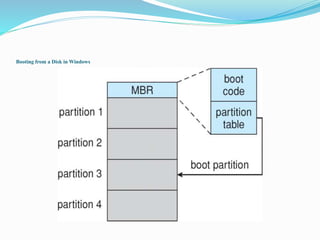
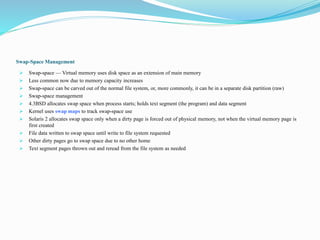
This document discusses mass storage systems and disk structure. It covers topics such as disk formatting, mapping logical blocks to physical sectors, disk attachment methods like SCSI and Fibre Channel, and disk scheduling algorithms. It also summarizes disk management techniques including partitioning, file systems, and swap space. Additional sections cover RAID configurations, stable storage implementation, and snapshot and replication features.