Download as PDF, PPTX





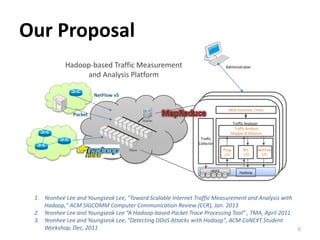











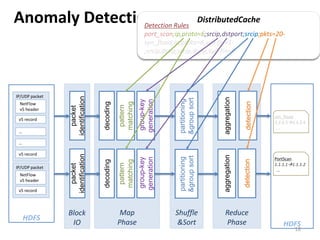

















This document summarizes a research paper on scalable NetFlow analysis using Hadoop. It discusses: 1) The challenges of analyzing large volumes of Internet traffic data, including scalability, fault tolerance, and extensibility. 2) How Hadoop can help address these challenges by providing distributed computing and storage capabilities to process petabytes of data across thousands of nodes. 3) The design of a Hadoop-based traffic processing tool for collecting, storing, and analyzing NetFlow and packet data at scale through MapReduce jobs.















































