18
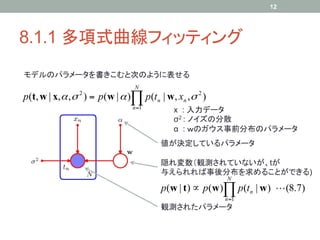
8.1.3 離散変数
• パラメータ数について議論
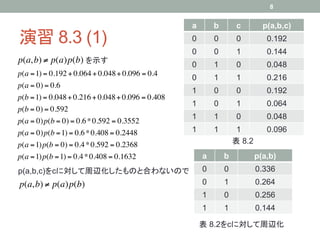
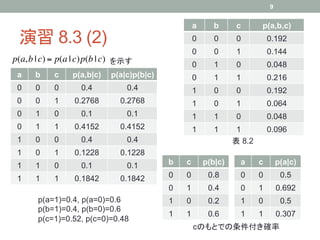
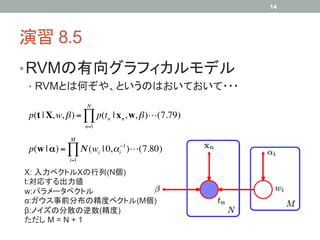
K個の状態をとりうる離散変数xの確率分布
K
p( x | µ) = ∏ µ kxk (8.9)
k =1 K-1個のパラメータ
2つのK状態離散変数x1及びx2がある場合
K K
p( x1 , x2 | µ) = ∏∏ µ kl1k x2 k
x
k =1 l =1 K2-1個のパラメータ
変数M個の時:KM-1個のパラメータ→指数的に増大
19.
19
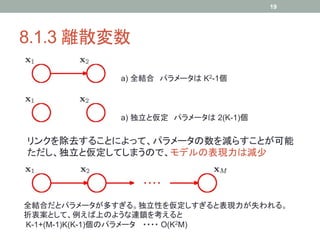
8.1.3 離散変数
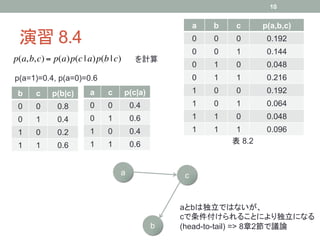
a) 全結合 パラメータは K2-1個
a) 独立と仮定 パラメータは 2(K-1)個
リンクを除去することによって、パラメータの数を減らすことが可能
ただし、独立と仮定してしまうので、モデルの表現力は減少
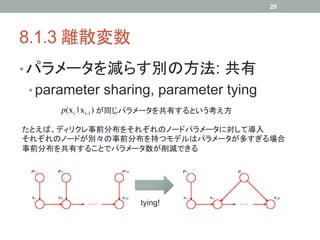
全結合だとパラメータが多すぎる。独立性を仮定しすぎると表現力が失われる。
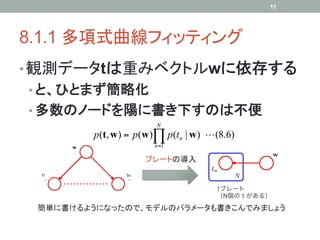
折衷案として、例えば上のような連鎖を考えると
K-1+(M-1)K(K-1)個のパラメータ ・・・・ O(K2M)






















![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)












































