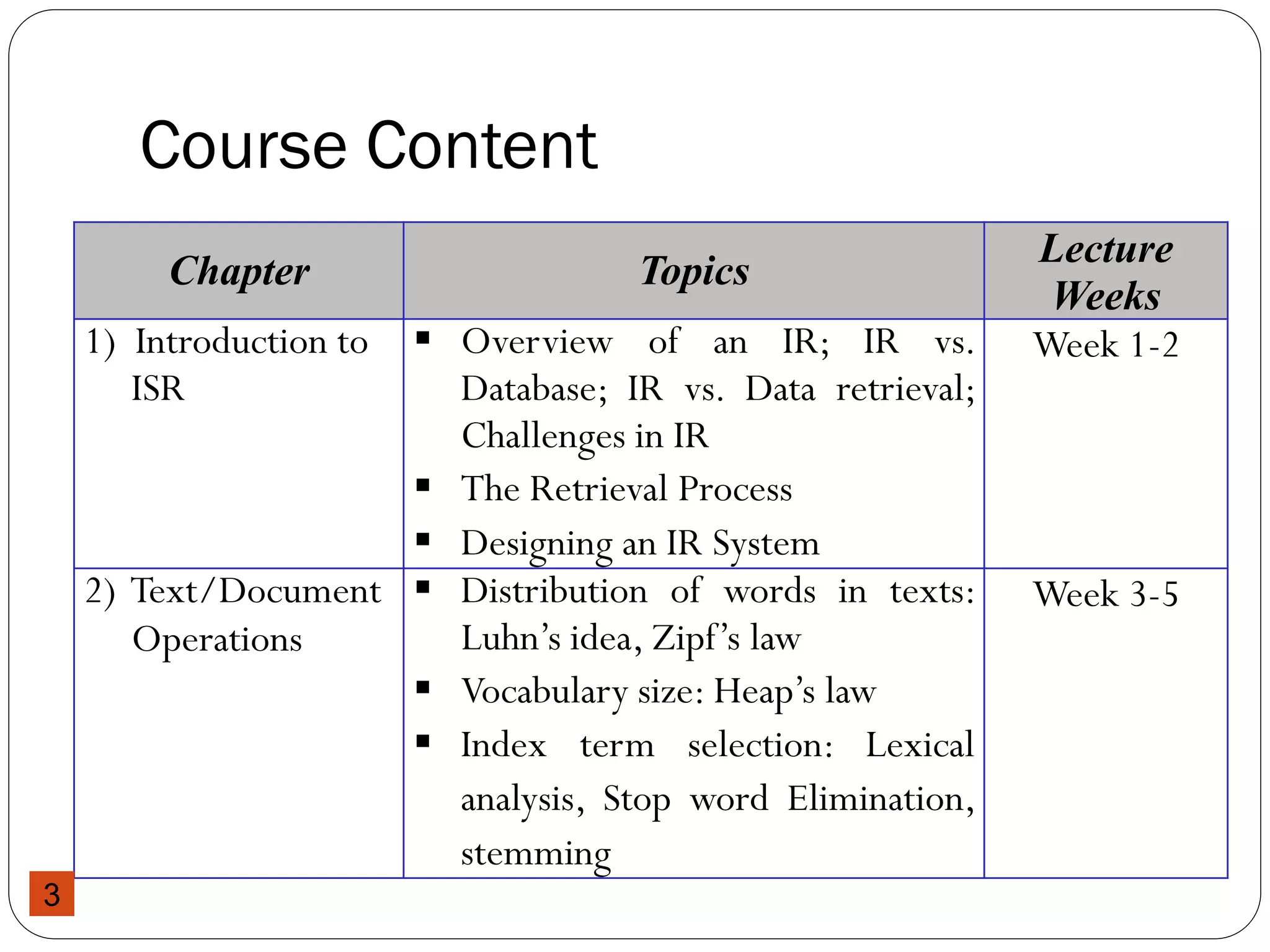
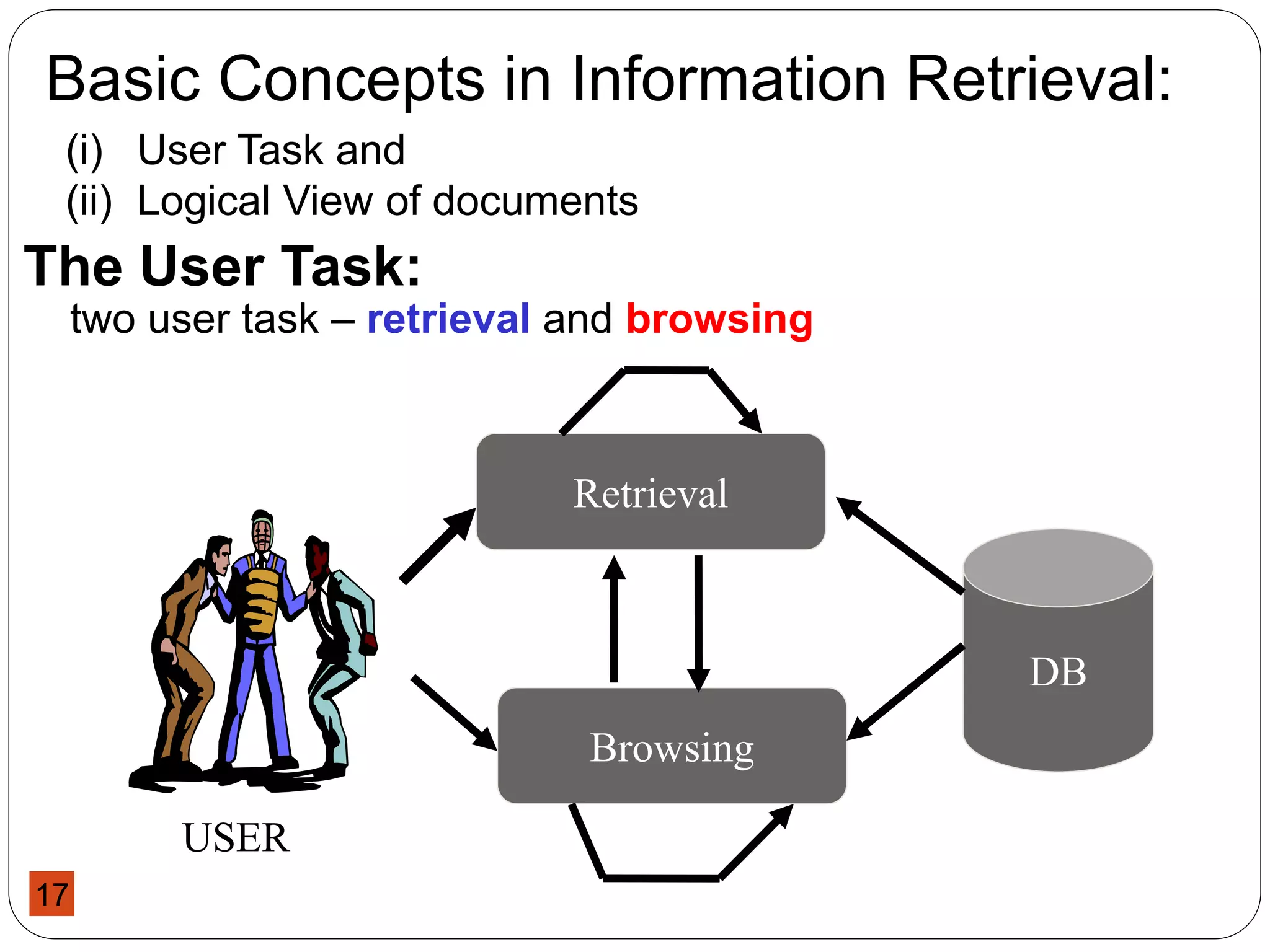
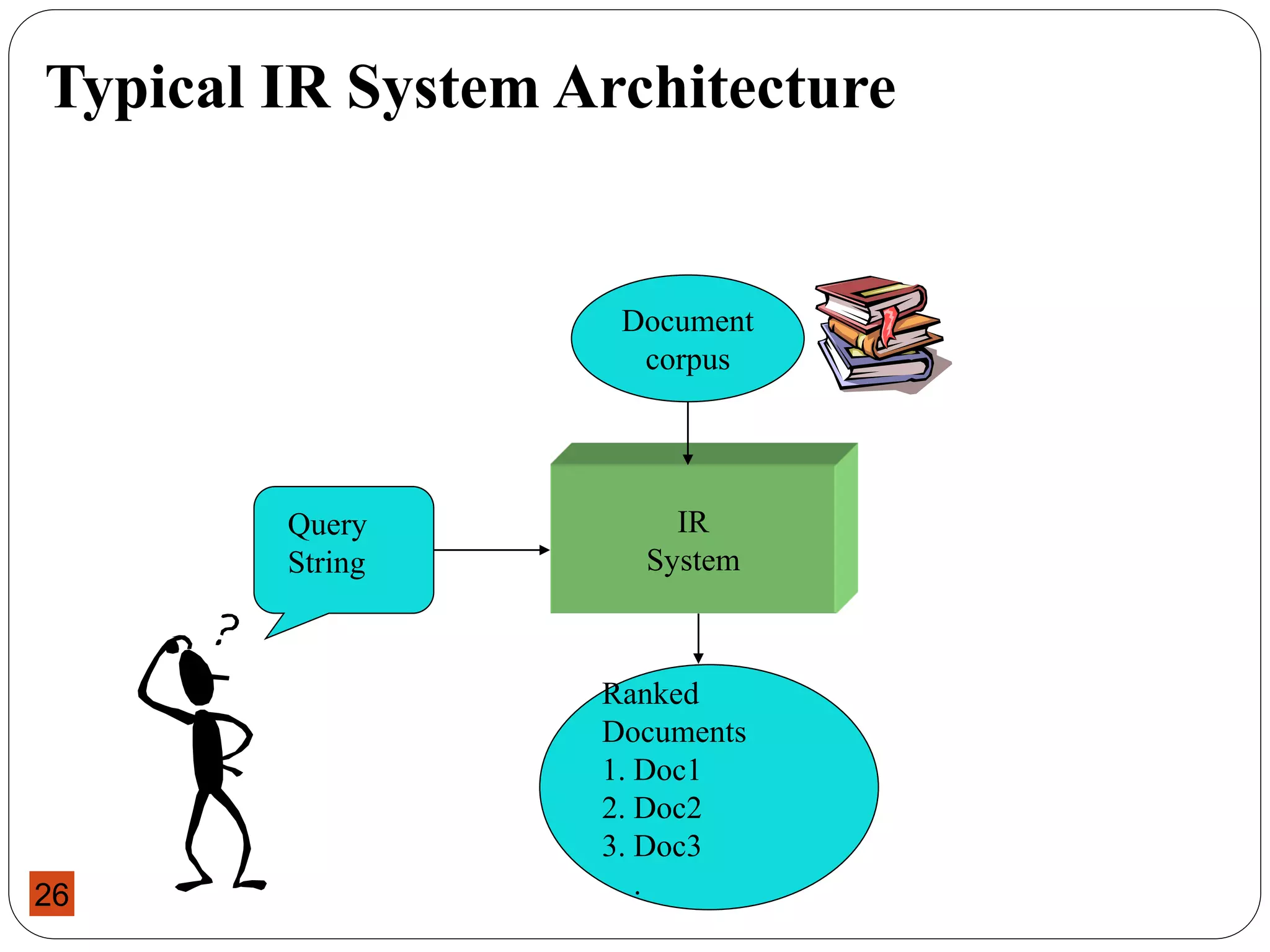
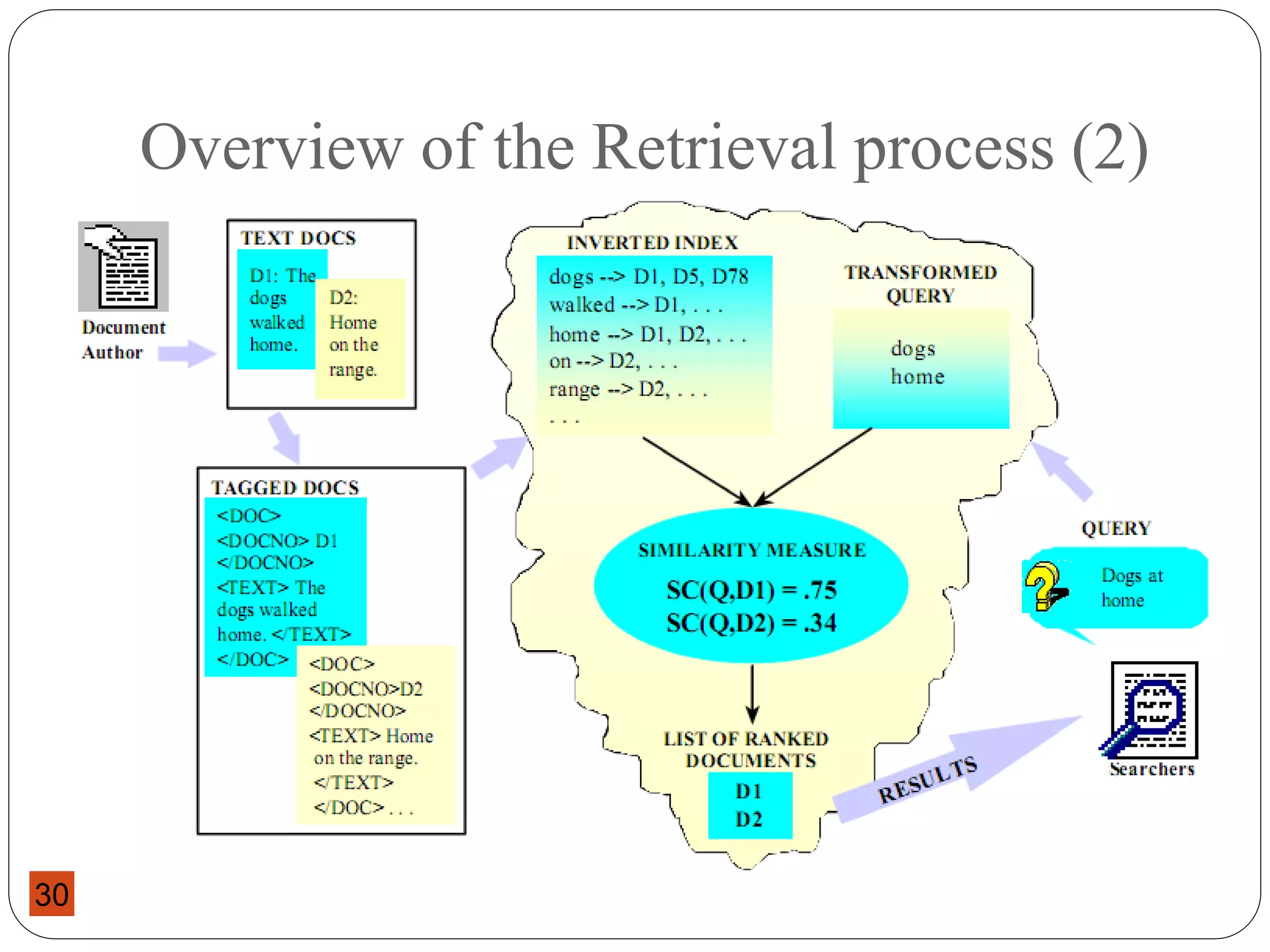
This document provides an overview of a course on Information Storage and Retrieval. The course objectives are to familiarize students with theories of information storage and retrieval, introduce modern concepts of information retrieval systems, and acquaint students with indexing, matching, organizing and evaluating strategies for IR systems. The course content covers topics like text operations, term weighting, indexing structures, IR models, retrieval evaluation, and query languages over 14 weeks. Students will be evaluated through assessments, a project, and a final exam.




















































































![ICDIM 06 Web IR Tutorial [Compatibility Mode].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/icdim06webirtutorialcompatibilitymode-250307100423-5b1c7700-thumbnail.jpg?width=640&height=640&fit=bounds)



















