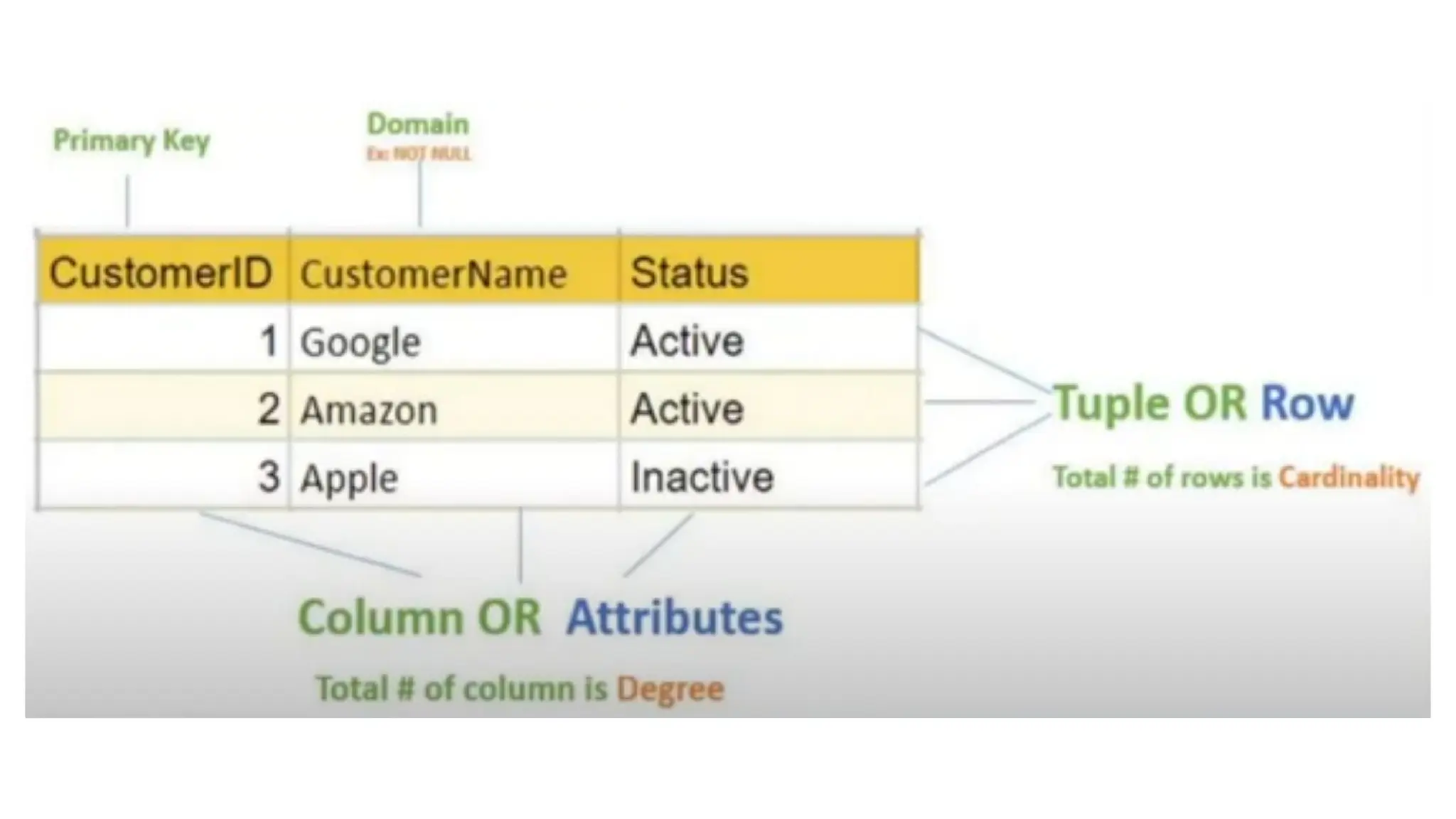
What is functionaldependencies
● A functional dependency is a constraint that specifies the relationship
between two sets of attributes where one set is can accurately determine
the value of other sets
● It typically exists between the primary key and non-key attribute within a
table
● FD is denoted as A -> B
○ A is determinant
● We canderive the FD as follows:
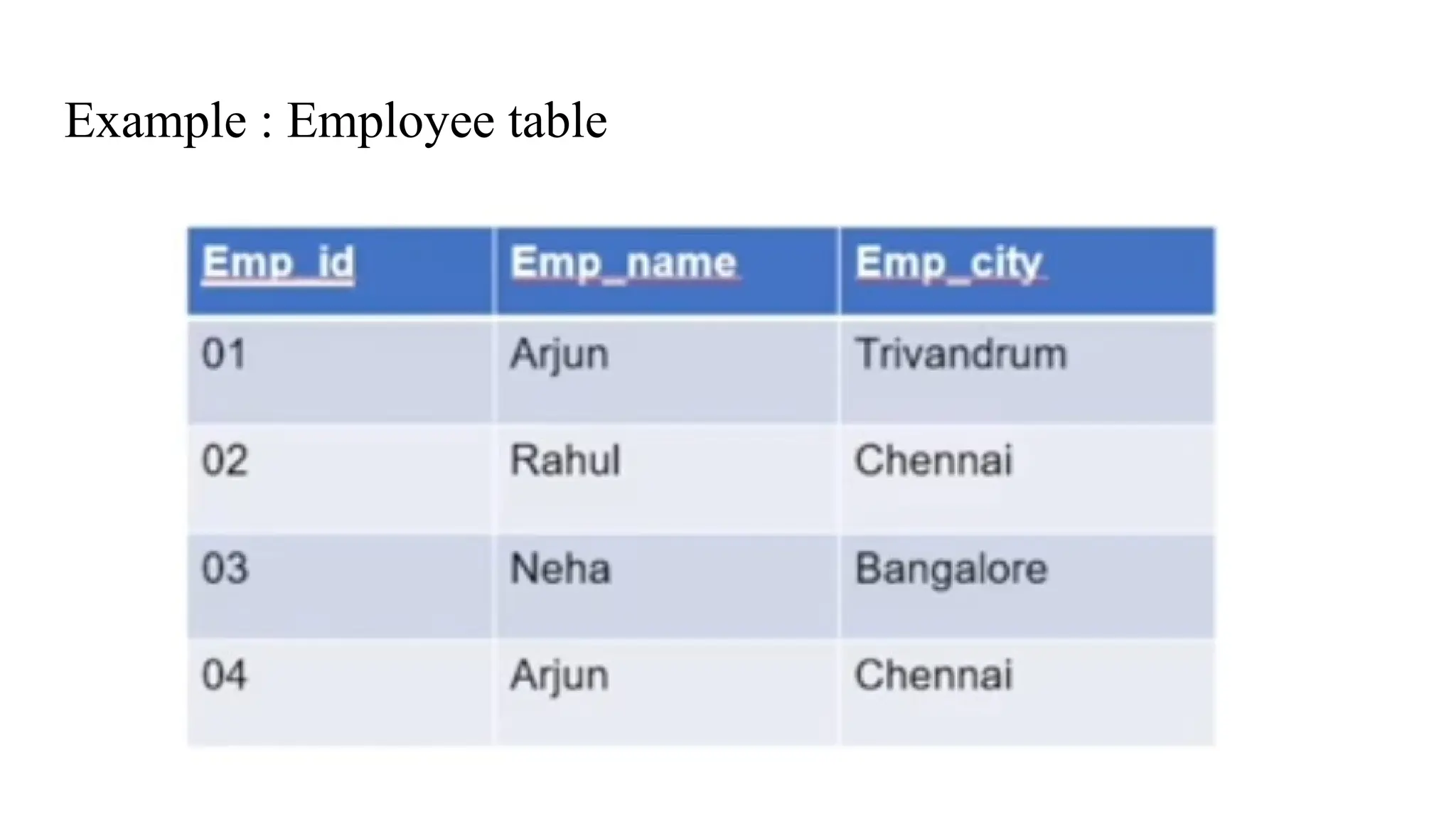
Emp_id -> Emp_name
Emp_id-> Emp_city
● In a relation functional dependency X -> Y holds if two tuples are having same
value of attribute x also have same value for attribute of Y, lets see one example:
7.
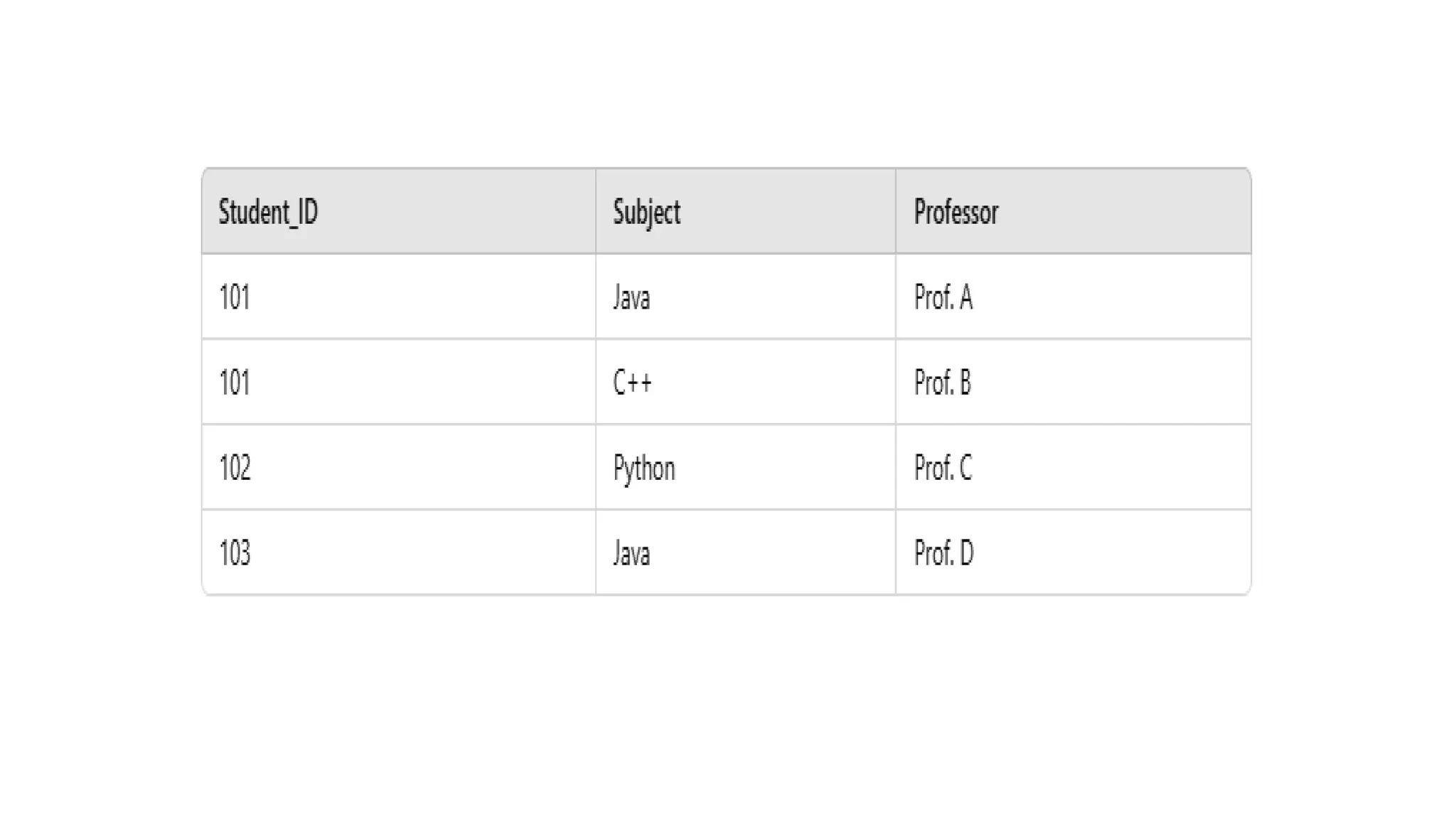
Explanation
● A functionaldependency (FD) X → Y means that if two rows have the same
value for X, they must have the same value for Y.
● Student_ID 101 appears twice, but for different subjects (Java and C++).
● This violates functional dependency because one Student_ID does not
uniquely determine a single Subject.
● Therefore we can write is as (Student_ID, Subject) → Professor
● If we know both Student_ID and Subject, we can uniquely determine the
Professor.
● Example: (101, Java) → Prof. A, (101, C++) → Prof. B.
Trivial FD
A trivialfunctional dependency is a functional dependency (FD) where
the dependent attribute (Y) is a subset of the determinant attribute (X).
(Student_ID, Name) → Name
10.
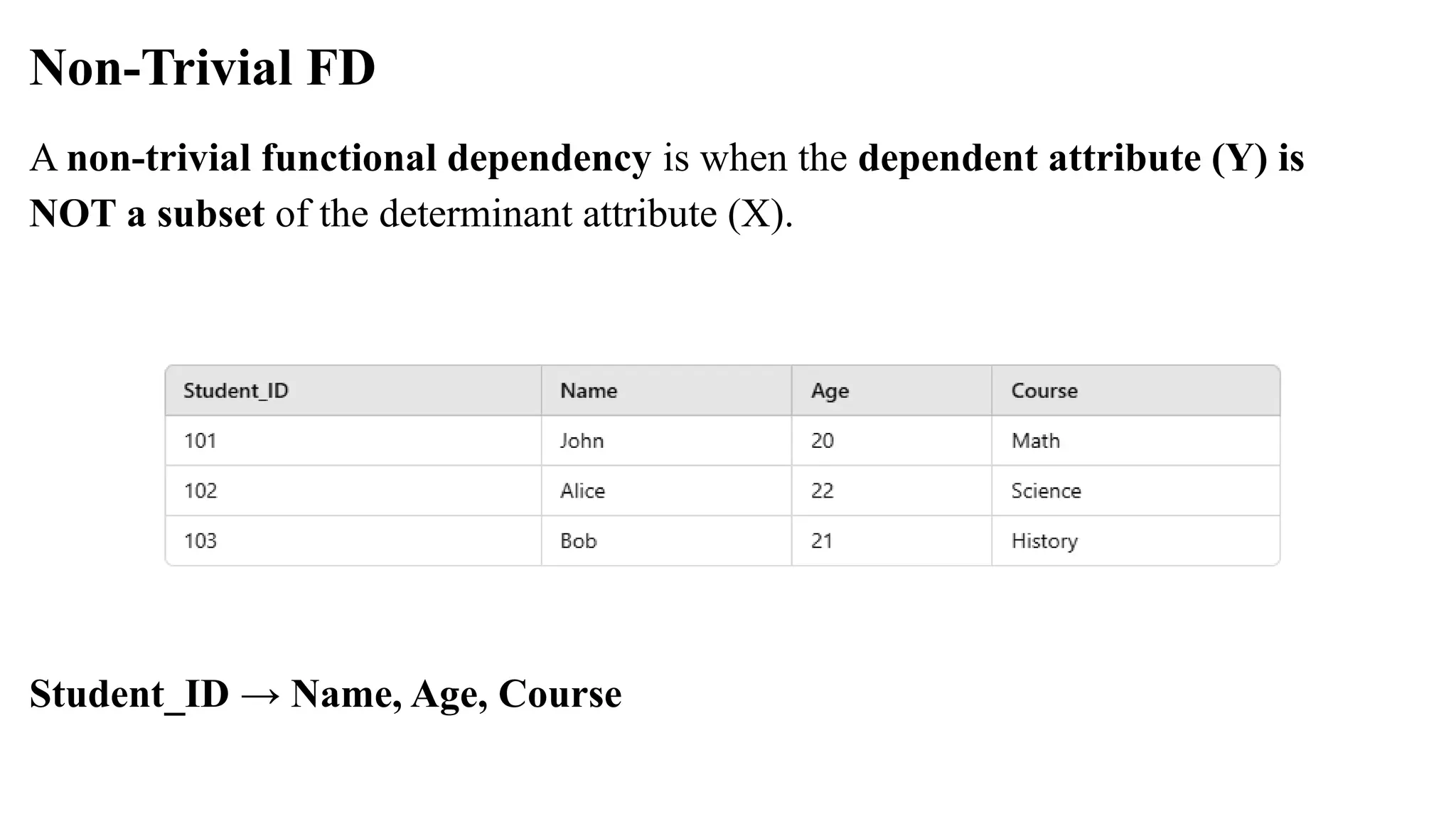
Non-Trivial FD
A non-trivialfunctional dependency is when the dependent attribute (Y) is
NOT a subset of the determinant attribute (X).
Student_ID → Name, Age, Course
11.
Armstrong's Axioms -Definition
Armstrong's Axioms are a set of rules used to infer all functional dependencies (FDs) in
a relational database. These axioms are foundational in understanding and reasoning
about functional dependencies within a relational schema in Database Management
Systems (DBMS). They are a formal way to derive new functional dependencies from a
given set of existing ones.
12.
Armstrong's Axioms
● Reflexivity
A-> B , B will be the subset of A
Let A = stu_id, B =
● Augmentation
If A -> B then, A C -> BC
● Transitivity
If A -> B and B -> C then A -> C [B should be a non-prime attribute]
13.
● Union
If A-> B and A -> C then, A -> BC
● Decomposition
If A -> BC then, A -> B & A -> C
● Pseudo transitivity
If A -> B & BC -> D then, A C -> D
14.
The informal guidelinesfor relational database schema design
1. Semantics of the attribute must be clear in the relation
2. Redundant information in tuples
3. Reducing the null values in tuples
4. Disallowing the possibility og generating spurious table
15.
Semantics of theattribute must be clear in the relation
When we group attribute to form a relation , the attributes must have a real
world meaning and proper interpretation associated with them.
Consider the example:
In the above example, these attributes are related to the employee table.
16.
What if itdoenst satifies the condition, see the example
In this example one more additional attribute is there called “
Dpjct_nos” this attribute indicates the number of project which is
currently worked by that department which has nothing to do with
the employee details, which violates the rule one
17.
Guidline 1:
"In arelational database schema, an attribute from another table should be included only
when it is necessary to establish a relationship between tables, typically as a foreign key. This
prevents data redundancy while ensuring referential integrity."
Example:
In this example we are unnecessarily using Dname, Dmgr-ssn which should be there in the
department table
18.
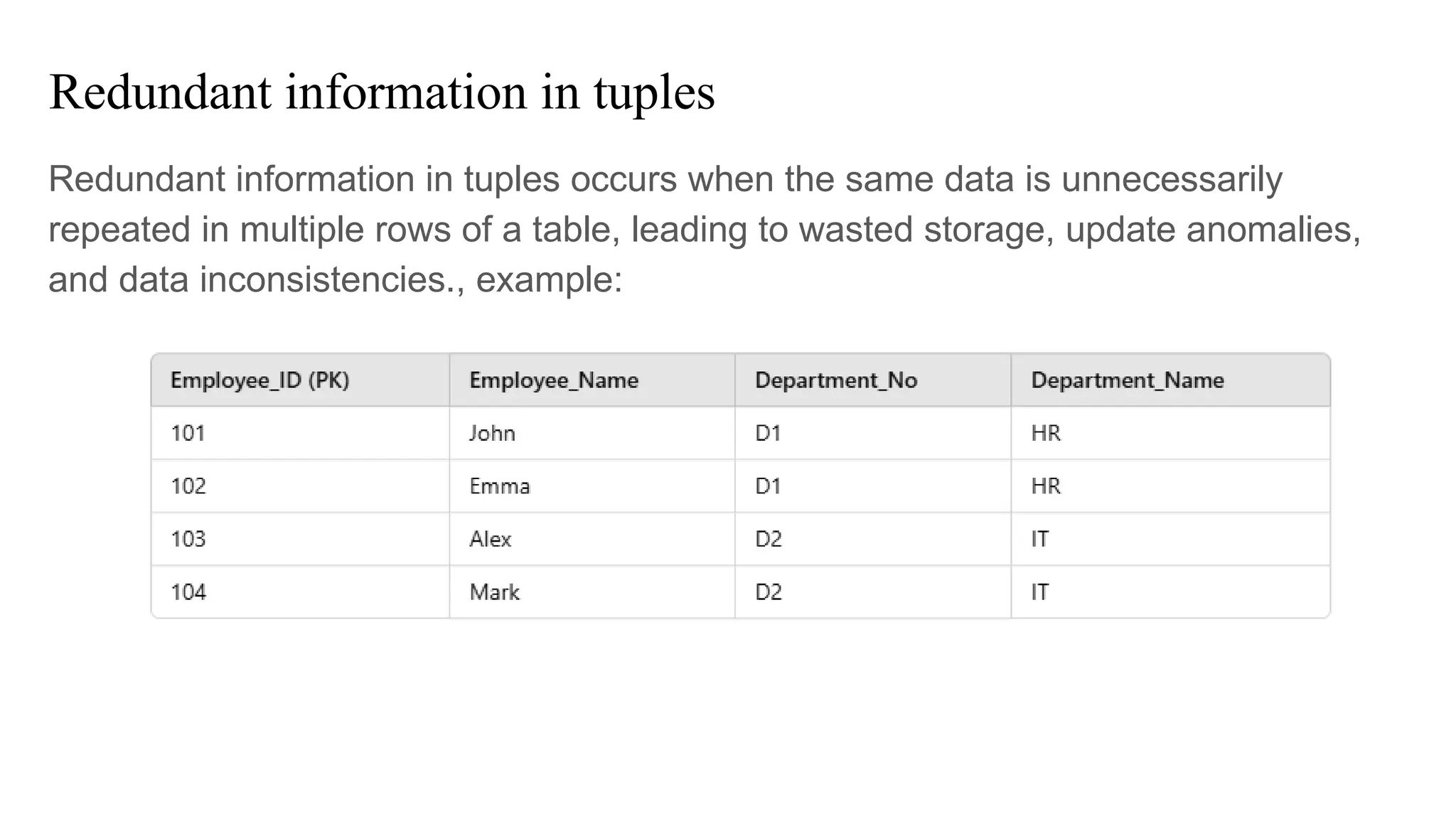
Redundant information intuples
Redundant information in tuples occurs when the same data is unnecessarily
repeated in multiple rows of a table, leading to wasted storage, update anomalies,
and data inconsistencies., example:
19.
Problem :1
Wastage ofStorage: Department Name is Repeated!
● The HR department (D1) is repeated for both John & Emma.
● The IT department (D2) is repeated for both Alex & Mark.
● This wastes storage and can cause update anomalies.
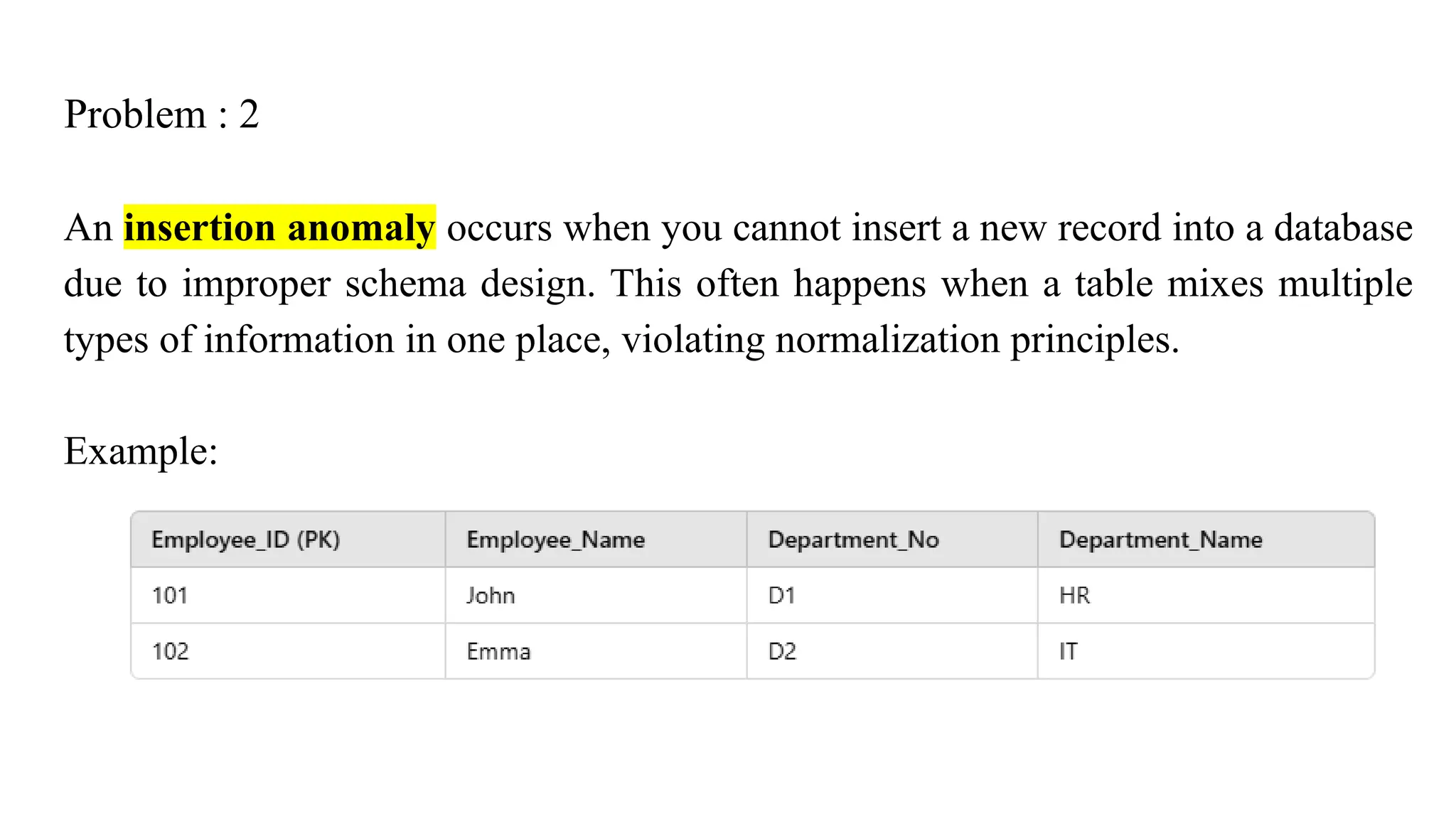
Problem : 2
Aninsertion anomaly occurs when you cannot insert a new record into a database
due to improper schema design. This often happens when a table mixes multiple
types of information in one place, violating normalization principles.
Example:
22.
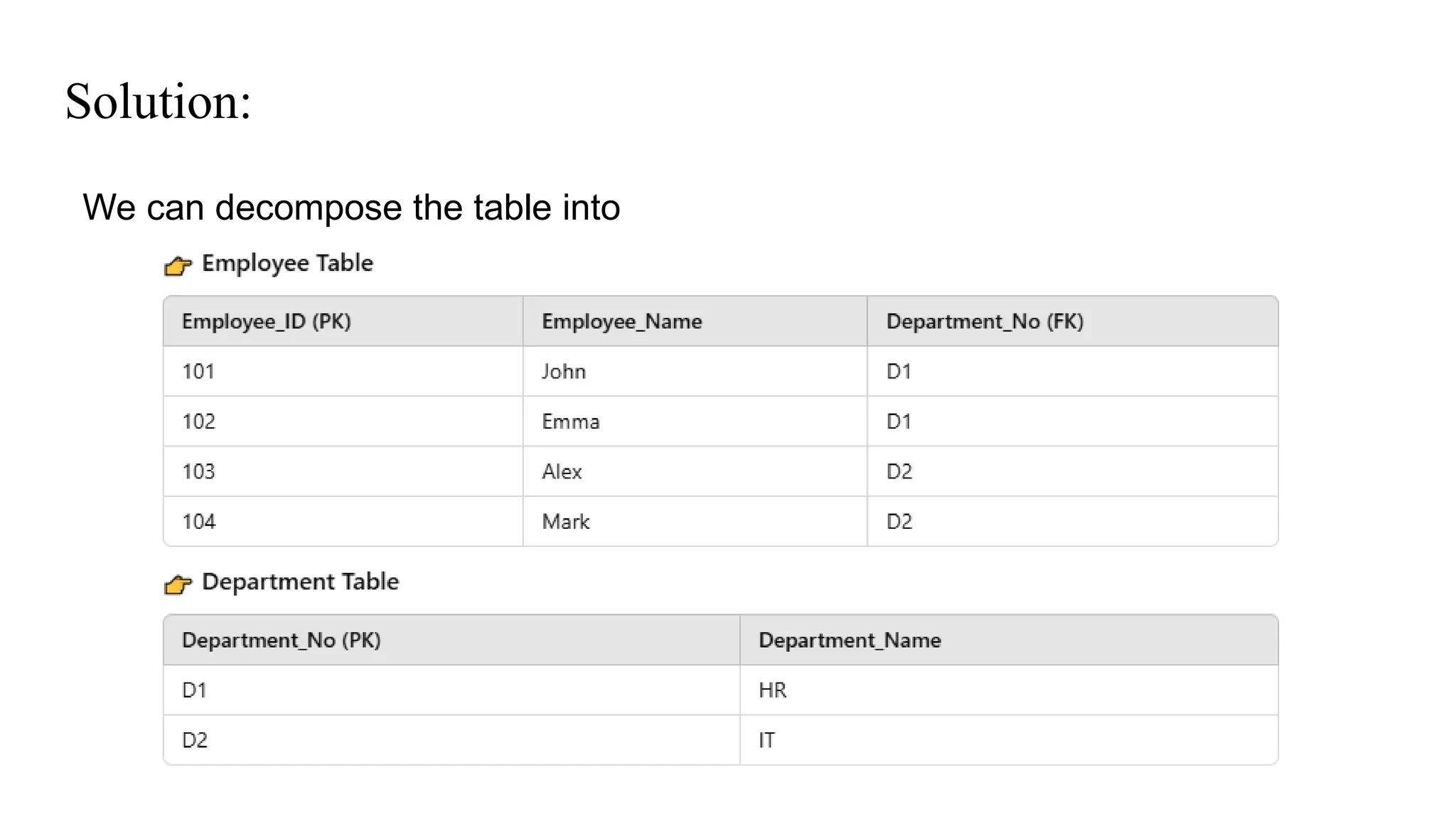
Explanation
● Here insteadof maintaining two tables in maintaining only a
single table, which means duplicate data will occur, so its better
if we maintain a separate table for employee and department
● Another violation can happen, if I try to add a new department
and if that department does not contain employees, the attribute
related to employee will become null. so again its better if we
maintain a seperate table for employee and department
23.
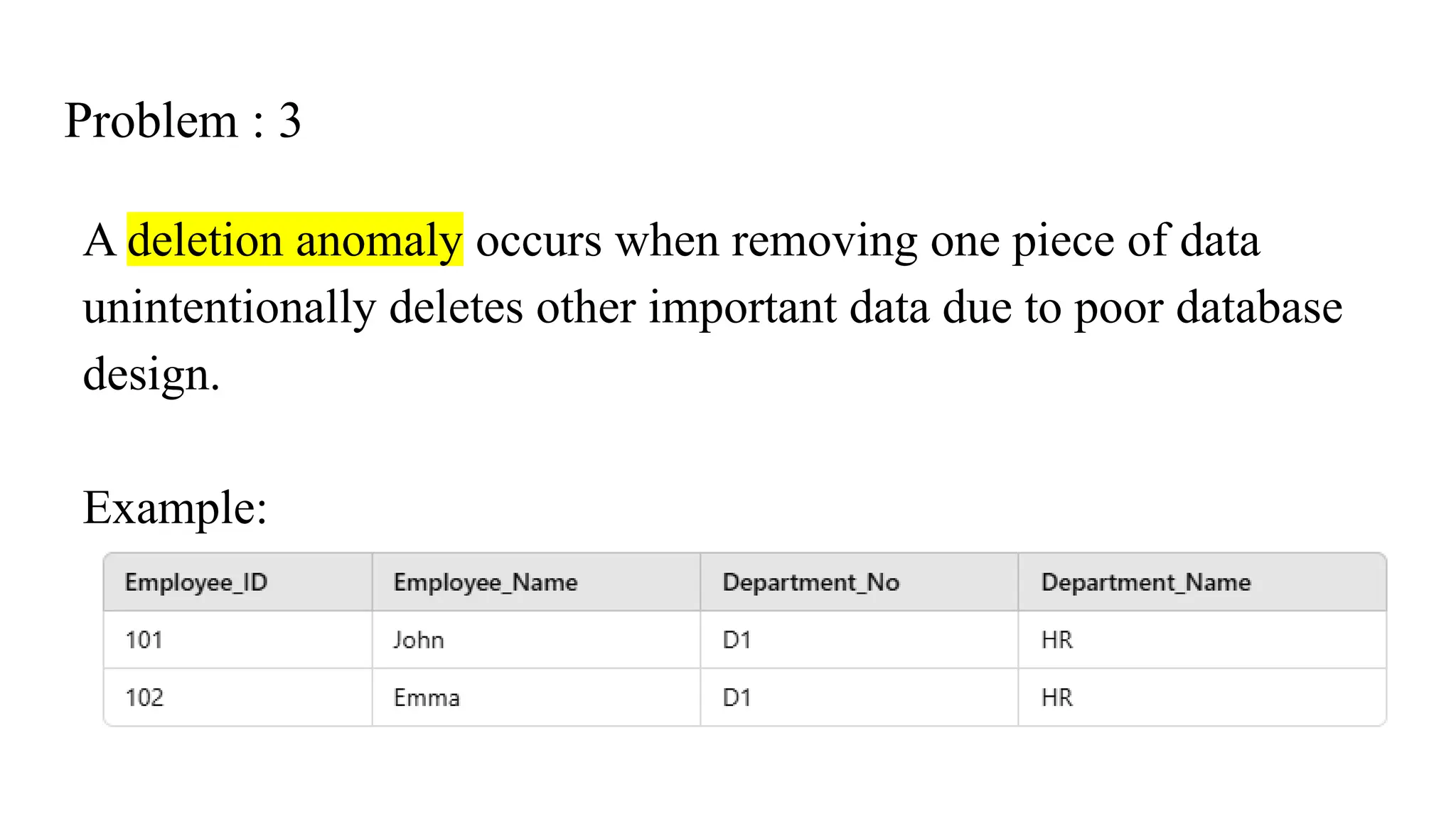
Problem : 3
Adeletion anomaly occurs when removing one piece of data
unintentionally deletes other important data due to poor database
design.
Example:
24.
Explanation
Suppose if Iwanted to eliminate two person’s data who are working on the
same department, that department details itslef will get lost. but if we maintain a
seperate table for the department we can manage the details of the department
25.
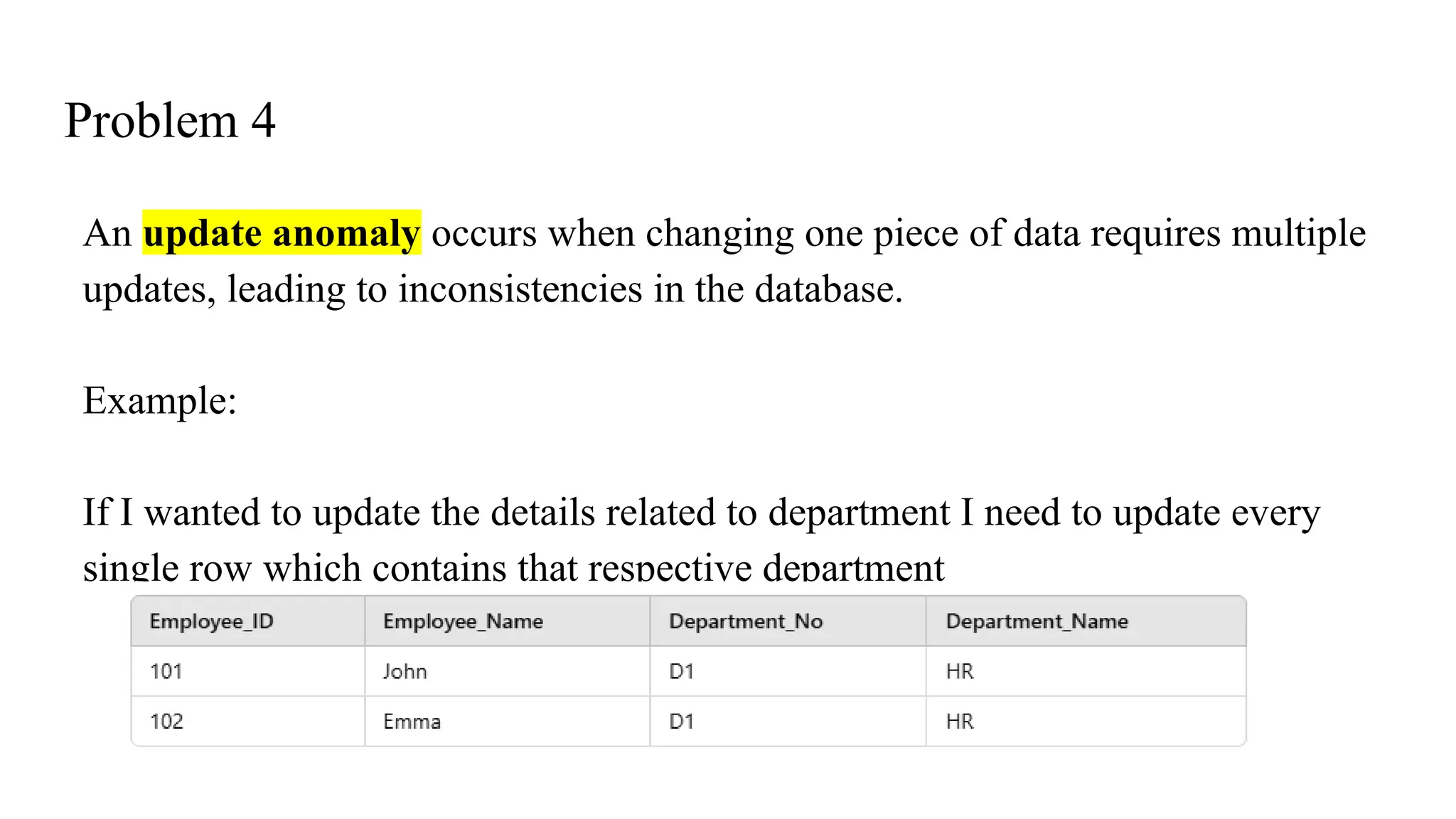
Problem 4
An updateanomaly occurs when changing one piece of data requires multiple
updates, leading to inconsistencies in the database.
Example:
If I wanted to update the details related to department I need to update every
single row which contains that respective department
26.
Guideline 2
Design asbase relation schema so that no insertion, deletion or
modification anomalies present in the relation. If any anomaly
exists make sure that the problem that update the database operate
correctly
27.
Null values ina tuple
● Null values lead to problems with understanding the meaning of the
attributes
Guideline 3:
As far as possible avoid placing attributes in a arelation whose values may
frequntly null. if null are unavoidable make sure that they do not apply to
majority of the tuples
28.
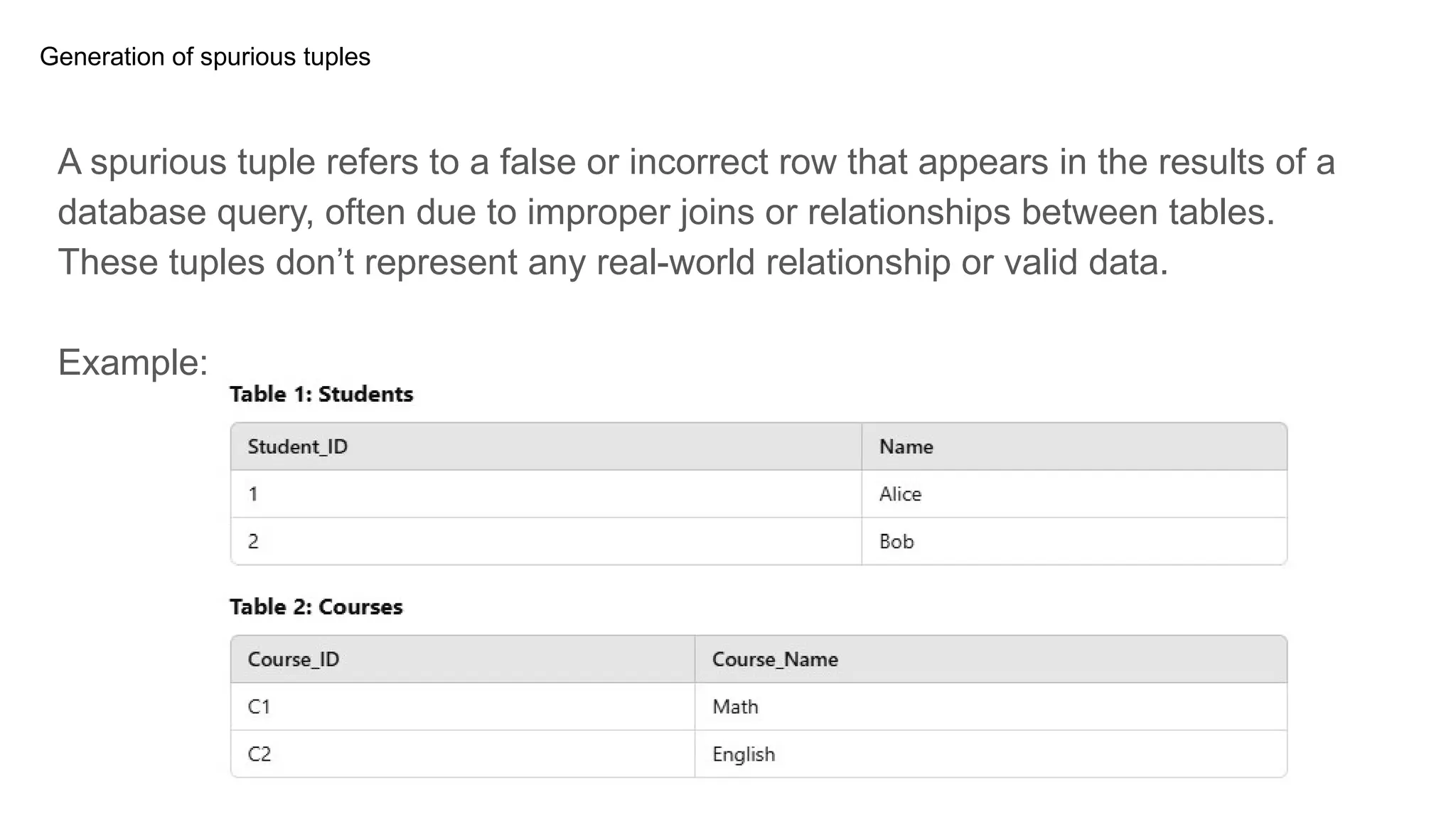
Generation of spurioustuples
A spurious tuple refers to a false or incorrect row that appears in the results of a
database query, often due to improper joins or relationships between tables.
These tuples don’t represent any real-world relationship or valid data.
Example:
29.
Explanation
From the abovetable if we use join operator to combine this both
table, we will get incorrect data as because we are not keeping
foreign key,
sp the only possible solution is to maintain a seprate table for the
enrollment or in the student table we can set course_id as a foreign
key
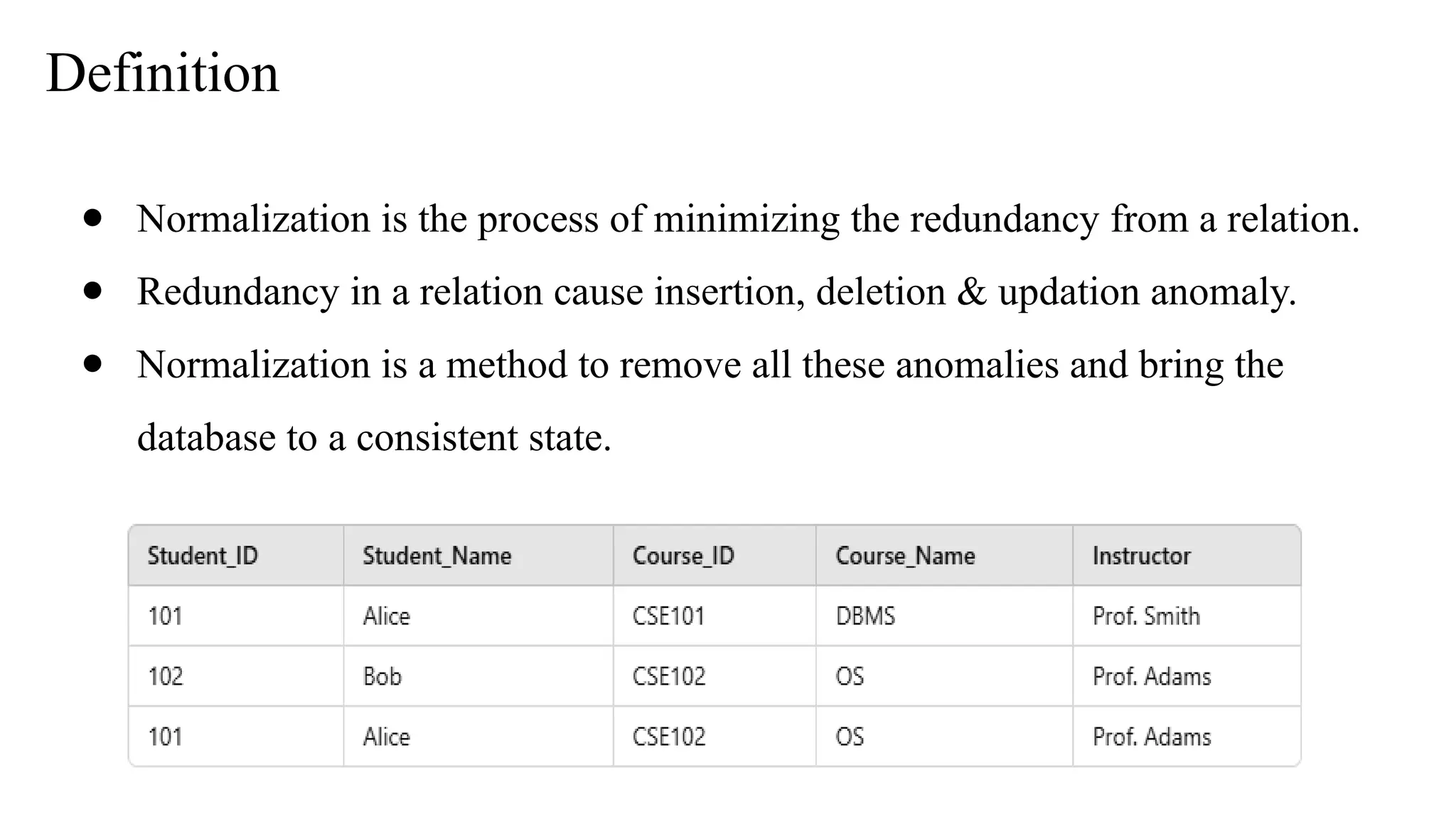
Definition
● Normalization isthe process of minimizing the redundancy from a relation.
● Redundancy in a relation cause insertion, deletion & updation anomaly.
● Normalization is a method to remove all these anomalies and bring the
database to a consistent state.
32.
The standard normalforms used are:
● First normal form (INF)
● Second normal form (2NF)
● Third normal form (3NF)
● Boyce-codd normal form (BCNF)
33.
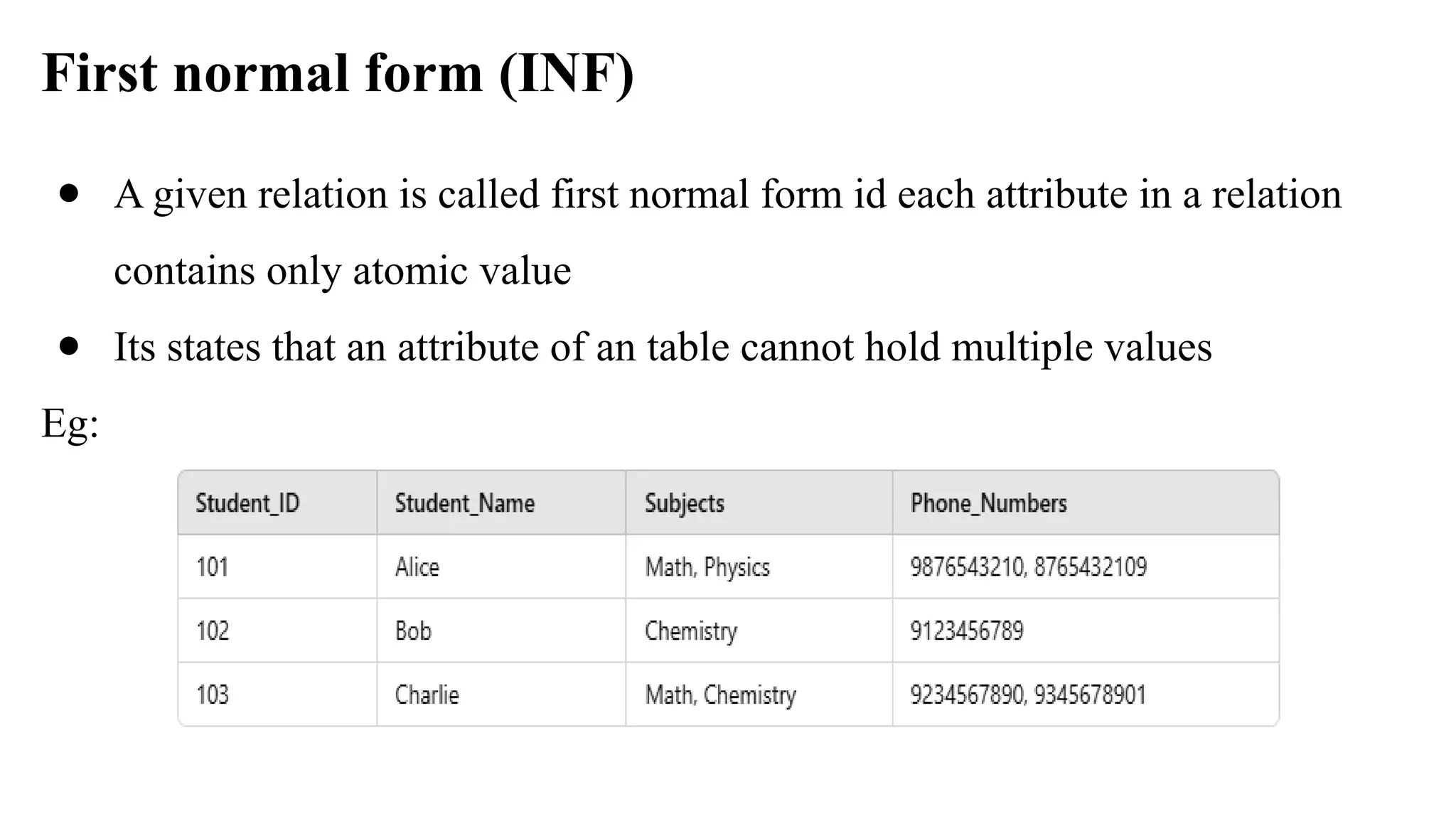
First normal form(INF)
● A given relation is called first normal form id each attribute in a relation
contains only atomic value
● Its states that an attribute of an table cannot hold multiple values
Eg:
34.
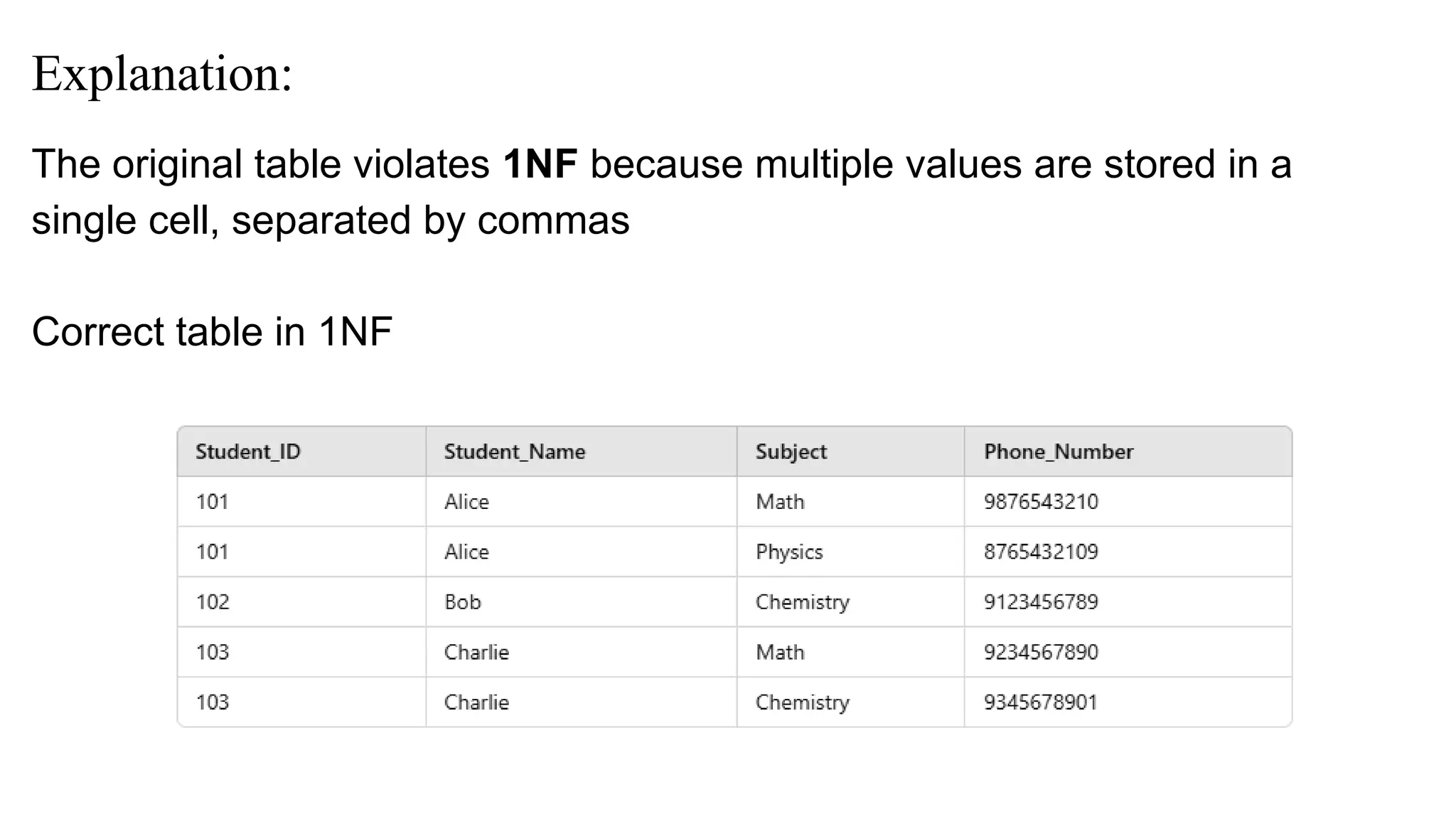
Explanation:
The original tableviolates 1NF because multiple values are stored in a
single cell, separated by commas
Correct table in 1NF
35.
Note:
1NF only removesrepeating groups, but to eliminate redundancy, we
need to go further into 2NF and beyond.
36.
Second normal form(2NF)
A table is said to be in 2nf if,
● It is already in First Normal Form (1NF)
● It has no Partial Dependencies—every non-key column must depend
on the whole Primary Key, not just part of it.
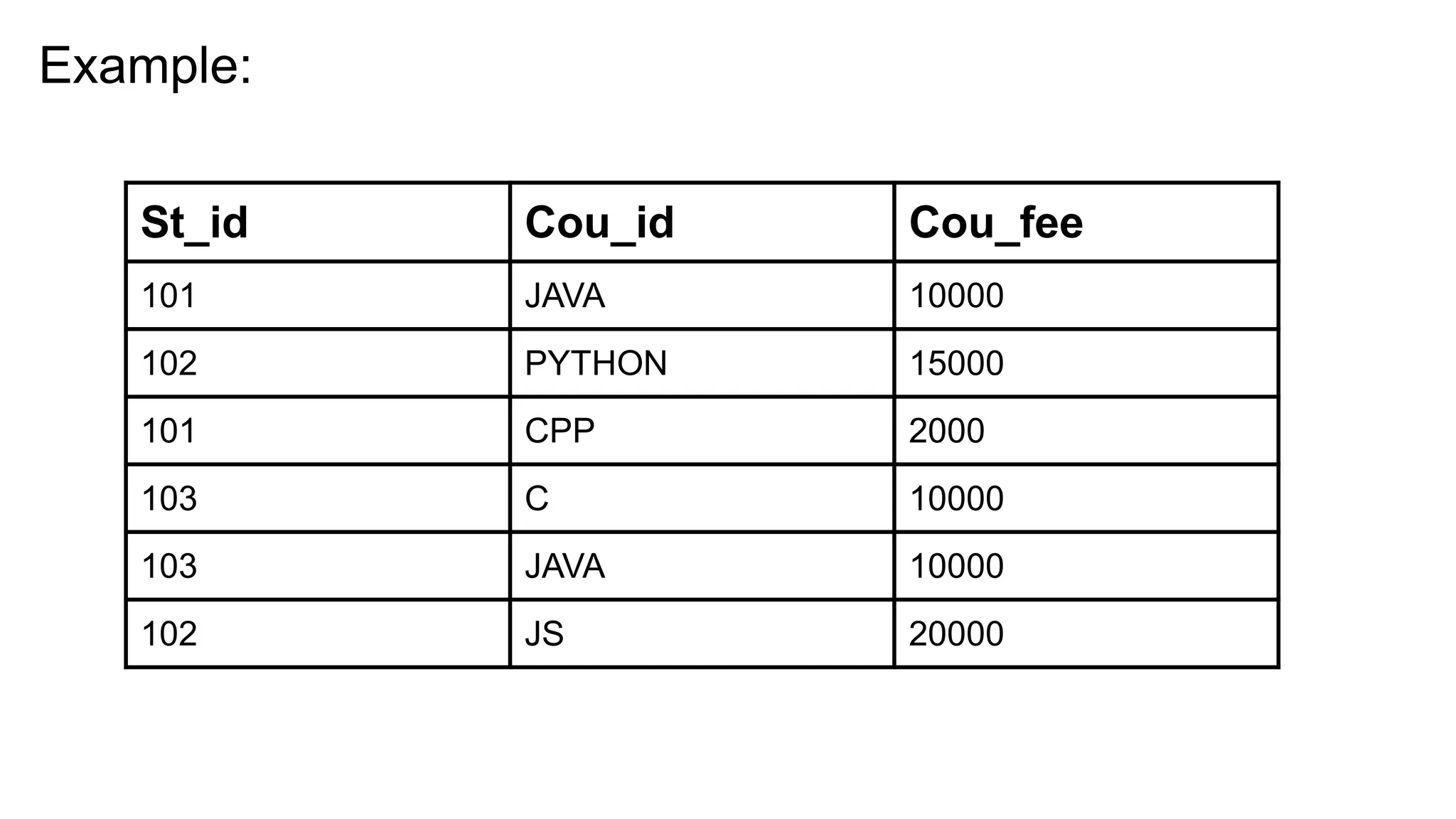
From the aboveresult will take St_id, Cou_id -> Cou_fee
, as we are having multiple determinant.
So here we need to prove that X,Y -> Z which means
X -> Z & Y -> Z
Ie,
St_id -> Cou_fee
Cou_id -> Cou_fee
41.
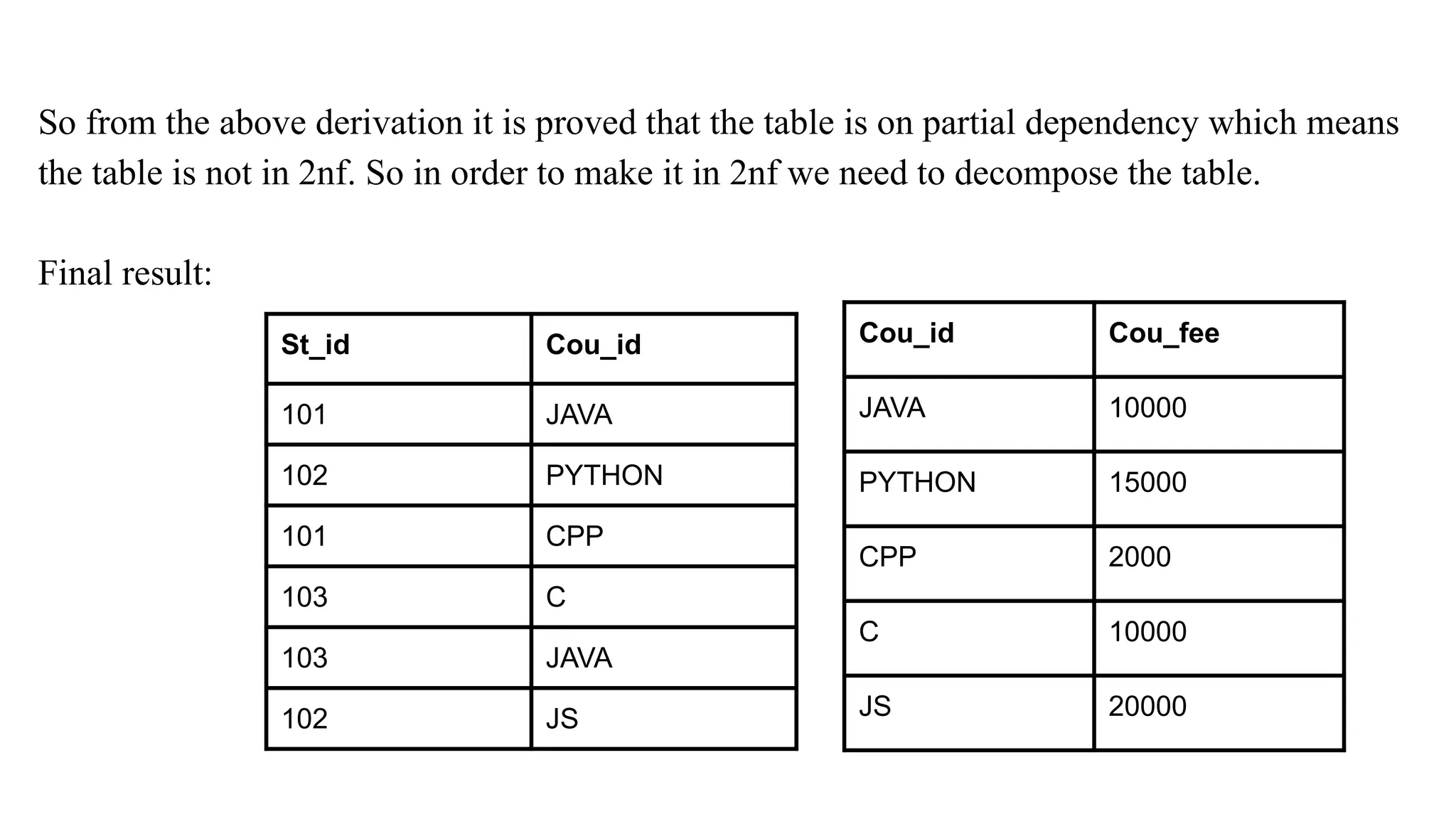
So from theabove derivation it is proved that the table is on partial dependency which means
the table is not in 2nf. So in order to make it in 2nf we need to decompose the table.
Final result:
St_id Cou_id
101 JAVA
102 PYTHON
101 CPP
103 C
103 JAVA
102 JS
Cou_id Cou_fee
JAVA 10000
PYTHON 15000
CPP 2000
C 10000
JS 20000
42.
Third normal form(3NF)
A relation is in Third Normal Form (3NF) if it satisfies Second Normal Form (2NF)
and does not have transitive dependencies. Formally, a relation is in 3NF if:
1. It is in 2NF (i.e., it has no partial dependencies).
2. It does not have transitive dependencies, meaning:
○ For every non-prime attribute (an attribute that is not part of any candidate
key),
○ It must be fully functionally dependent on the primary key and not on any
other non-key attribute.
43.
Example 1:
In theabove example, we can write the functional dependency like,
Student_id -> Stude_Name, Department, HOD_Name
Likewise, we can create other decompositions, but the key issue arises when there exists a
functional dependency (FD) between two non-prime attributes. This creates a transitive
dependency, which violates 3NF.
44.
Ie, in theabove example, when we consider department and HOD_Name,
both attributes are depending on each other means, if I wanted to know the
HOD_Name I wanted to know the Department_Name, which makes
transitive dependency.
Department_Name -> HOD_Name
Therefore, we can solve this problem by decomposing the table as follows:
Next page…………..
45.
Note: This decompositionsatisfies 3NF and here, in the second
table department will act as PK which will FK in student table
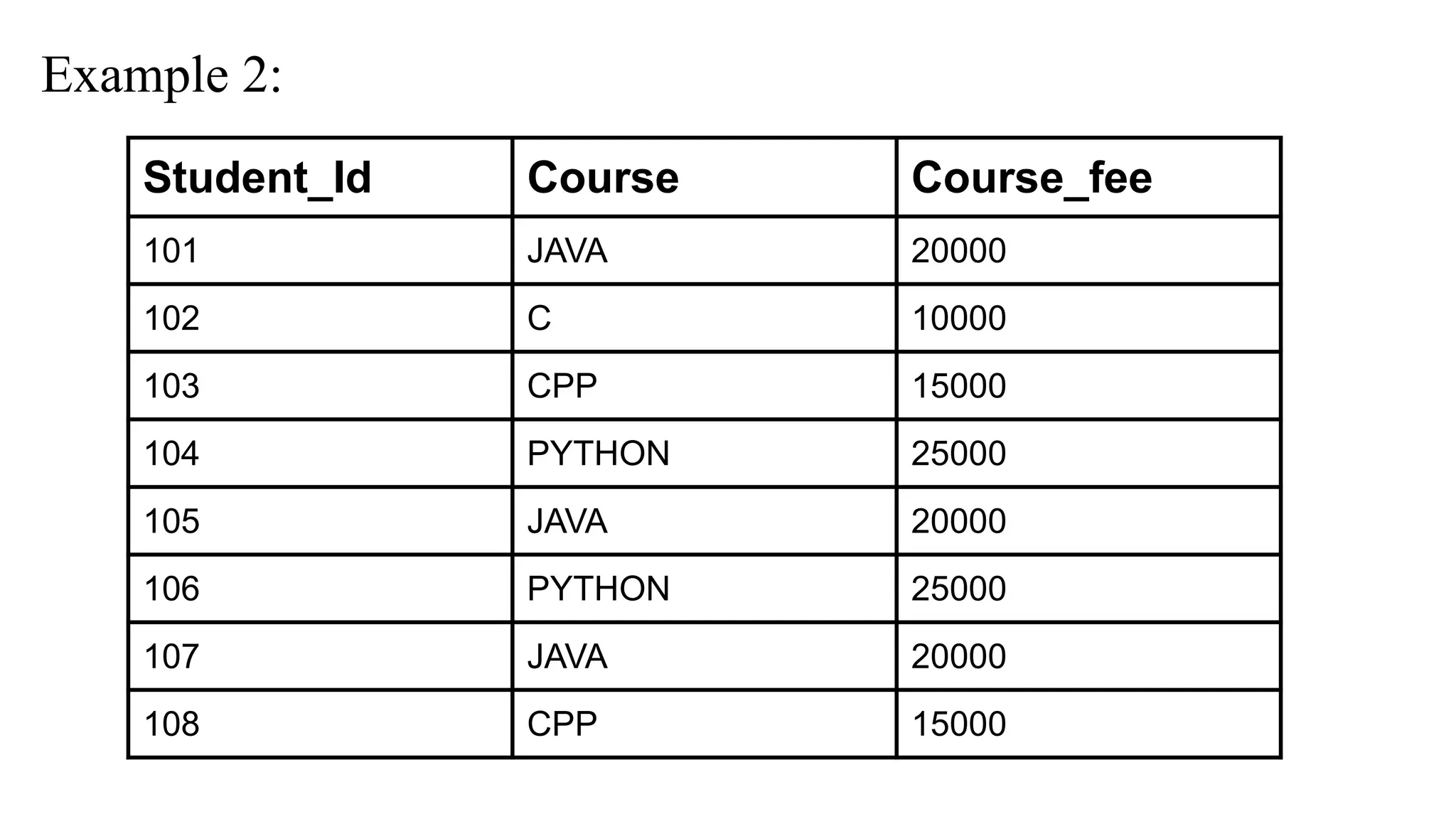
Explanation:
In the adobeexample, when we write the transitive dependency lile,
Student_id -> Course
Course -> Course_fee
Then, Student_id -> Course_fee
This will make transitive dependency as Course_fee depends on Course
because Course_fee is derived from Course not from student_id, which
violates 3NF
48.
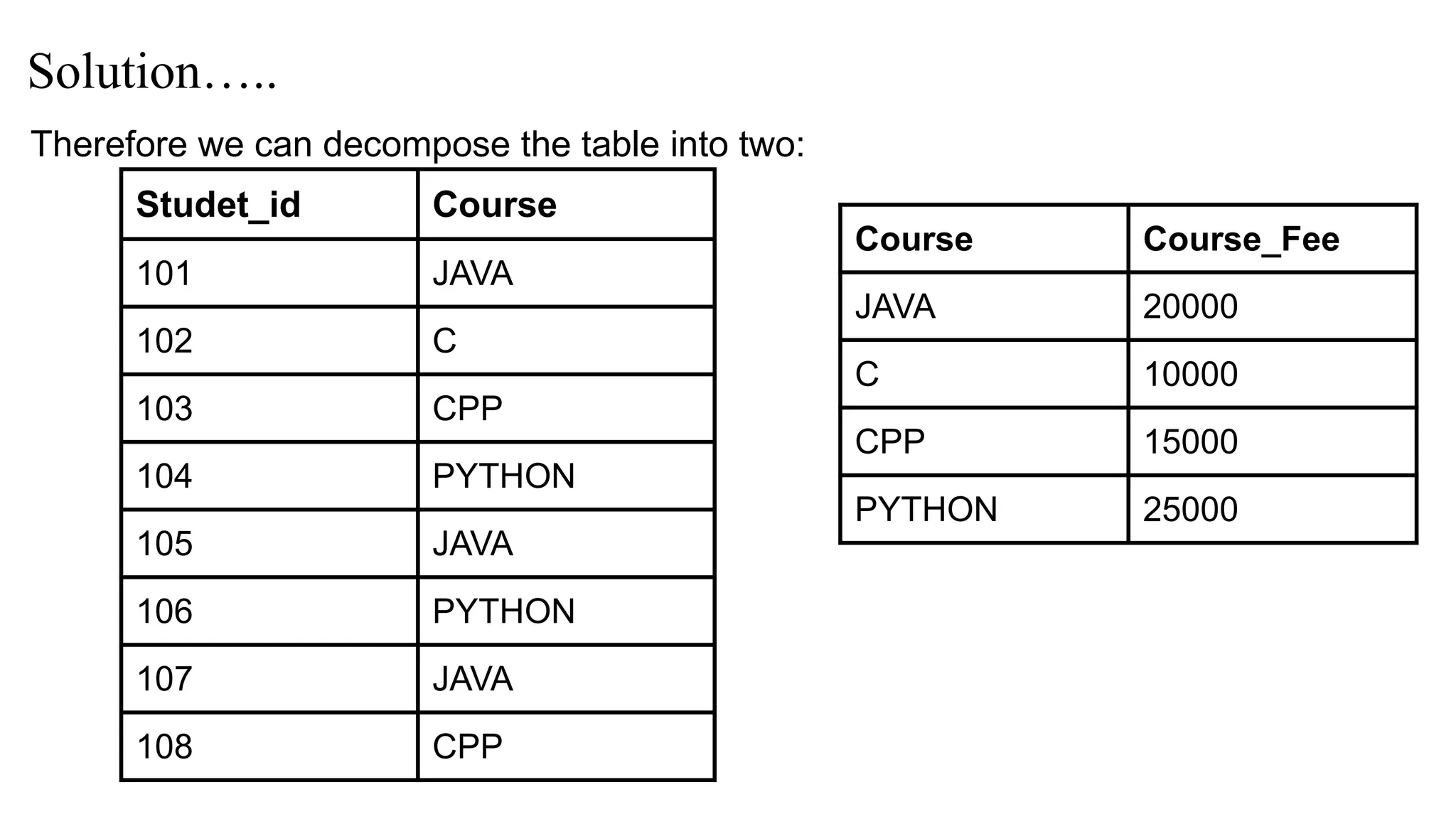
Solution…..
Therefore we candecompose the table into two:
Studet_id Course
101 JAVA
102 C
103 CPP
104 PYTHON
105 JAVA
106 PYTHON
107 JAVA
108 CPP
Course Course_Fee
JAVA 20000
C 10000
CPP 15000
PYTHON 25000
49.
BCNF (Boyce CoddNormal Form)
BCNF (Boyce-Codd Normal Form) is also called 3.5NF because it is a stricter version of
3NF
A table is said to be in BCNF if,
● It satisfies 3NF
● A relation is in BCNF (Boyce-Codd Normal Form) if and only if, for every
functional dependency (X → Y), X is a superkey.
Note: A super key is a set of one or more attributes that can uniquely identify each row in
a table
50.
Consider the example
Student_ID-> Name, Email
(Student_ID, Name) -> Email
(Student_ID, Email) -> Name
Here Student_ID can act as a super key alone or with a combination of other attributes
51.
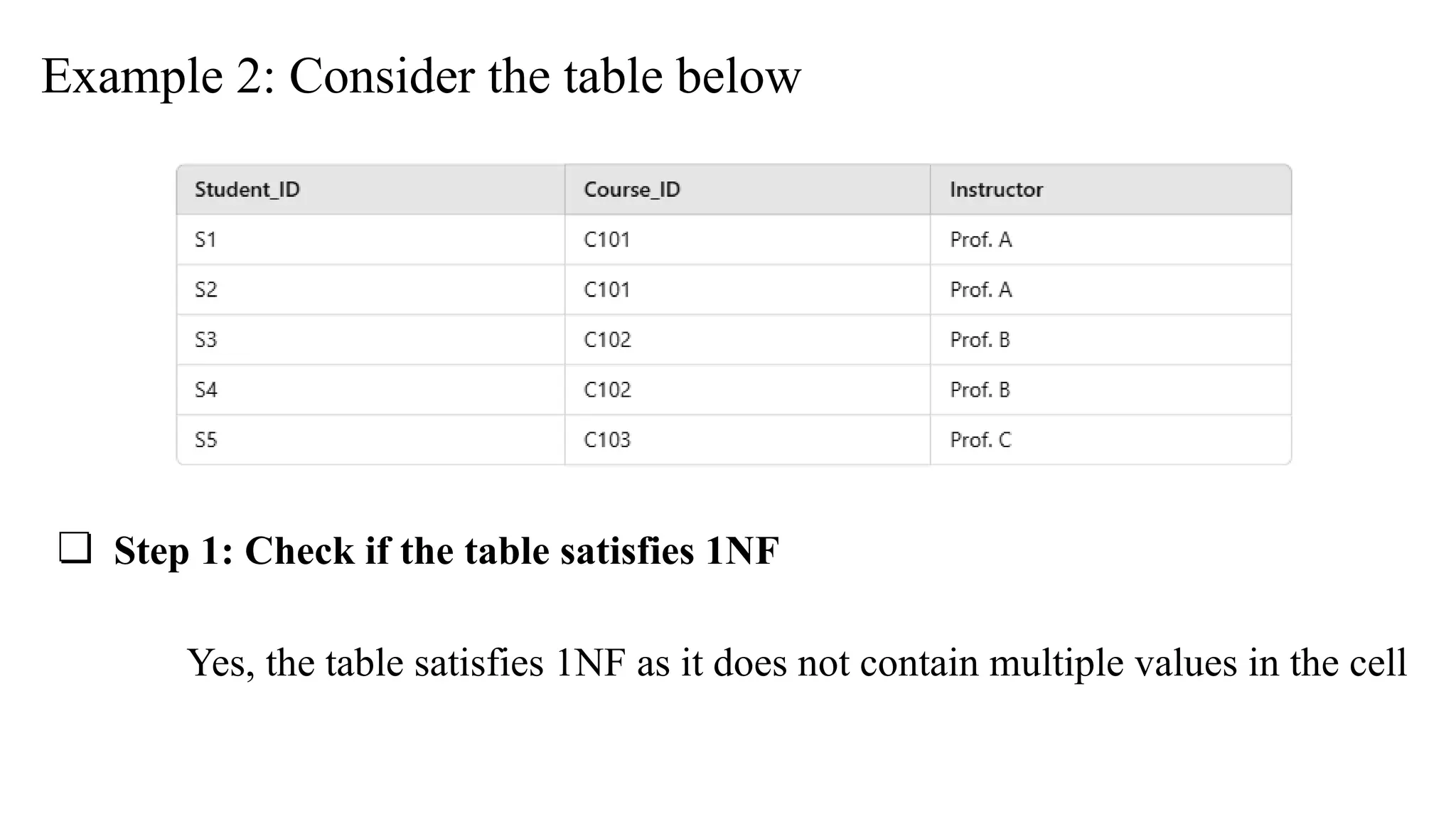
Example 2: Considerthe table below
❏ Step 1: Check if the table satisfies 1NF
Yes, the table satisfies 1NF as it does not contain multiple values in the cell
52.
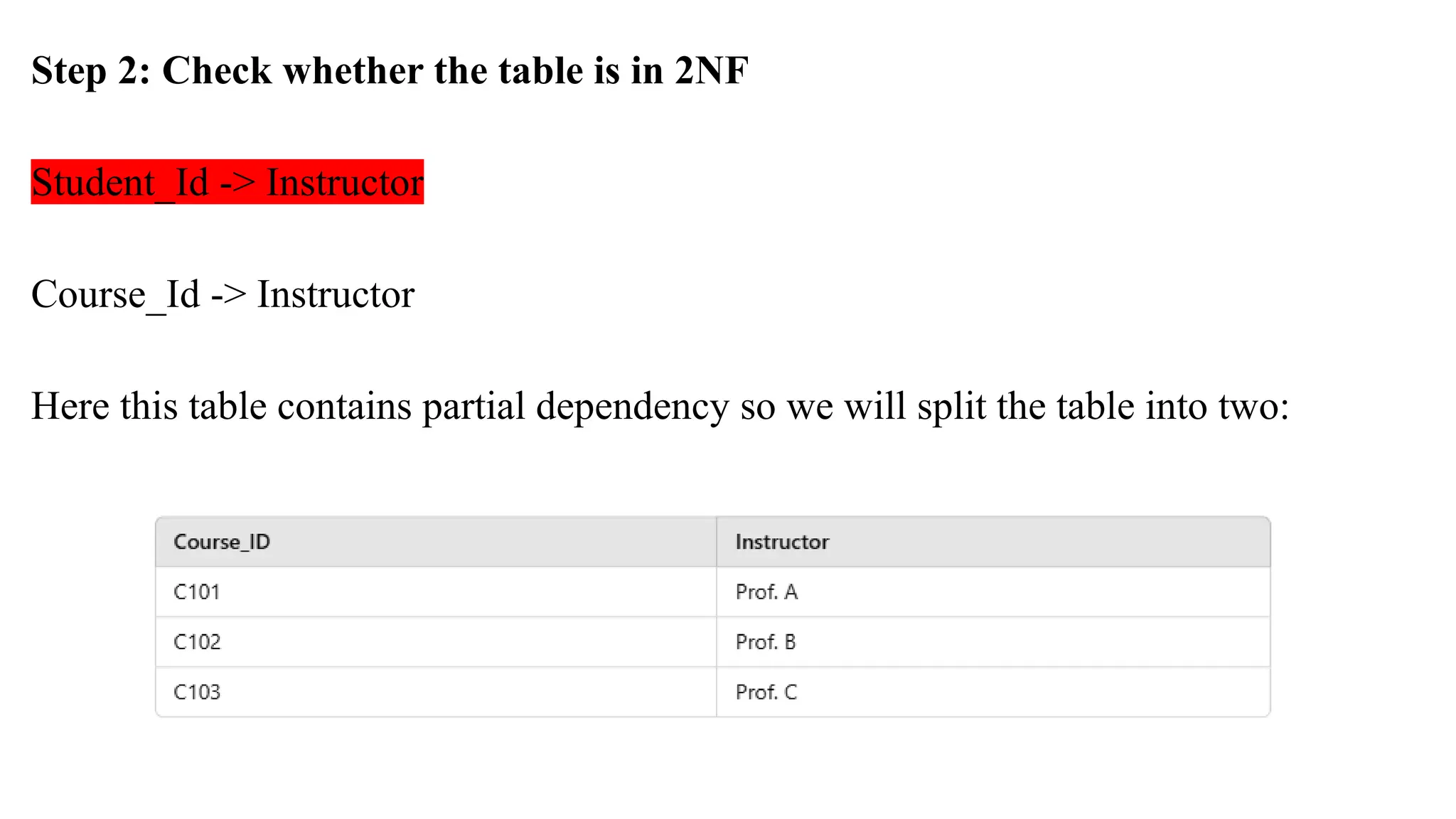
Step 2: Checkwhether the table is in 2NF
Student_Id -> Instructor
Course_Id -> Instructor
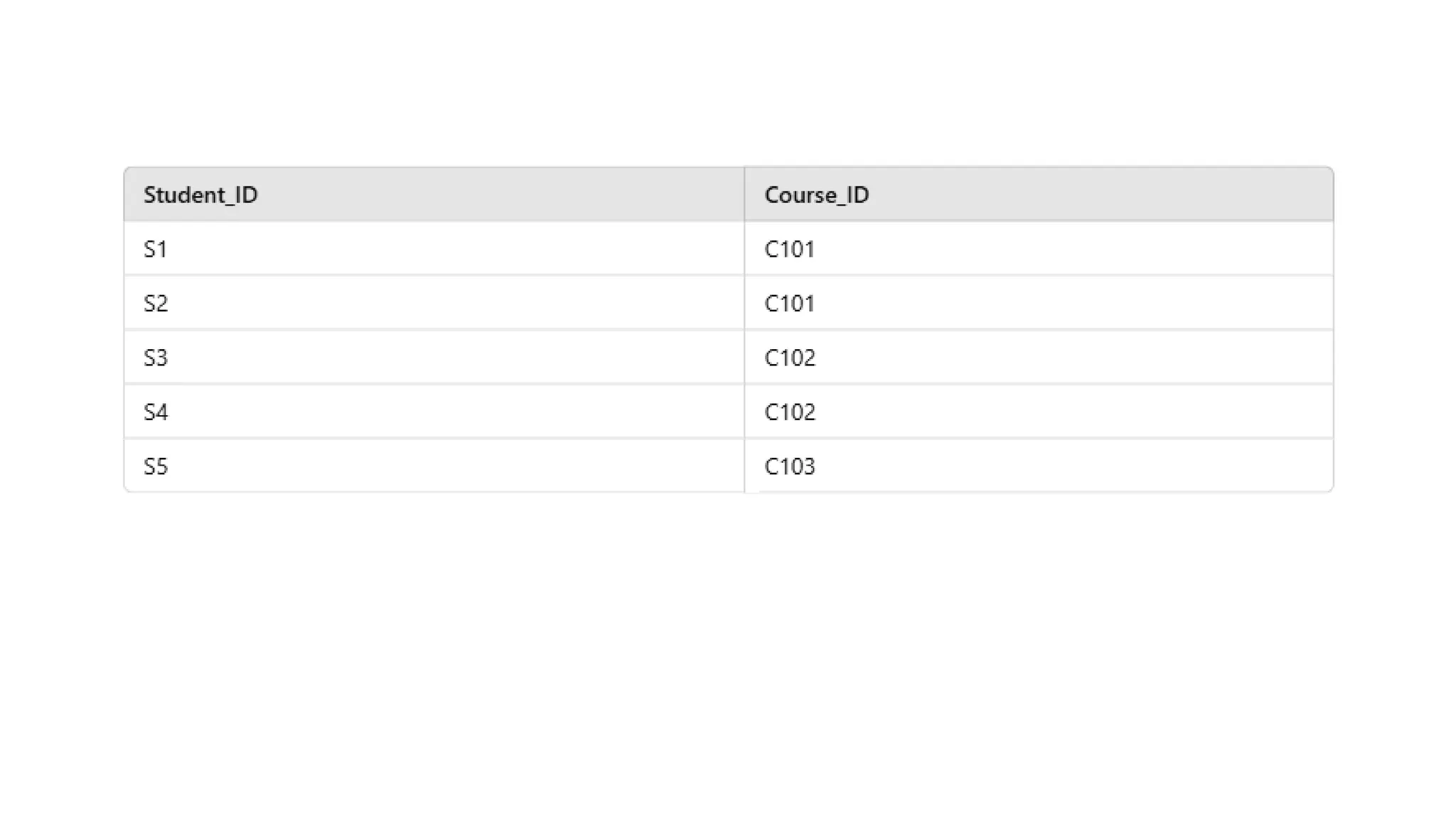
Here this table contains partial dependency so we will split the table into two:
54.
Step 3: Checkif it is in 3NF
Yes, because there is no dependency between NP & NP
Step 4: Check if it is in BCNF
Yes, here we can write the FD as follows:
Studet_id -> Course_id (Here both Studet_id & Course_id act as Super key)
Course_id -> Instructor (Here both Course_id & Instructor act as Super key)







![Armstrong's Axioms
● Reflexivity
A -> B , B will be the subset of A
Let A = stu_id, B =
● Augmentation
If A -> B then, A C -> BC
● Transitivity
If A -> B and B -> C then A -> C [B should be a non-prime attribute]](https://image.slidesharecdn.com/module3dbms1-250428034919-a77eaf90/75/DBMS_Module-3_Functional-Dependencies-and-Normalization-pptx-12-2048.jpg)