Downloaded 224 times





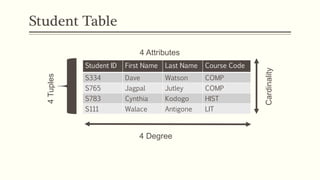
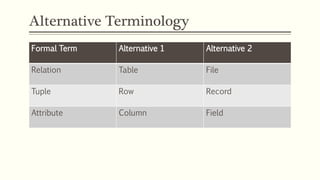









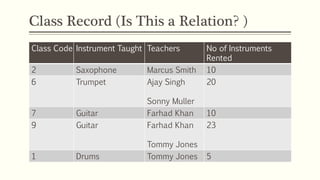

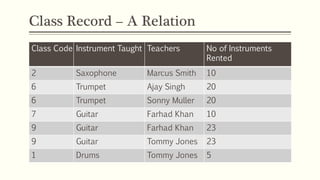


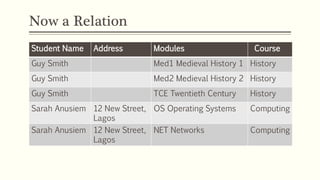




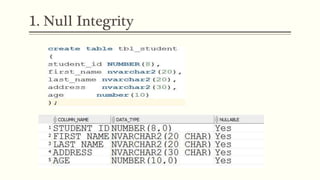
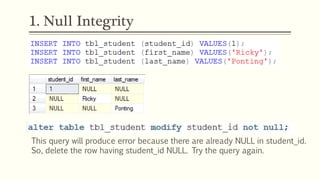
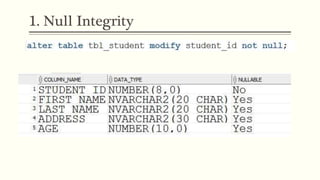




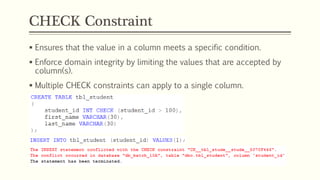
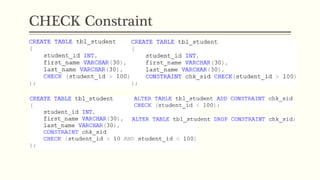




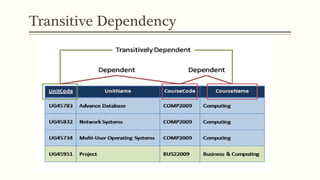
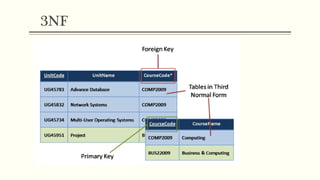

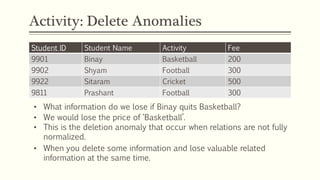



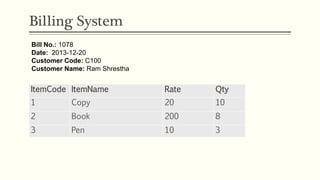
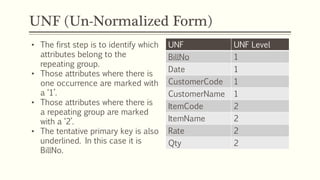
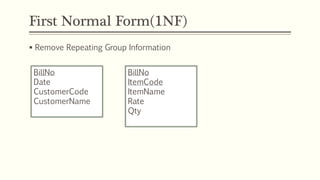


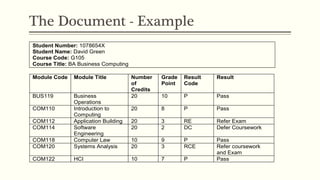
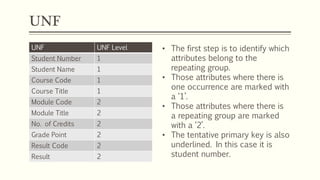

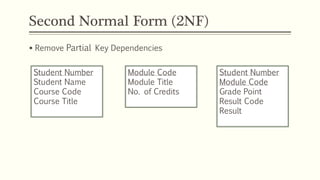
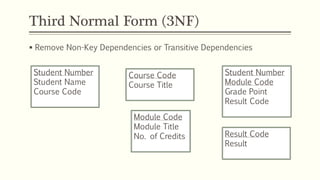
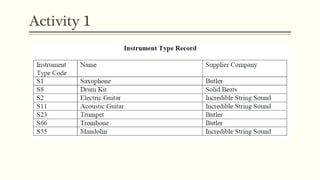
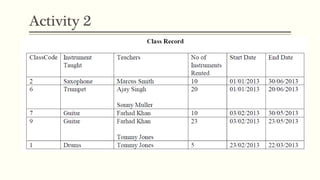
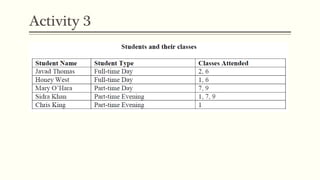






This document provides an example of student records in an unnormalized form, containing repeating groups. It then demonstrates normalizing the data by removing the repeating groups into multiple tables in first normal form. Further normalization results in separating attributes with partial dependencies and non-key dependencies into their own tables, achieving second and third normal form respectively. The document explains the different normal forms and how normalization helps reduce data anomalies on insert, update and delete operations.











































































