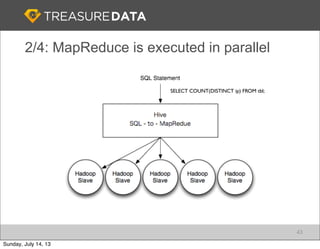
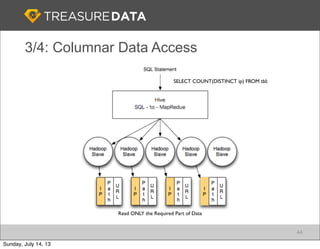
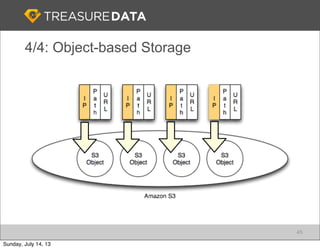
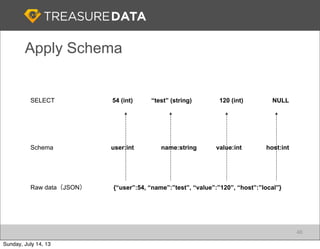
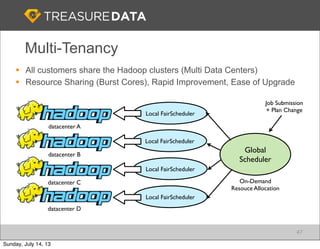
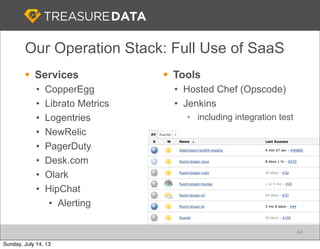
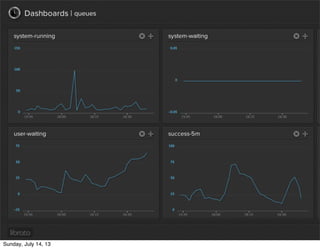
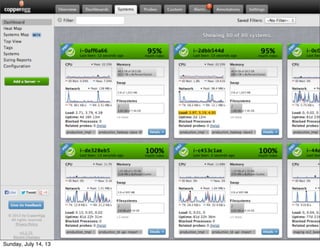
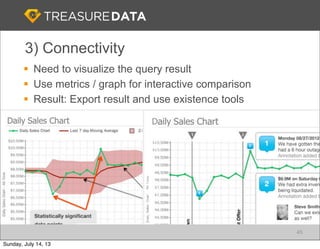
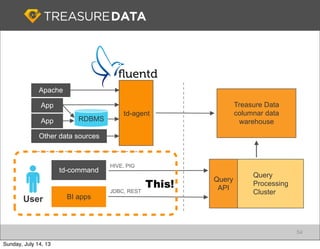
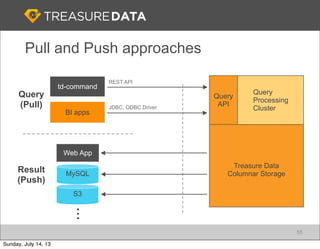




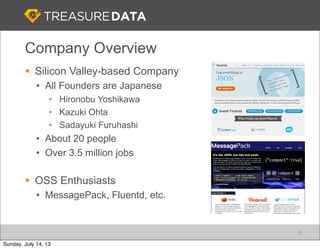
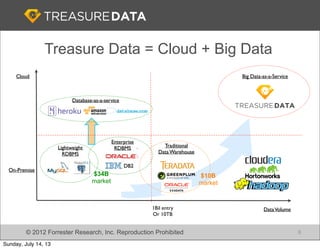
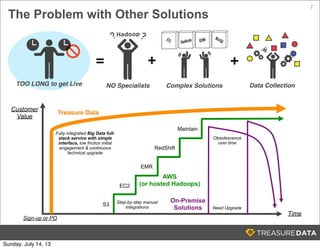
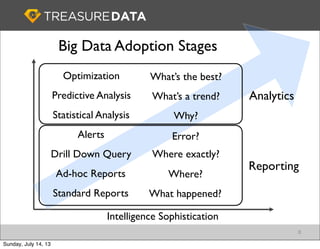
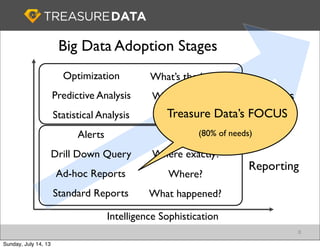
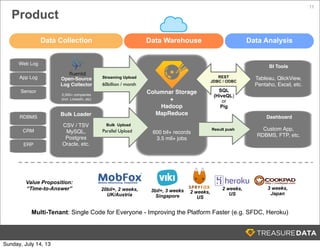
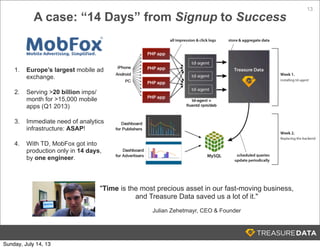
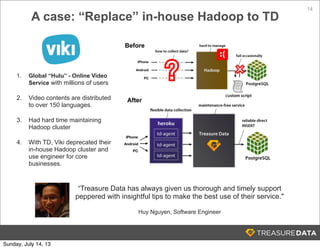
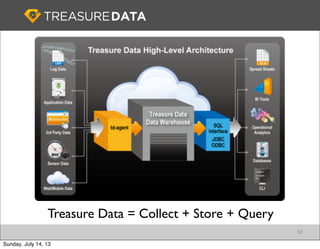
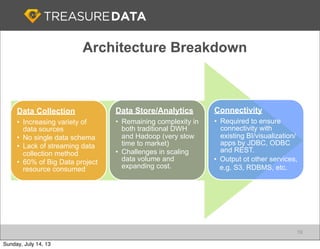
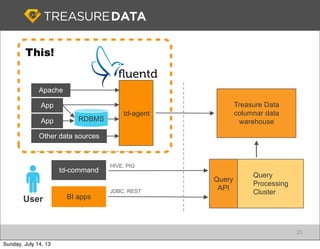
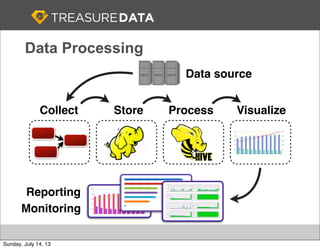
Treasure Data is a cloud-based big data analytics company based in Silicon Valley with about 20 employees. The document discusses Treasure Data's services and architecture, which includes collecting data from various sources using Fluentd, storing the data in a columnar format on AWS S3, and performing analytics using Hadoop and SQL queries. Treasure Data aims to simplify big data adoption through its fully-managed platform and quick setup process. Example customers discussed were able to see results within 2 weeks of signing up.

































![[D36] Michael Stonebrakerが生み出した列指向データベースは何が凄いのか? ~Verticaを例に列指向データベースのアーキテクチャ...](https://cdn.slidesharecdn.com/ss_thumbnails/d36verticakomori-131125025044-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Sapporo 2015] B16:ビッグデータには、なぜ列指向が有効なのか? by 日本ヒューレット・パッカード株式...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015b16bigdataverticahewletpackard-150918014205-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)







































































