Downloaded 500 times












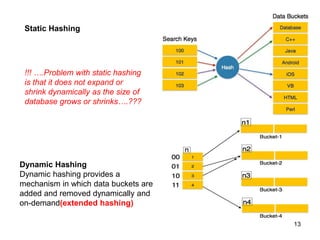
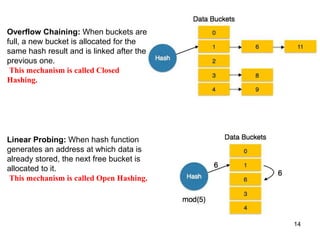
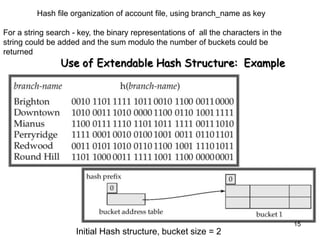

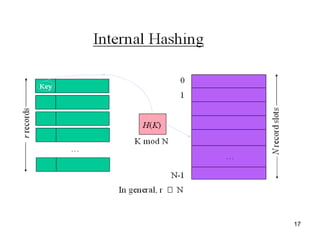

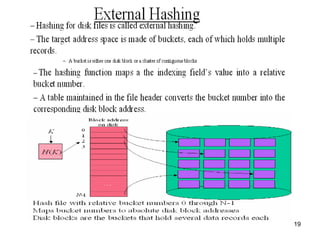









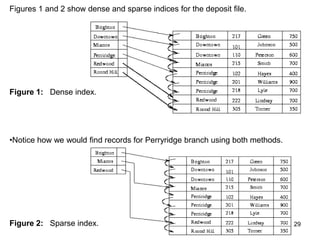




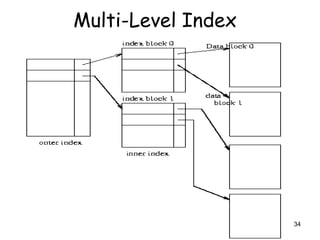


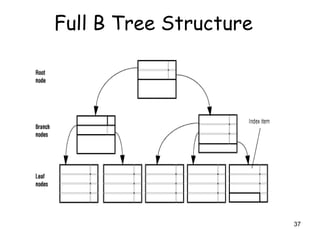


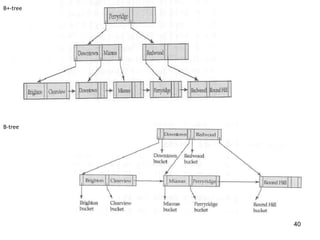

This document discusses different methods for organizing and indexing data stored on disk in a database management system (DBMS). It covers unordered or heap files, ordered or sequential files, and hash files as methods for physically arranging records on disk. It also discusses various indexing techniques like primary indexes, secondary indexes, dense vs sparse indexes, and multi-level indexes like B-trees and B+-trees that provide efficient access to records. The goal of file organization and indexing in a DBMS is to optimize performance for operations like inserting, searching, updating and deleting records from disk files.




























































































