Downloaded 84 times



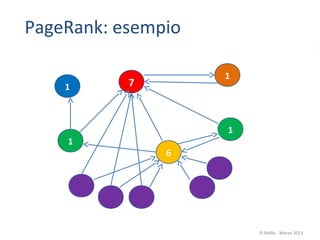
![Una visualizzazione [di una parte] del web
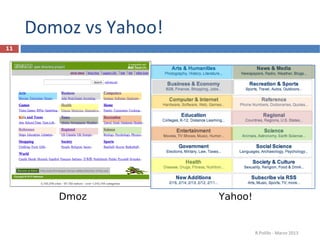
La immagine mostra una porzione di Internet costituita da 535.000 nodi e più di 600.000 links
WALRUS Visualization tool, 2001 http://www.caida.org/tools/visualization/walrus/
R.Polillo - Marzo 2013
3](https://image.slidesharecdn.com/6-ricerca-130323054716-phpapp02/85/6-Ricercare-nel-Web-3-320.jpg)
![4
R.Polillo - Marzo 2013
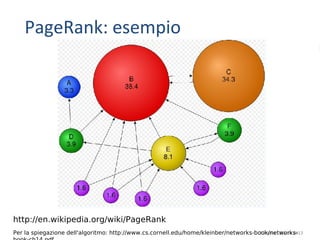
Una visualizzazione [di una parte] del web](https://image.slidesharecdn.com/6-ricerca-130323054716-phpapp02/85/6-Ricercare-nel-Web-4-320.jpg)
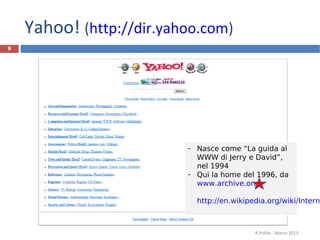
![R.Polillo - Marzo 2013
5
Una visualizzazione [di una parte] del web](https://image.slidesharecdn.com/6-ricerca-130323054716-phpapp02/85/6-Ricercare-nel-Web-5-320.jpg)
















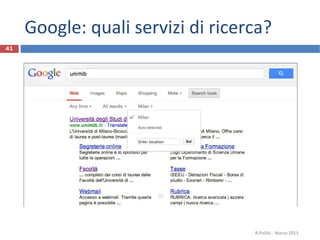






Il documento è il materiale di un corso universitario che affronta le tecniche di ricerca nel web, evidenziando strumenti come directory, motori di ricerca e sistemi di domande e risposte sociali. Viene discusso anche il concetto di serendipità nella scoperta di informazioni e vengono presentati i principali motori di ricerca, le loro funzioni e algoritmi come il PageRank di Google. Inoltre, si menzionano strategie di ottimizzazione per i motori di ricerca (SEO) e il marketing dei motori di ricerca (SEM).























































































