Download to read offline







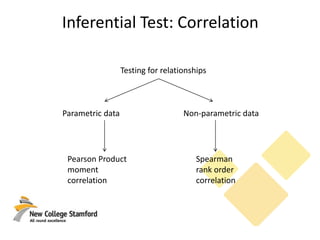






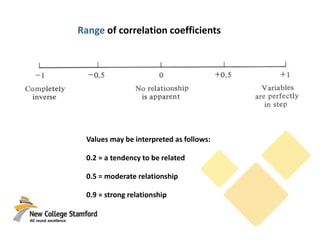
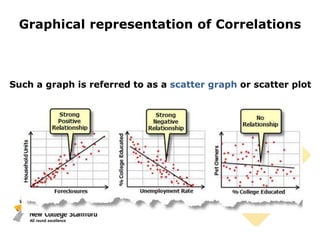



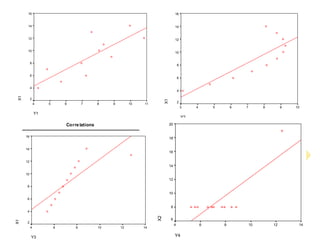

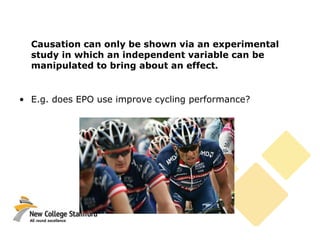








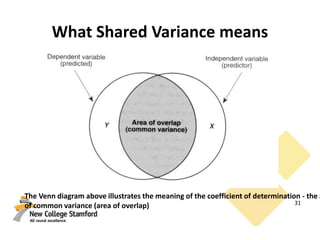




This document discusses correlations and inferential statistics. It explains that while science cannot prove relationships, statistics can determine the probability that two variables are related rather than due to chance. A correlation coefficient (r value) quantifies the strength of association between variables. Strong correlations near -1 or 1 indicate the variables are likely related, while values near 0 suggest no relationship. However, correlations do not prove causation - only experiments can do that. The document provides examples of interpreting correlation values and limitations like sample size effects on reliability.





































































































