Downloaded 1,947 times



















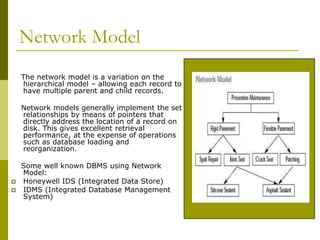


















This document provides an overview of database management systems and related concepts. It discusses data hierarchy, traditional file processing, the database approach to data management, features and capabilities of database management systems, database schemas, components of database management systems, common data models including hierarchical, network, and relational models, and the process of data normalization.
















































































