Downloaded 17 times

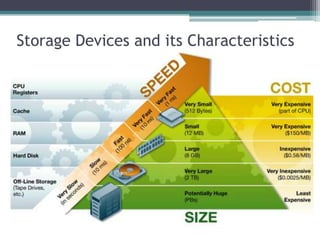




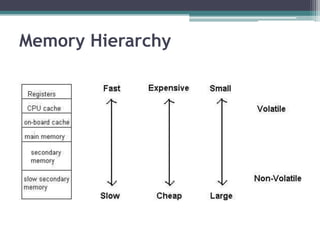




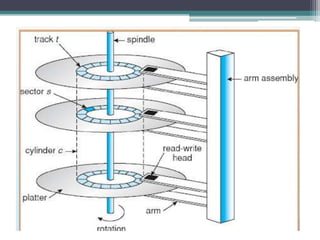
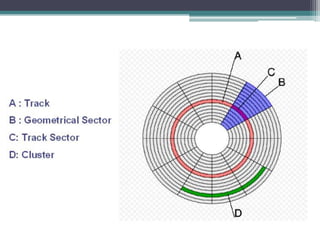
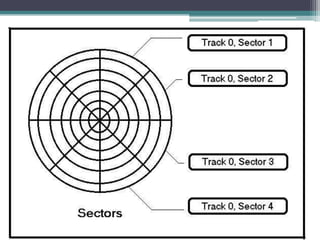
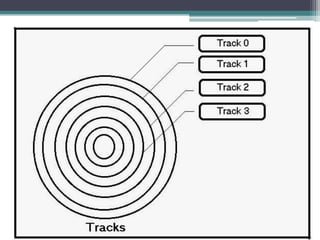
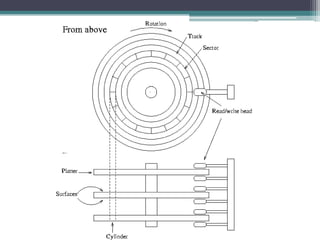
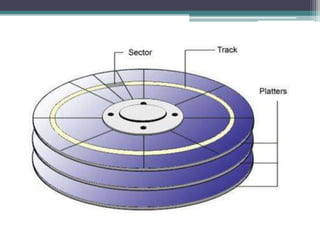
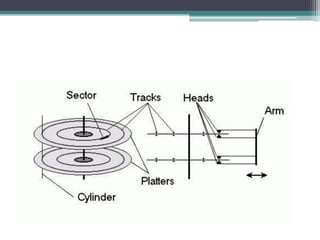
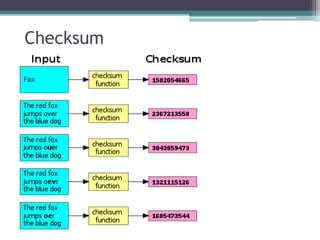

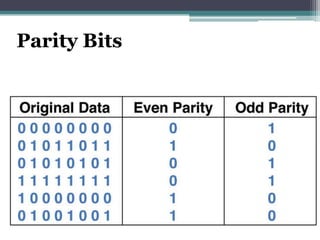

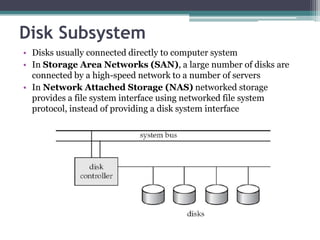









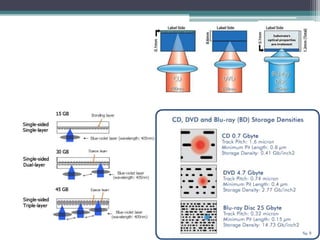

This document discusses file organization and storage hierarchy in conventional database management systems (DBMS). It describes the different levels of storage including primary storage (CPU registers, cache, memory), secondary storage (hard disks, removable media), tertiary storage (backup devices), and offline storage (tape, optical discs). The document also covers disk subsystem components like controllers, interfaces, RAID configurations, and performance optimization techniques for disk access.



















































































