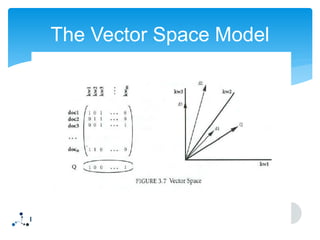
This document discusses information retrieval and describes its three main phases: 1) asking a question to define an information need, 2) constructing an answer by matching queries to documents, and 3) assessing the relevance of the retrieved answers. It also covers several important information retrieval concepts like keywords, indexing documents, stemming words, calculating TF-IDF weights, and evaluating system performance using recall and precision.









































































![ICDIM 06 Web IR Tutorial [Compatibility Mode].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/icdim06webirtutorialcompatibilitymode-250307100423-5b1c7700-thumbnail.jpg?width=640&height=640&fit=bounds)
















































