Chapter 1 - Introduction to IR Information retrieval ch1 Information retrieval ch1
1.
ETHIOPIAN POLICE UNIVERSITY
DEPARTMENTOF INFORMATION TECHNOLOGY AND CYBER SECURITY
Information Storage and Retrieval
Chapter One: Introduction to Information Storage and Retrieval
2.
Chapters Point ofDiscussions
• IR and IR systems
• Data versus information retrieval
• IR and the retrieval process
• Basic structure of an IR system
3.
Chapters objectives
• Atthe end of this chapter you should have a comprehensive
understanding of:
• Information Retrieval
• The differences between data and information retrieval
• The details of the retrieval process and
• The fundamental structure of IR systems.
4.
Brainstorming
• Consider Googlesearch engine as use case and discuss:
How does Google decide which websites to show when you search
for something?
• What do you think makes a website more likely to appear at the
top?
What do you think happens when you type a word into Google?
• Can you describe the steps from your search to the results you
see?
What kinds of problems do you think Google might face when trying
to find and show the right information from millions of websites?
5.
Brainstorming
• How doesGoogle decide which websites to show when you search for
something? What do you think makes a website more likely to appear at the
top?
Google uses a system called algorithms to rank websites.
Relevance to the search term, the quality of its content, the number of other
sites linking to it, and how often it is updated are factors to determine the rank.
Websites that provide valuable, trustworthy information are often ranked higher.
• What do you think happens when you type a word into Google? Can you
describe the steps from your search to the results you see?
It quickly searches its massive index of web pages.
It looks for pages that match your query, ranks them based on relevance, and
then displays a list of results on the search results page.
This process happens just in seconds!
6.
Brainstorming
• What kindsof problems do you think Google might face when trying to find
and show the right information from millions of websites?
Google face challenges to provide comprehensive search results for
languages those lack extensive online content or digital resources.
7.
Introduction
• Nowadays, enormousamounts of data are being generated
continuously from various sources such as social media platforms,
sensors and more.
Data lacks value, if we can't access and search through it
effectively, which would be extremely challenging without
information retrieval systems.
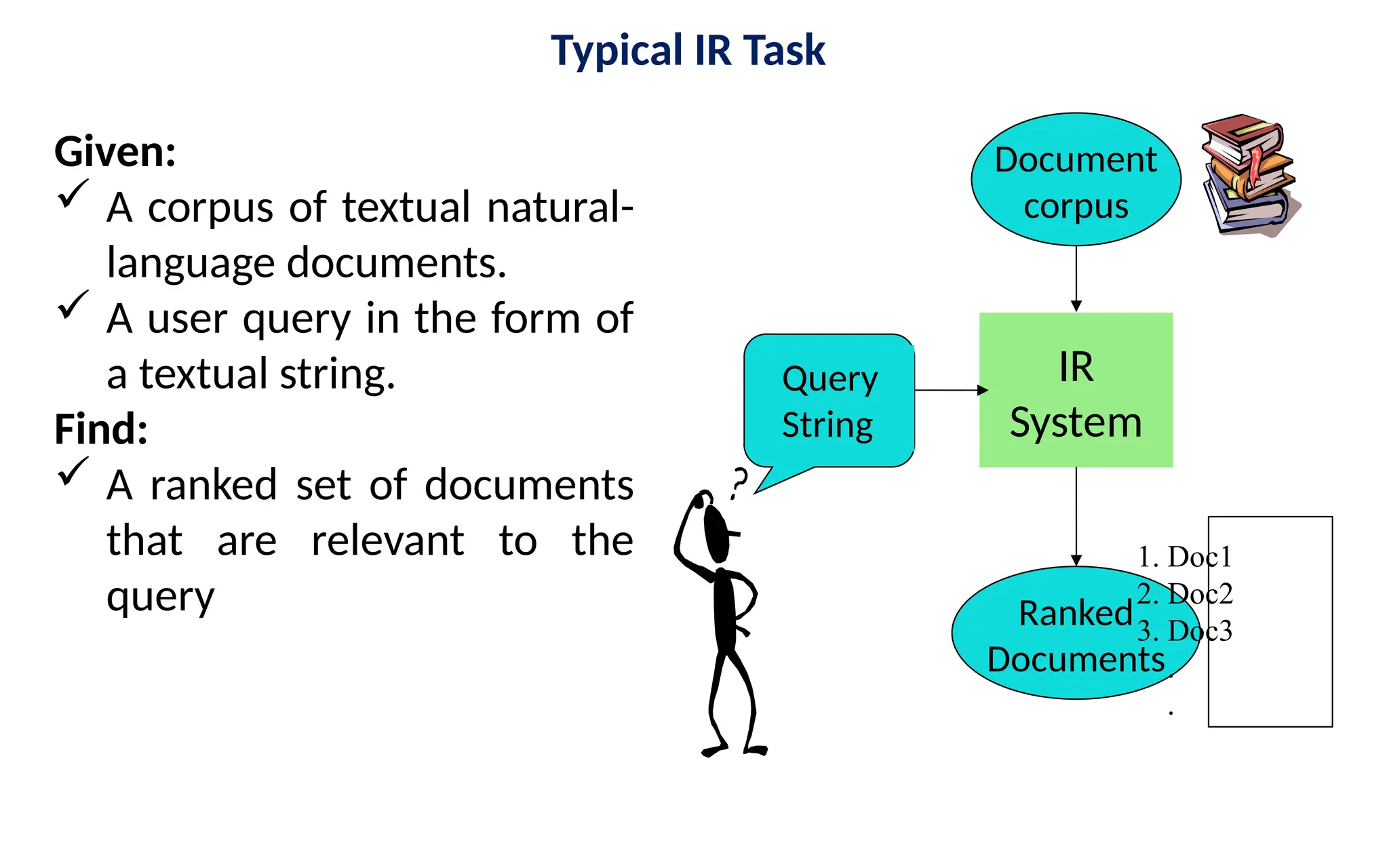
• Information retrieval (IR) is the process of finding material (usually
documents) of an unstructured nature (usually text) that satisfies an
information need from large collections (usually stored on computers).
• Information retrieval deals with representation, storage, organization
of, and access to information items.
The organization and access of information items should provide the user
with easy access to the information in which he/she is interested.
8.
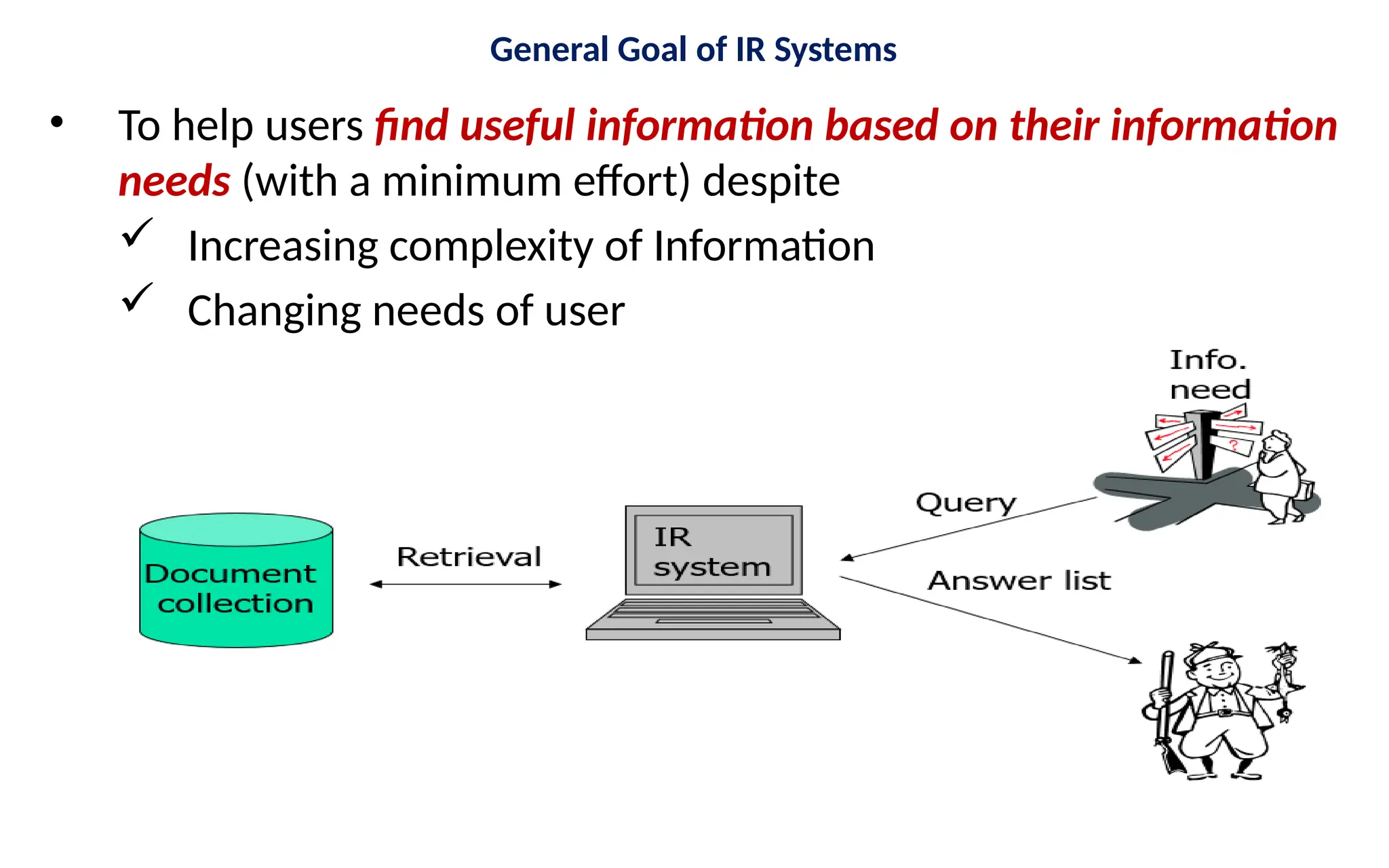
General Goal ofIR Systems
• To help users find useful information based on their information
needs (with a minimum effort) despite
Increasing complexity of Information
Changing needs of user
Data versus InformationRetrieval
• Emphasis of IR is on the retrieval of information, rather than on the
retrieval of data.
Data retrieval
Consists mainly of determining which documents contain a set of keywords
in the user query (which is not enough to satisfy the user information need)
Aims at retrieving all objects that satisfy well defined semantics
a single erroneous object among a thousand retrieved objects implies failure
Information retrieval
Is concerned with retrieving information about a subject or topic than
retrieving data which satisfies a given query
semantics is frequently loose: the retrieved objects might be inaccurate
small errors are tolerated
11.
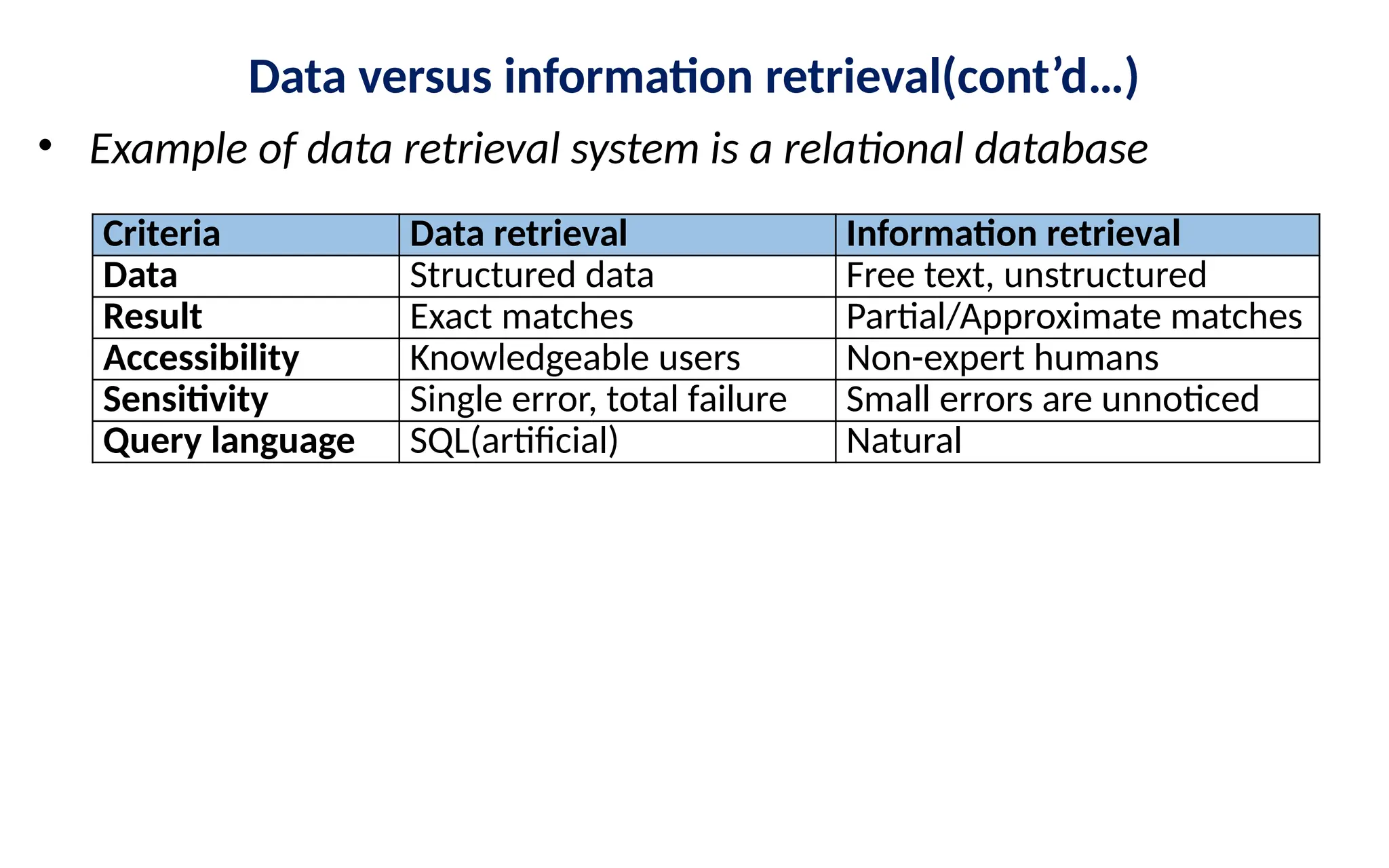
Data versus informationretrieval(cont’d…)
• Example of data retrieval system is a relational database
Criteria Data retrieval Information retrieval
Data Structured data Free text, unstructured
Result Exact matches Partial/Approximate matches
Accessibility Knowledgeable users Non-expert humans
Sensitivity Single error, total failure Small errors are unnoticed
Query language SQL(artificial) Natural
12.
Examples of IRSystems
• Document-retrieval systems:
Store entire documents
Usually retrieve stored document by title or by key words
associated with the document.
• Reference retrieval systems:
Store references to documents rather than the documents
themselves.
Usually provide the titles of relevant documents and
frequently their physical locations.
Extremely effective in libraries
13.
Examples of IRSystems(cont’d…)
• Cross language information retrieval: designed to retrieve
information in one language based on queries formulated in
another language.
Accept queries in user preferred language.
Translates the query into the target language of the
document collection.
Searches the documents for matches to the translated query.
Rank retrieved documents based on relevance, considering
factors like keyword matching and context.
14.
Examples of IRSystems(cont’d…)
• Question-answering IR system: designed to provide specific answers to
user queries instead of just returning a list of documents.
Processing: analyzing of the query to identify key concepts and intent.
Retrieval: searches a structured or unstructured data source to find
relevant information.
• Ranking of retrieved documents on their relevance to question
using algorithms that assess factors like keyword matching,
context, and semantic meaning.
Answer extraction: extraction of potential answers from the ranked
documents, focusing on sentences or phrases that directly respond to
the query.
Response Generation: formats the final answer to ensure clarity and
conciseness.
15.
Examples of IRSystems(cont’d…)
• Image Retrieval: designed to search and retrieve images from a database or the
internet based on specific queries, often using visual content or metadata.
Text-Based Image Retrieval: relies on metadata (titles, descriptions, tags)
associated with images.
Searches for images that match the keywords or phrases provided by the
user.
Content-Based Image Retrieval (CBIR): analyzes the visual content of images to
find matches.
Utilizes features such as color, texture and shapes extracted from the
images.
Retrieval Process:
Index both visual features and associated metadata
comparing the user’s input (text or visual) against the indexed images.
retrieve images are ranked based on relevance to the query, considering both
visual similarity and textual metadata matches.
16.
What makes IRhard?
• Query evaluation (or retrieval process)
– To what extent does a document correspond to a query?
– Simply, matching on words is a very hard approach as one
word can have different semantic meanings.
• System evaluation
– How good is a system?
– Are the retrieved documents relevant? (precision)
– Are all the relevant documents retrieved? (recall)
Intelligent IR:
Taking into account the meaning of the words used.
Taking into account the order of words in the query.
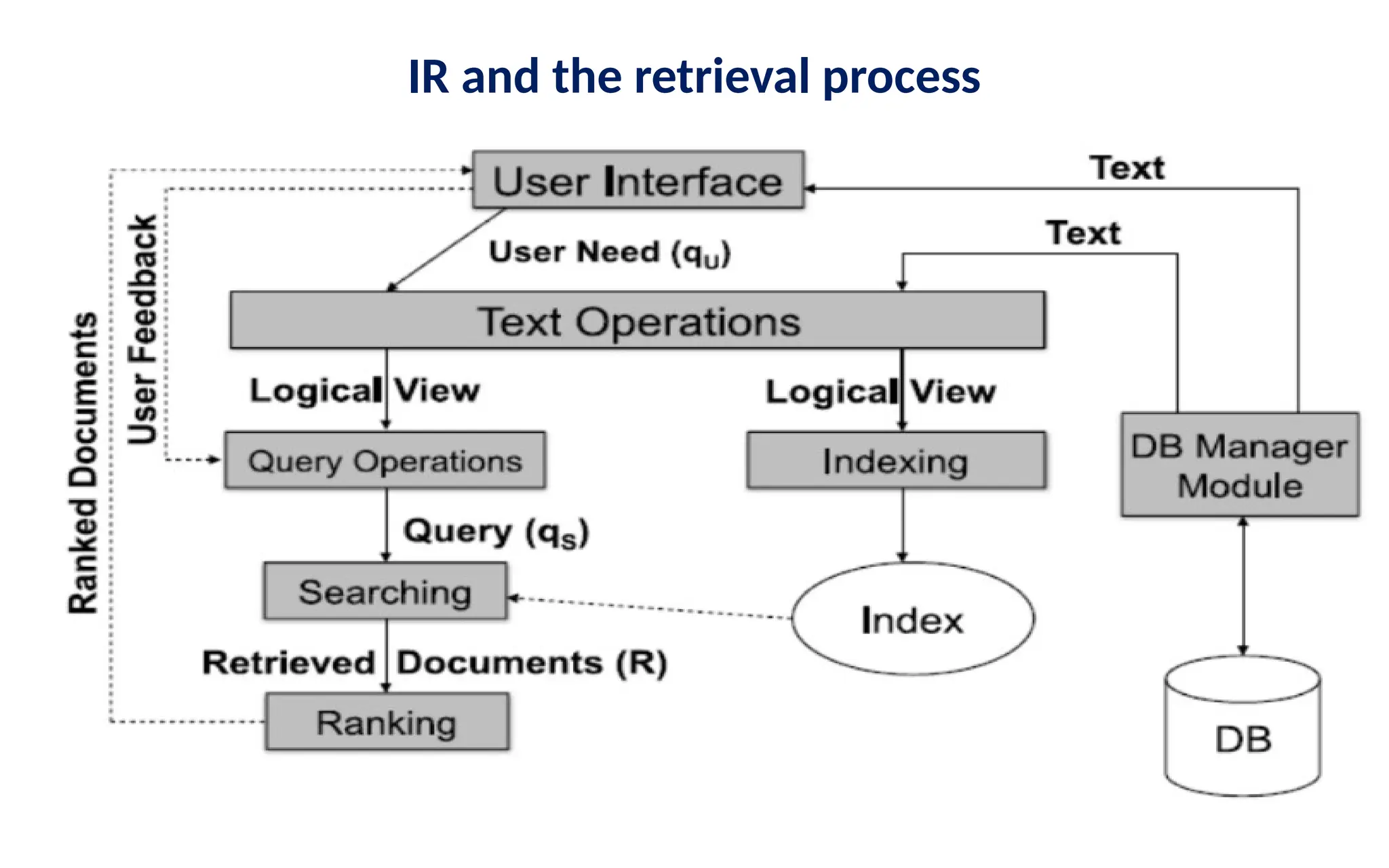
IR and theretrieval process(cont’d…)
• It is necessary to define the text database before any of the
retrieval processes are initiated.
• This is usually done by the manager of the database and includes
specifying the following
– The documents to be used
– The operations to be performed on the text
– The text model to be used (the text structure and what
elements can be retrieved)
• The text operations transform the original documents and the
information needs and generate a logical view of them
19.
IR and theretrieval process(cont’d…)
• Once the logical view of the documents is defined, the database
module builds an index of the text
– An index is a critical data structure
– It allows fast searching over large volumes of data
• Different index structures might be used, but the most popular one
is the inverted file.
• Given that the document database is indexed, the retrieval process
can be initiated.
20.
IR and theretrieval process(cont’d…)
• The user first specifies a user need via the user interface which is
then parsed and transformed by the same text operation applied
to the text.
• Next the query operations is applied before the actual query,
which provides a system representation for the user need, is
generated.
• The query is then processed to obtain the retrieved documents
(Searching).
• Before the retrieved documents are sent to the user, the retrieved
documents are ranked according to the likelihood of relevance
21.
IR and theretrieval process(cont’d…)
• The user then examines the set of ranked documents in the search
for useful information. Two choices for the user:
– reformulate query, run on entire collection or
– reformulate query, run on result set
• At this point, s/he might locate a subset of the documents seen as
definitely of interest and initiate a user feedback cycle
• In such a cycle, the system uses the documents selected by the
user to change the query formulation.
• Modified query is assumed to be better representation of the real
user need than the previous one.
22.
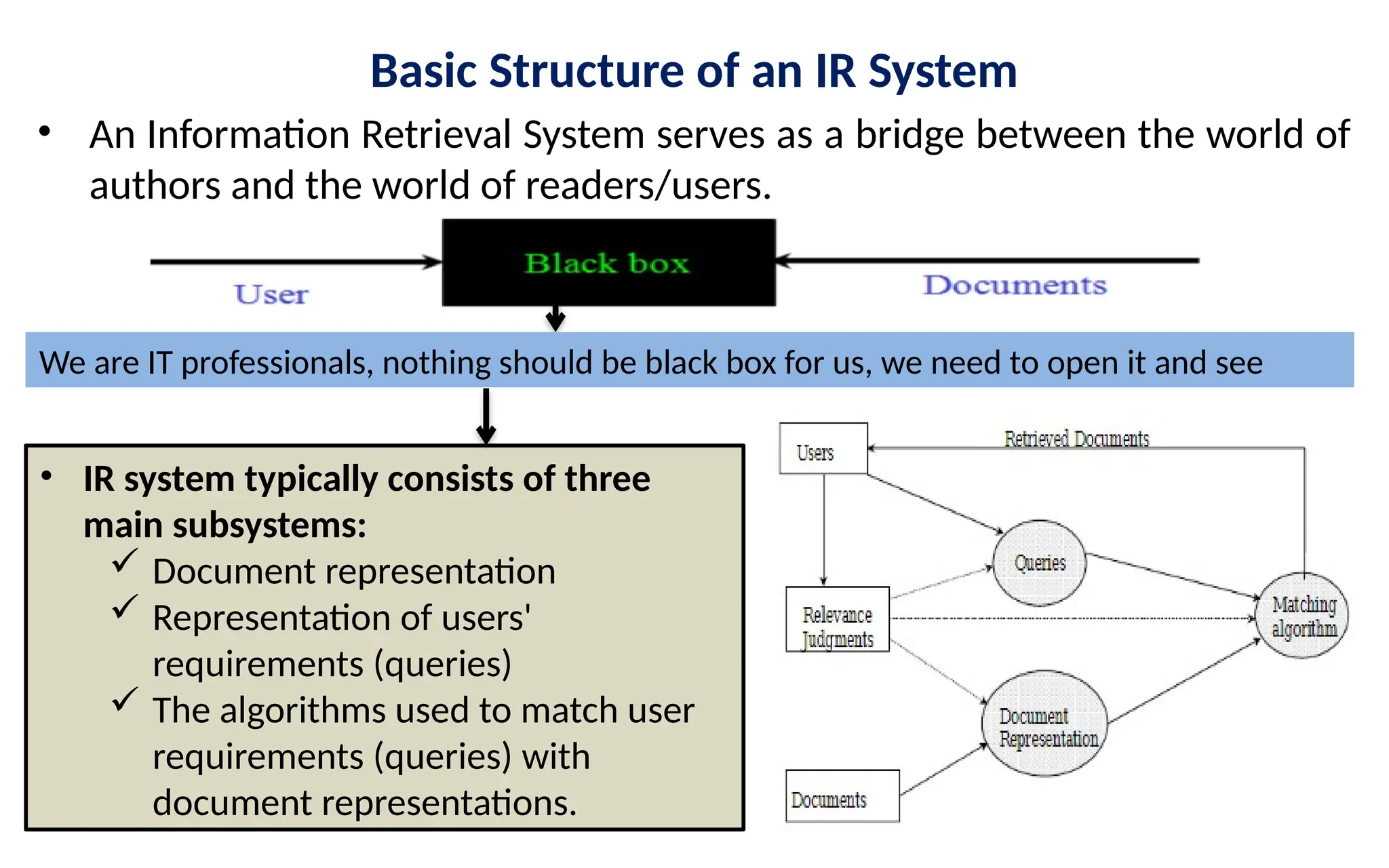
Basic Structure ofan IR System
• An Information Retrieval System serves as a bridge between the world of
authors and the world of readers/users.
• IR system typically consists of three
main subsystems:
Document representation
Representation of users'
requirements (queries)
The algorithms used to match user
requirements (queries) with
document representations.
We are IT professionals, nothing should be black box for us, we need to open it and see
23.
Pros and consof IR System
• Pros
– Fast Answers: super-fast and efficient at finding and bringing back the
exact information needed from huge amounts of data.
– 24/7 Availability: retrieval systems never take breaks.
• They are always active, standing by to retrieve information
whenever we require it, whether it's daytime or night-time.
• Cons
– Garbage In Garbage Out: greatly depends on the accuracy and
cleanliness of the data provided to generate meaningful results.
– Overreliance on Keywords: If search terms don’t match exactly,
crucial information will be missed.
– Information Overload Risk: retrieval of too much information.























































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)











