Downloaded 11 times





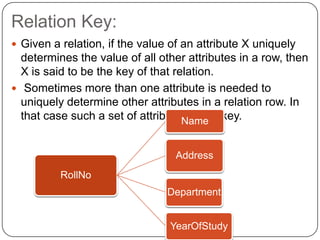
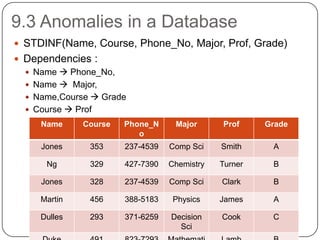



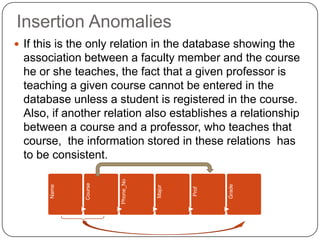









The document discusses database normalization. It defines functional dependency and explains how anomalies like redundancy, insertion anomalies, deletion anomalies, and update anomalies can occur in a database without normalization. It also describes the different normal forms including 1NF, 2NF, 3NF and BCNF. Decomposition is introduced as a process to normalize relations by eliminating anomalies. The goal of normalization is to ensure data is stored efficiently and consistently without redundancy.
























![The relational data model part[1]](https://cdn.slidesharecdn.com/ss_thumbnails/therelationaldatamodelpart1-150714113659-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






