Download as PDF, PPTX


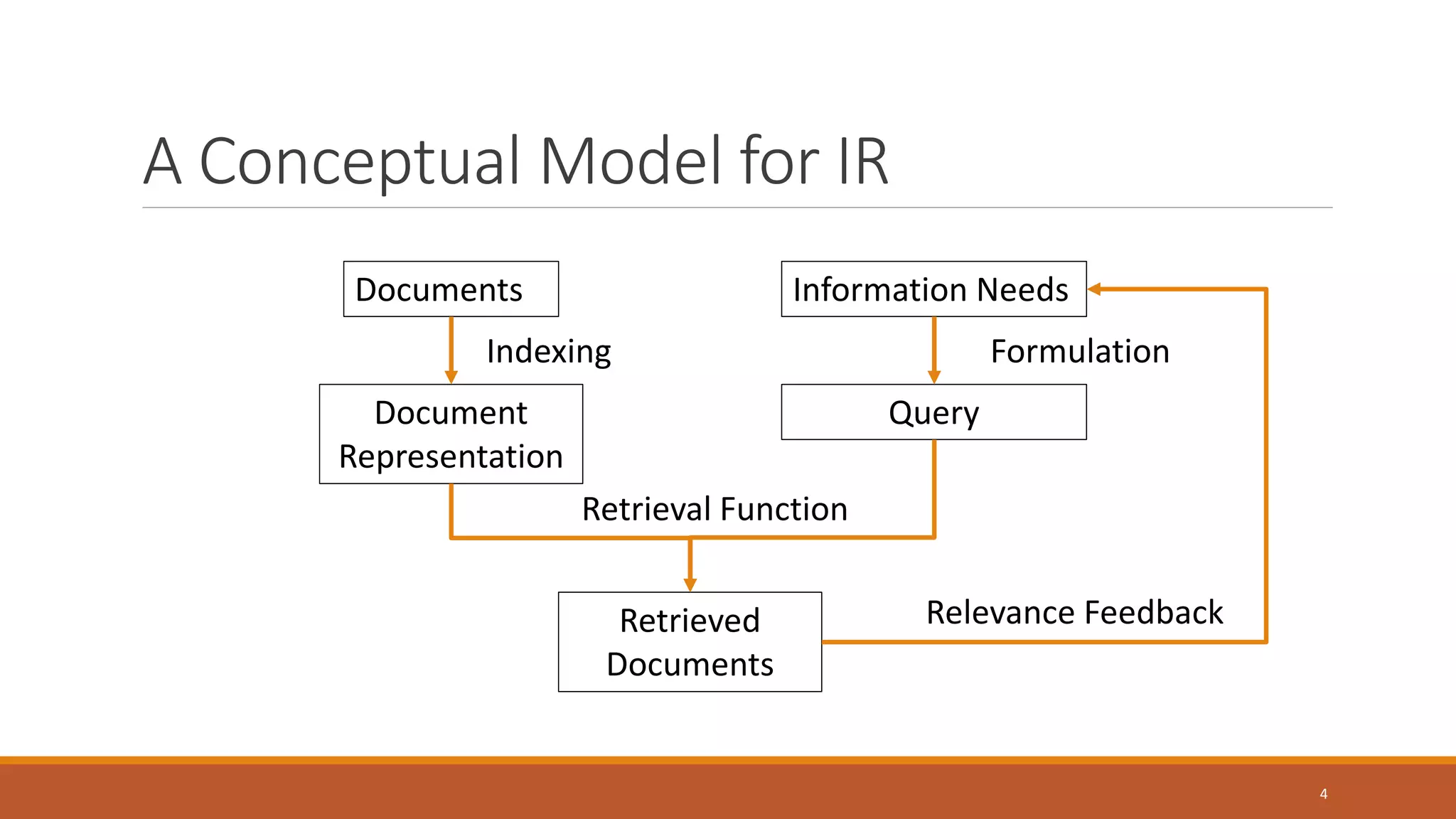


























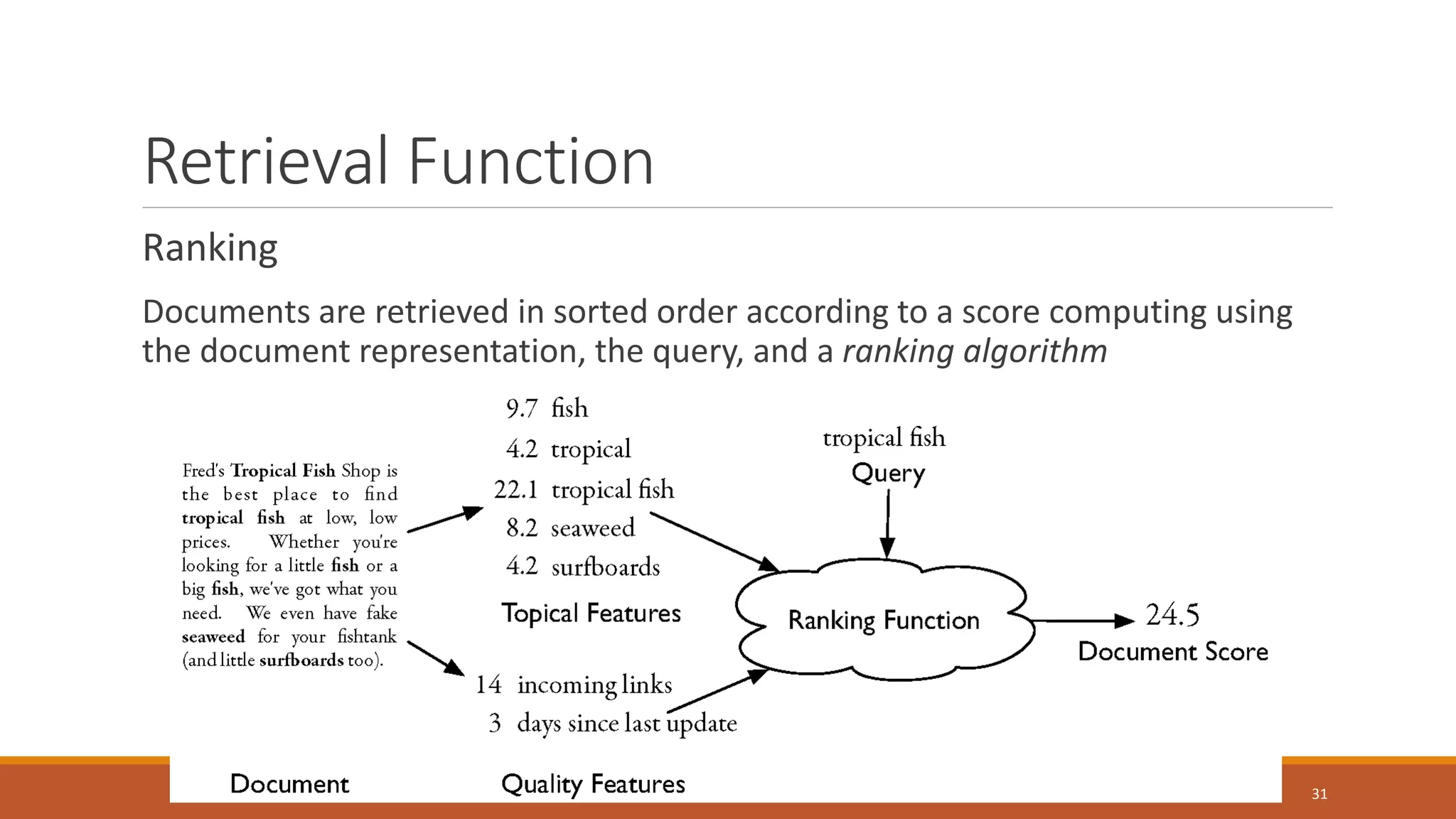






























The document is a guest lecture on information retrieval, covering concepts such as document representation, indexing methods, retrieval functions, and evaluation metrics. It also discusses challenges in the field, including personalization and handling big data. Key definitions and practical applications of information retrieval in search engines are highlighted throughout the lecture.




































![ICDIM 06 Web IR Tutorial [Compatibility Mode].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/icdim06webirtutorialcompatibilitymode-250307100423-5b1c7700-thumbnail.jpg?width=640&height=640&fit=bounds)














































