Downloaded 128 times



















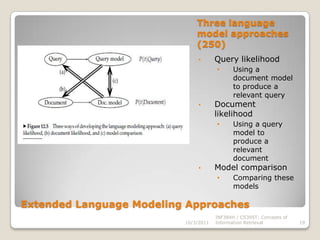





The document provides background information on Christopher Manning, Prabhakar Raghavan, and Hinrich Schutze, who are authors of the book "Introduction to Information Retrieval: Language models for information retrieval". It then outlines the presentation which discusses language models for information retrieval, including query likelihood models, estimating query generation probabilities, and experiments comparing language modeling approaches to other IR techniques.











































![ICDIM 06 Web IR Tutorial [Compatibility Mode].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/icdim06webirtutorialcompatibilitymode-250307100423-5b1c7700-thumbnail.jpg?width=640&height=640&fit=bounds)






















