Downloaded 153 times






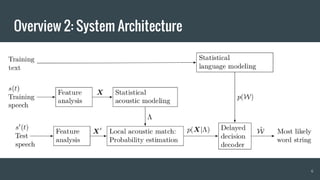
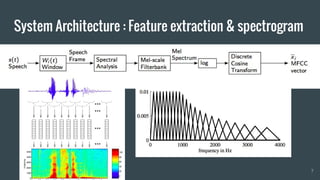
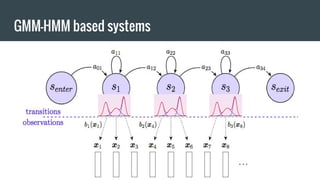

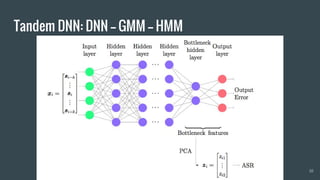
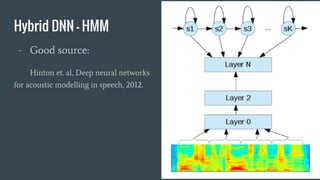
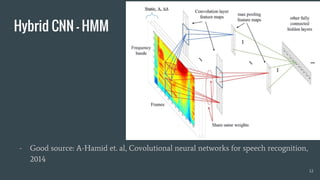
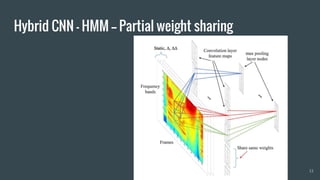
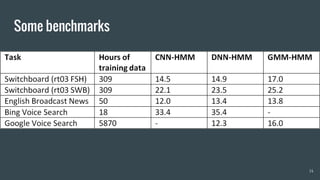
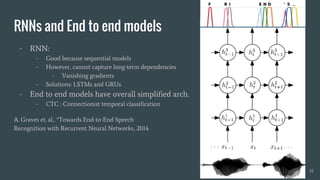



The document provides an overview of deep learning applications in speech recognition, detailing the evolution from conventional GMM-HMM systems to advanced deep neural networks like CNNs and RNNs/LSTMs. It discusses the challenges unique to speech data, the architecture of ASR systems, and innovative approaches such as end-to-end models. The conclusion highlights resources for further exploration and development in this field.























































































