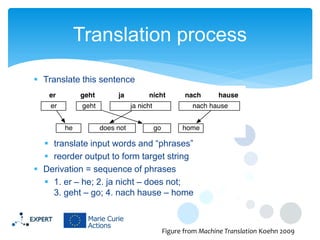
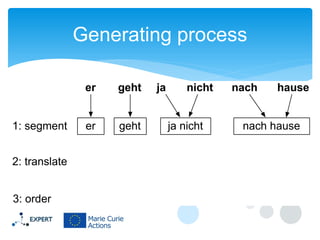
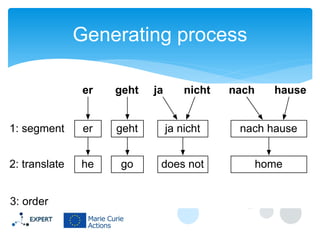
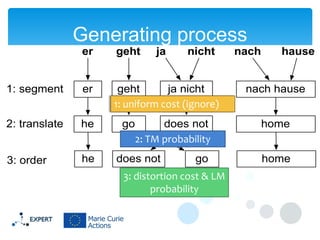
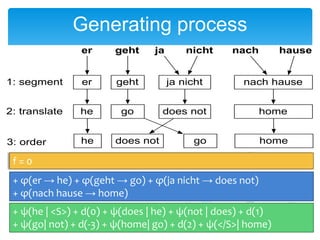
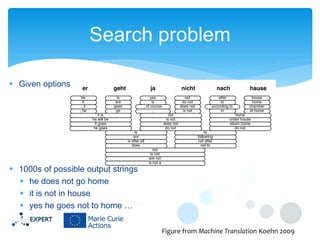
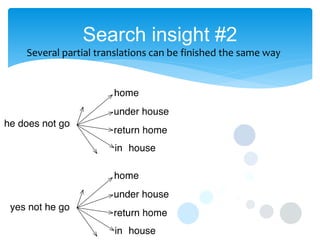
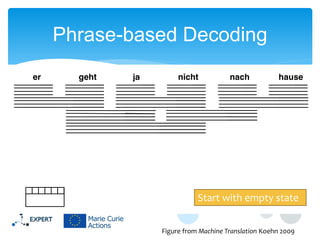
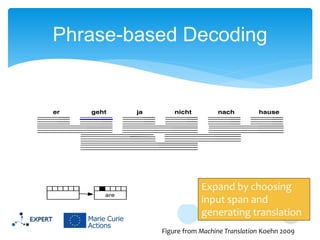
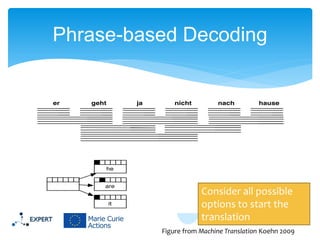
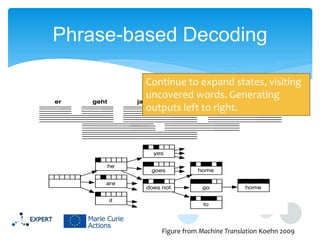
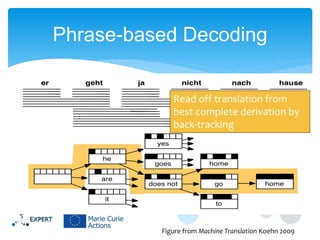
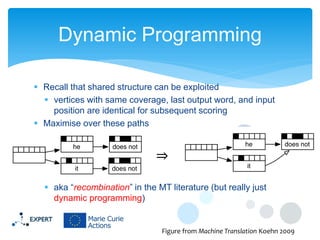
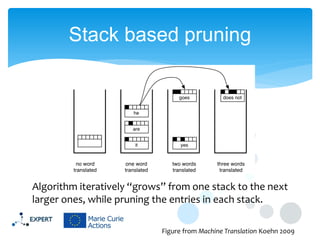
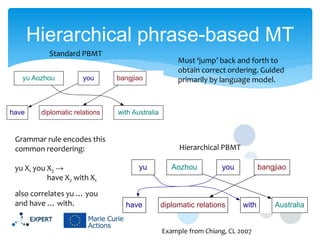
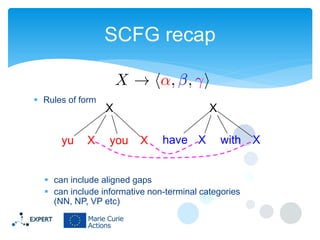
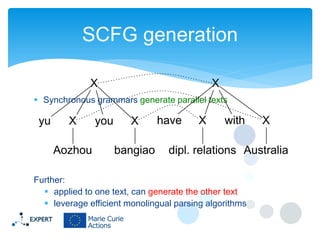
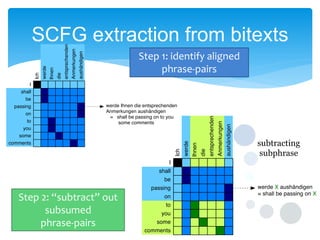
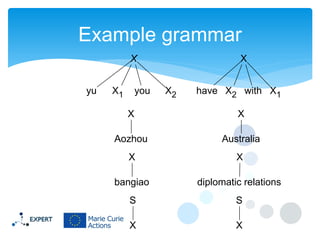
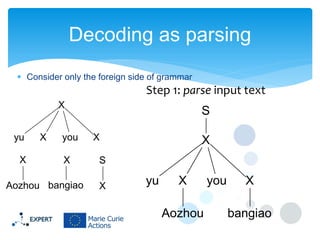
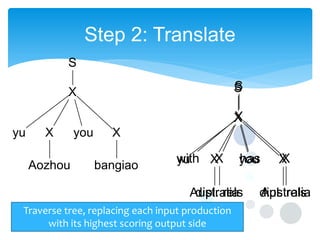
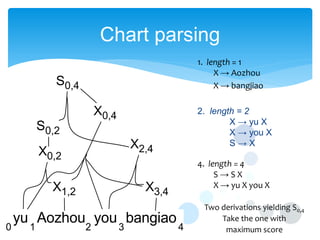
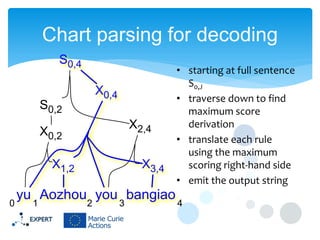
This document discusses statistical machine translation decoding. It begins with an overview of decoding objectives and challenges, such as ambiguity in possible translations. It then describes decoding phrase-based models using a linear model and dynamic programming approach, with approximations like beam search. Grammar-based decoding is also covered, including synchronous context-free grammar parsing and translation. Key challenges like search complexity and language model integration are addressed.











































![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)