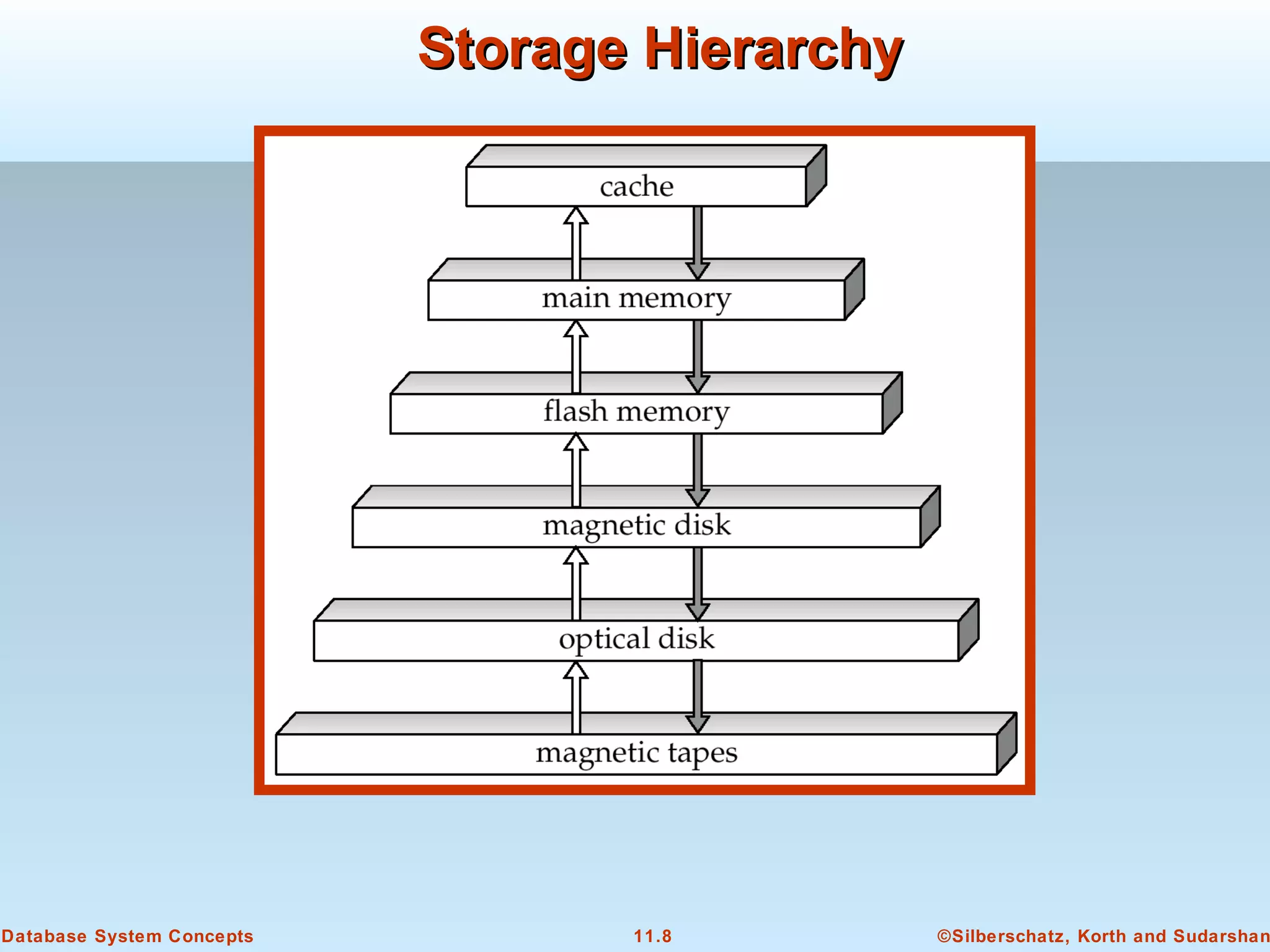
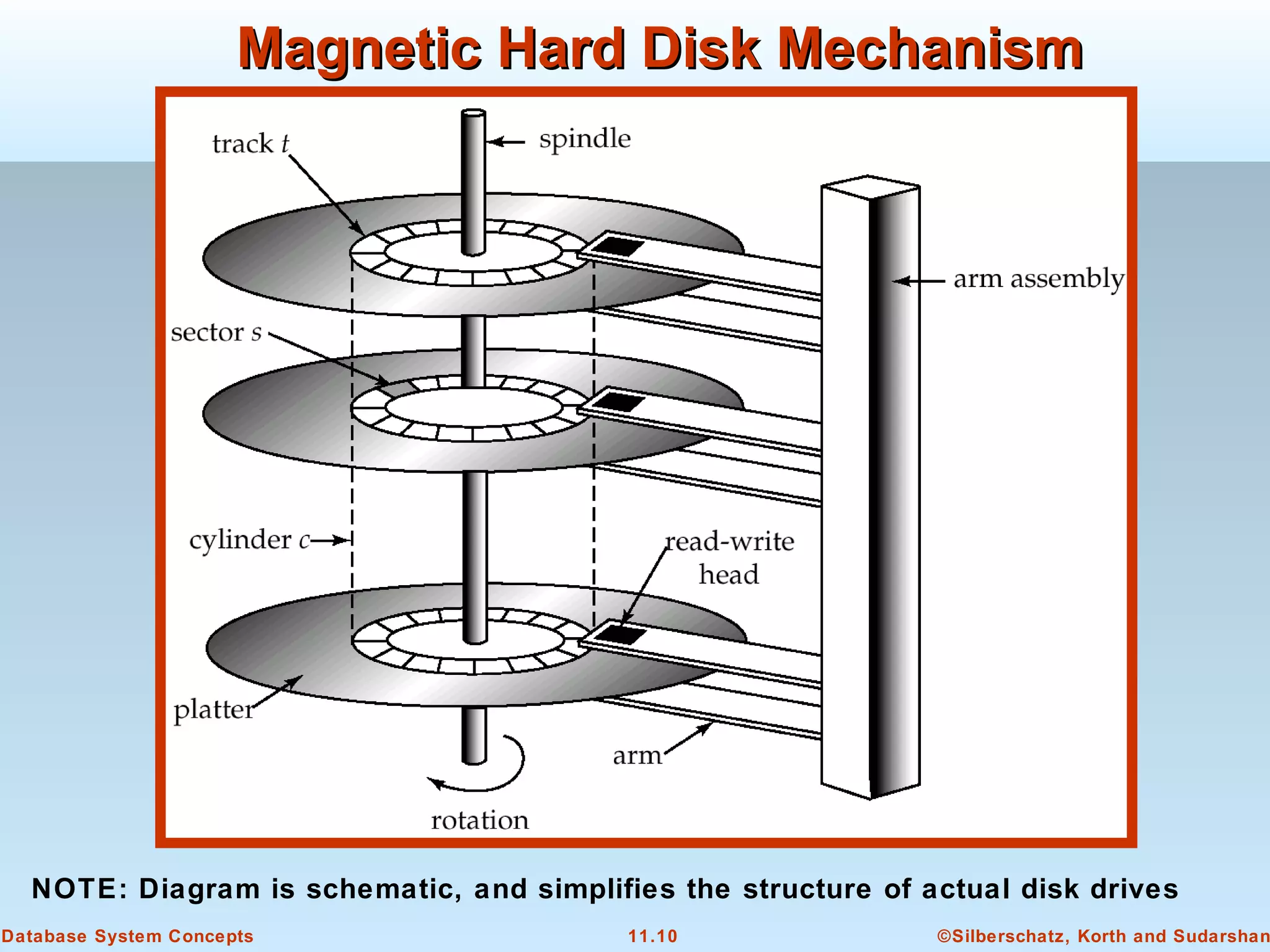
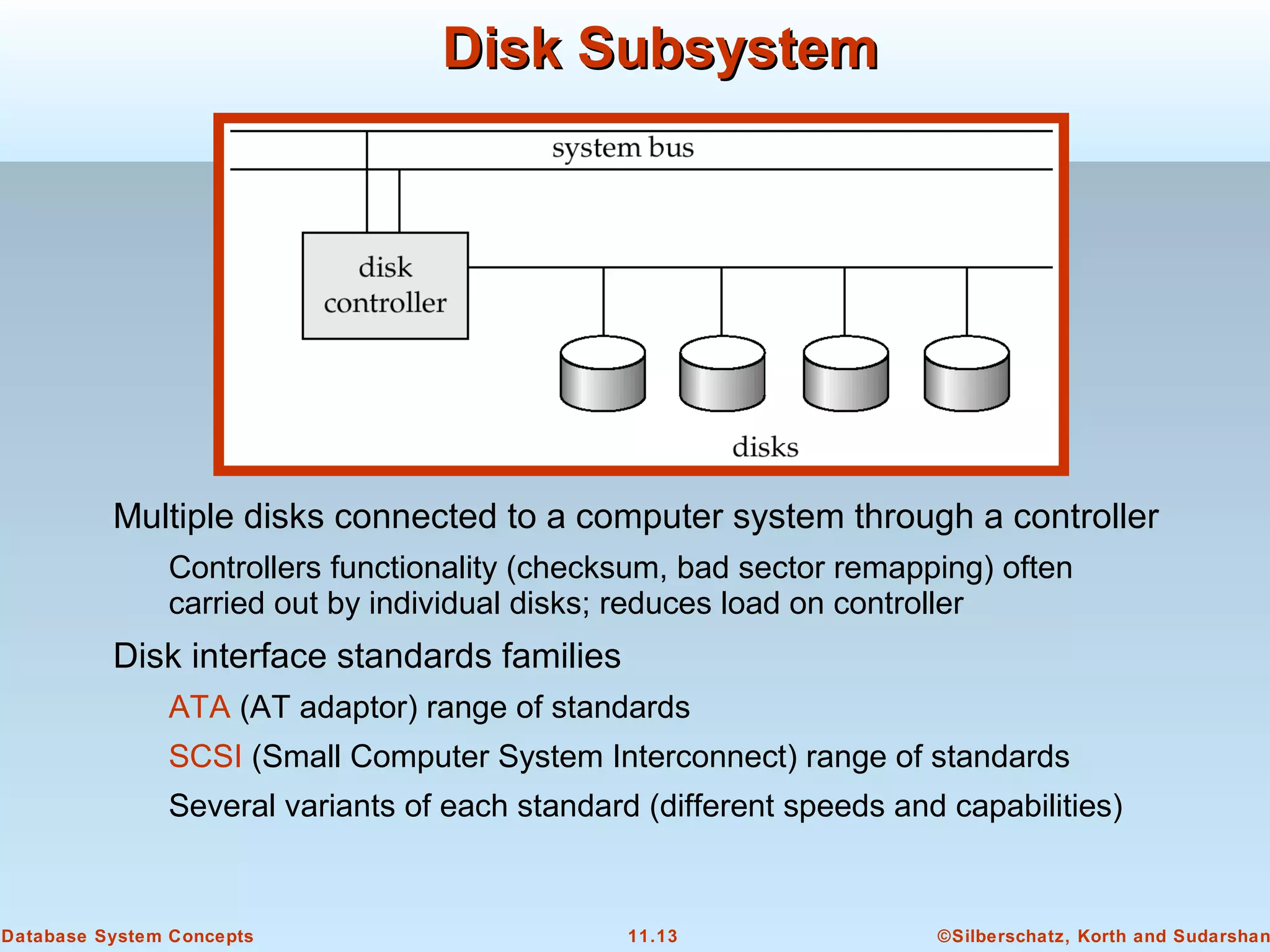
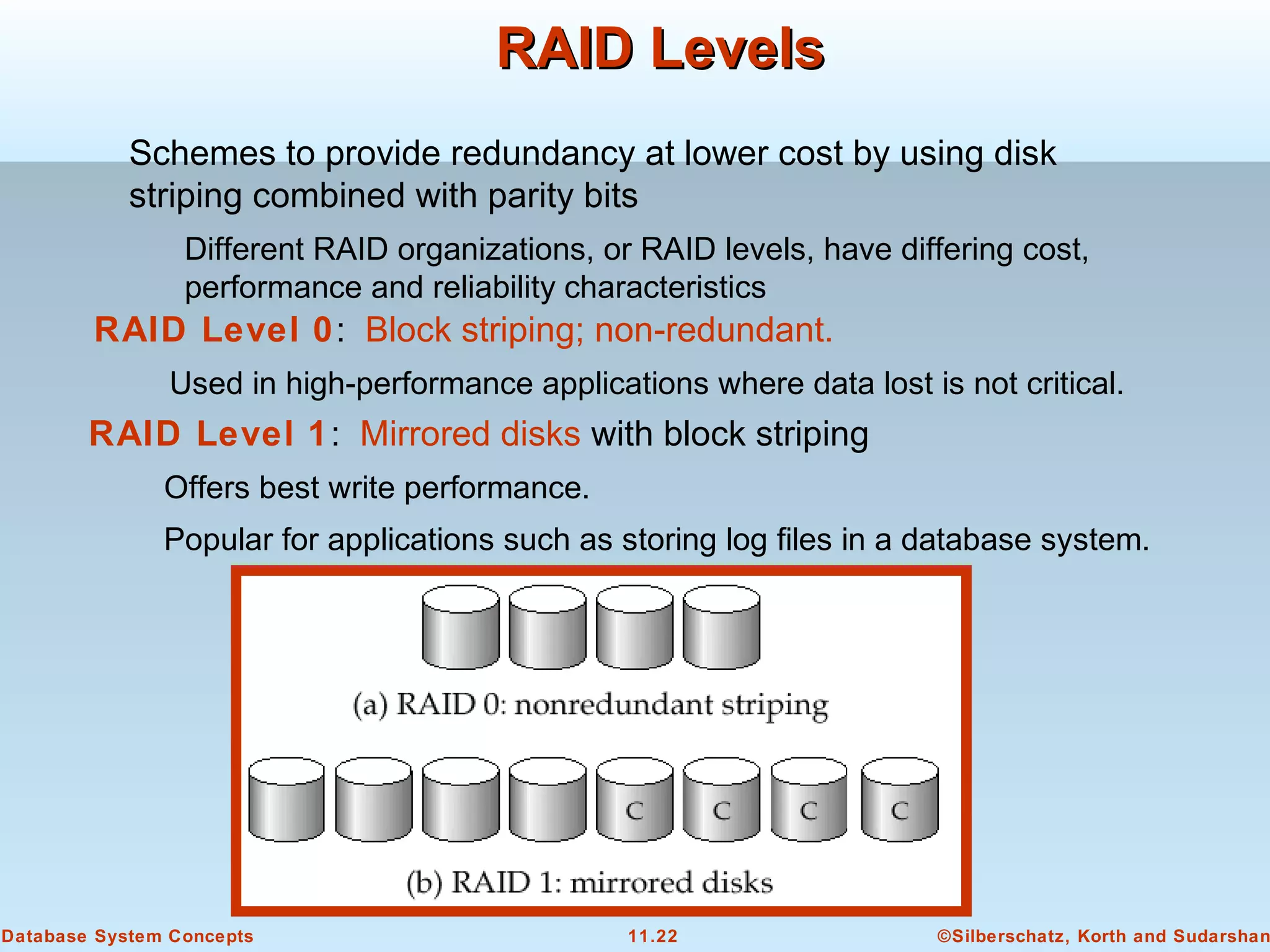
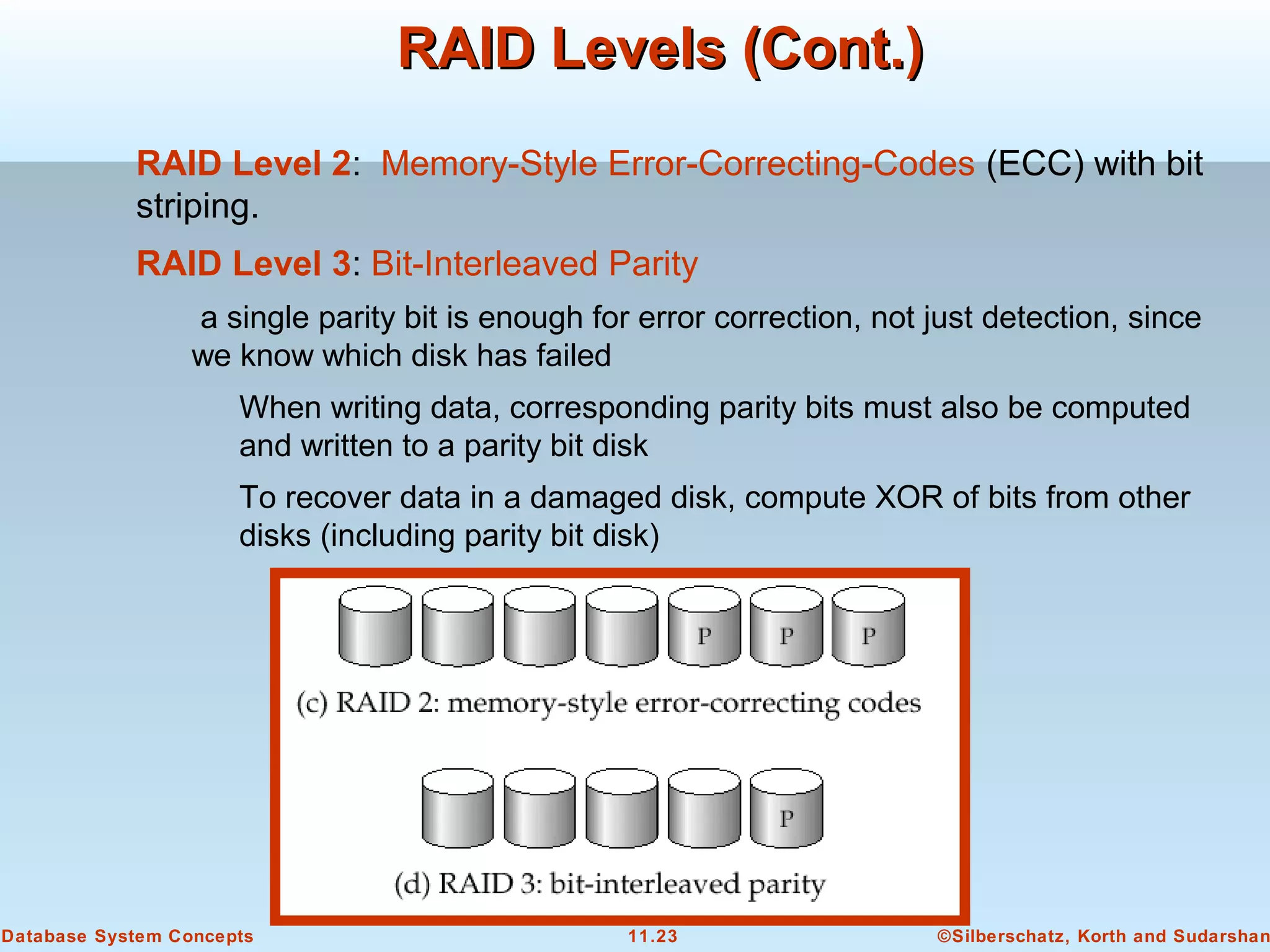
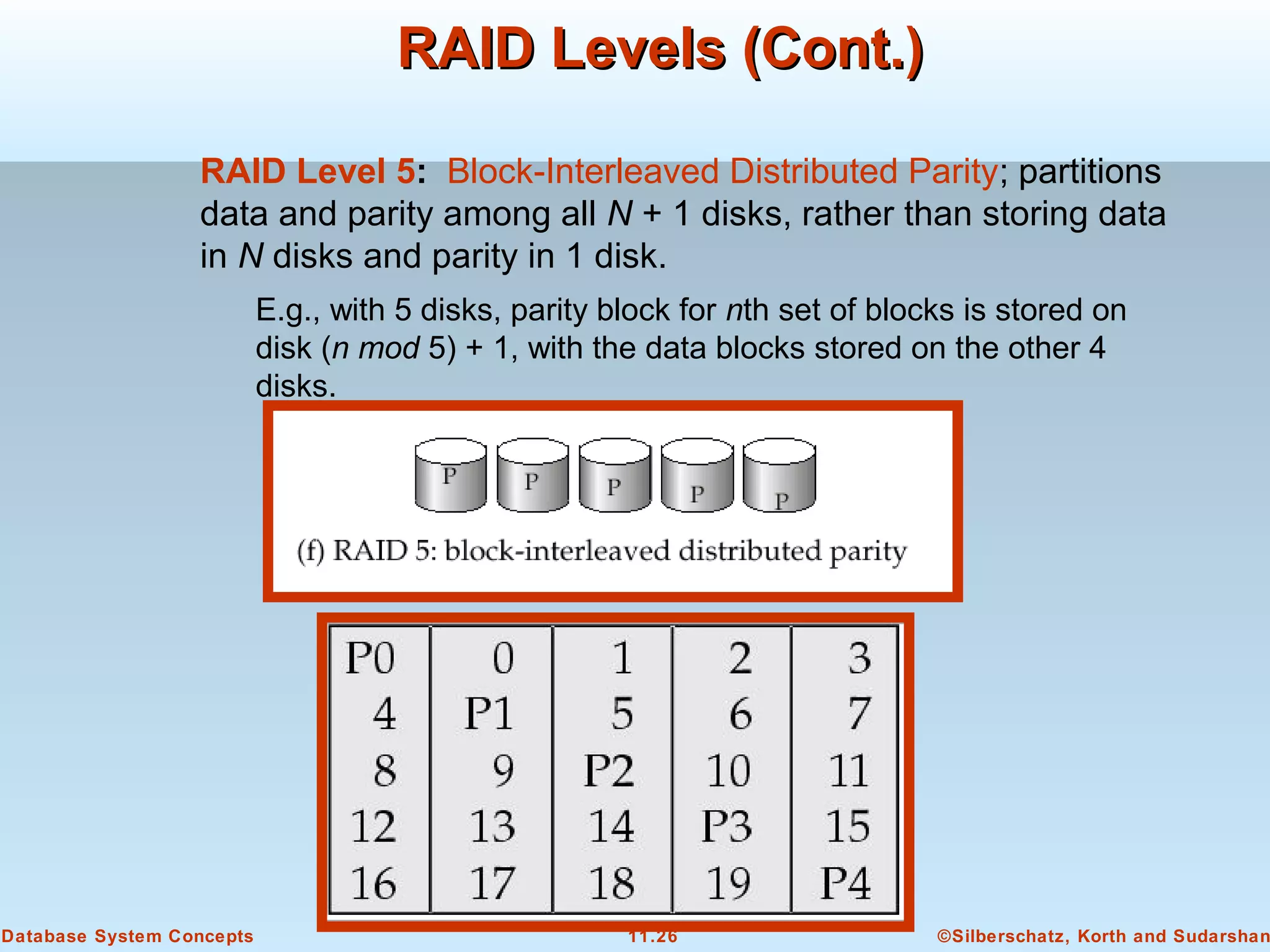
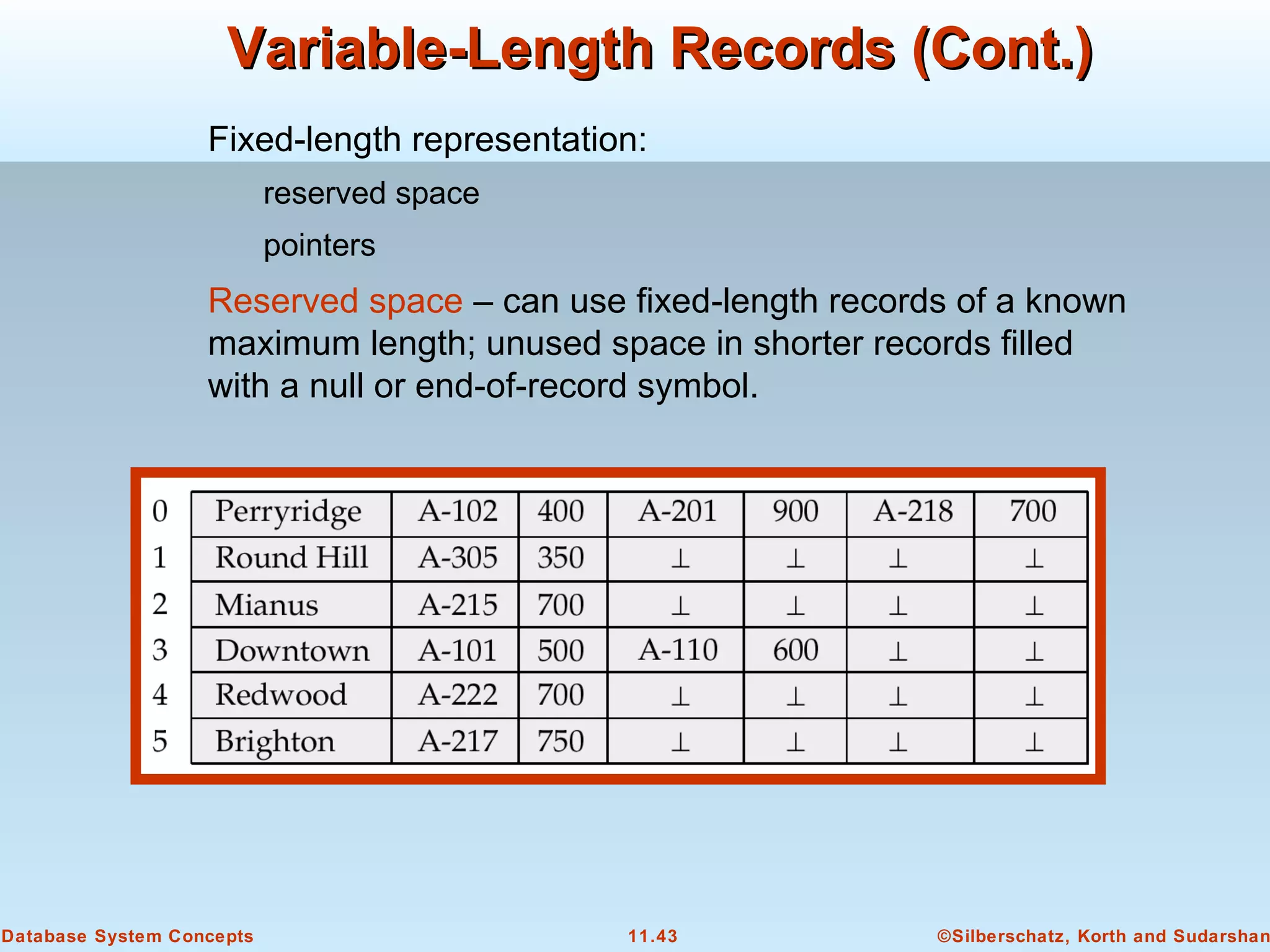
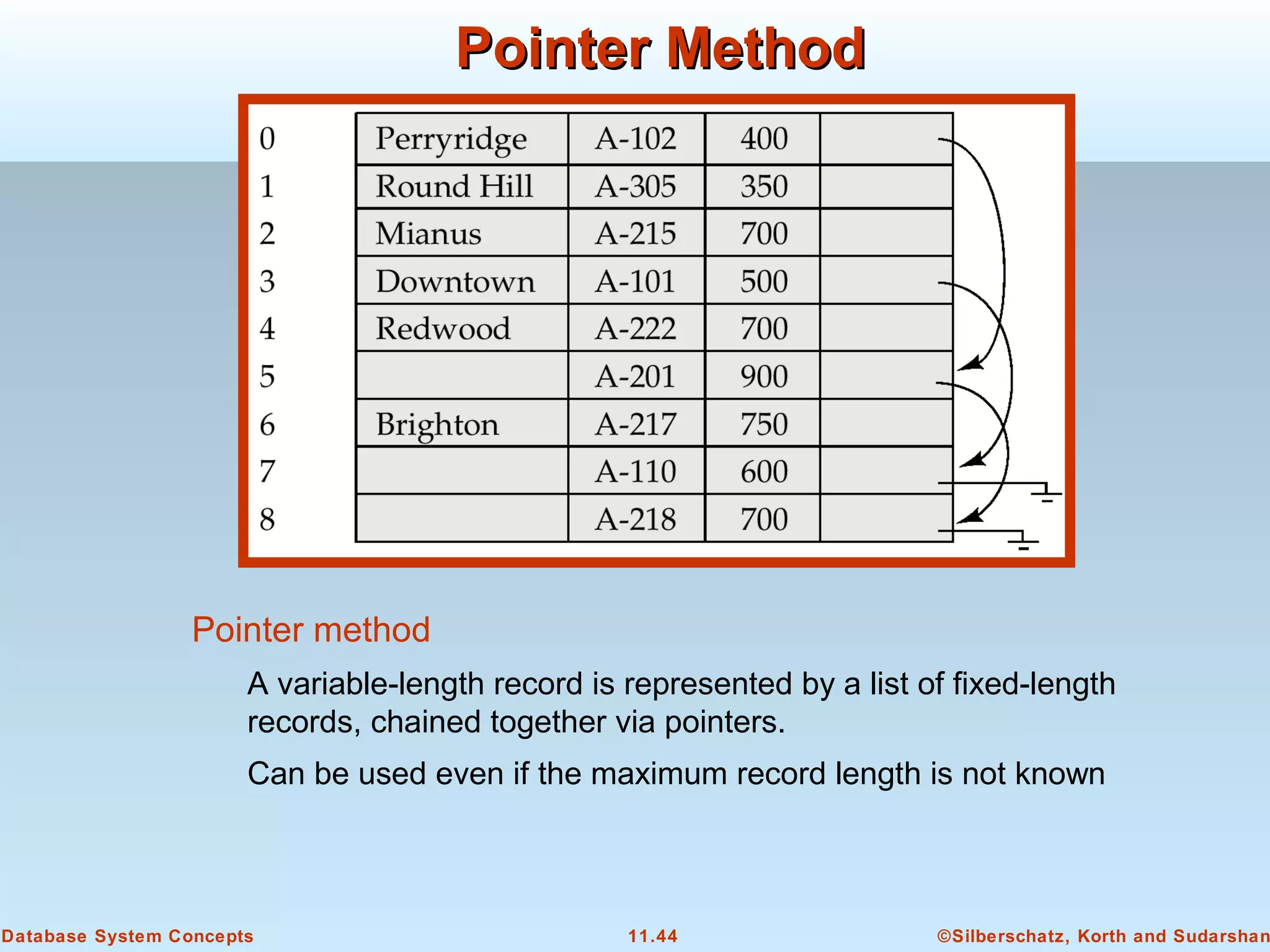
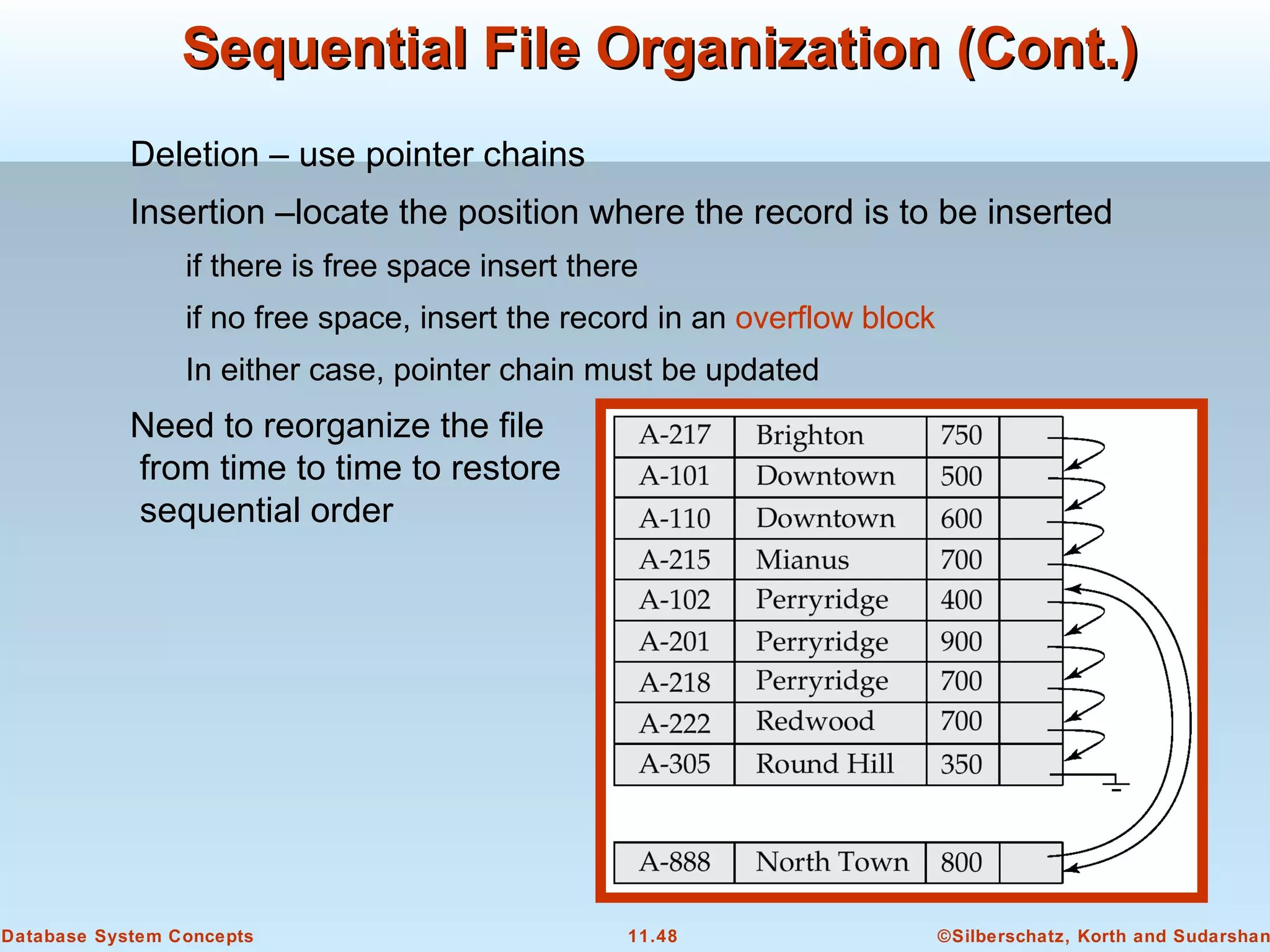
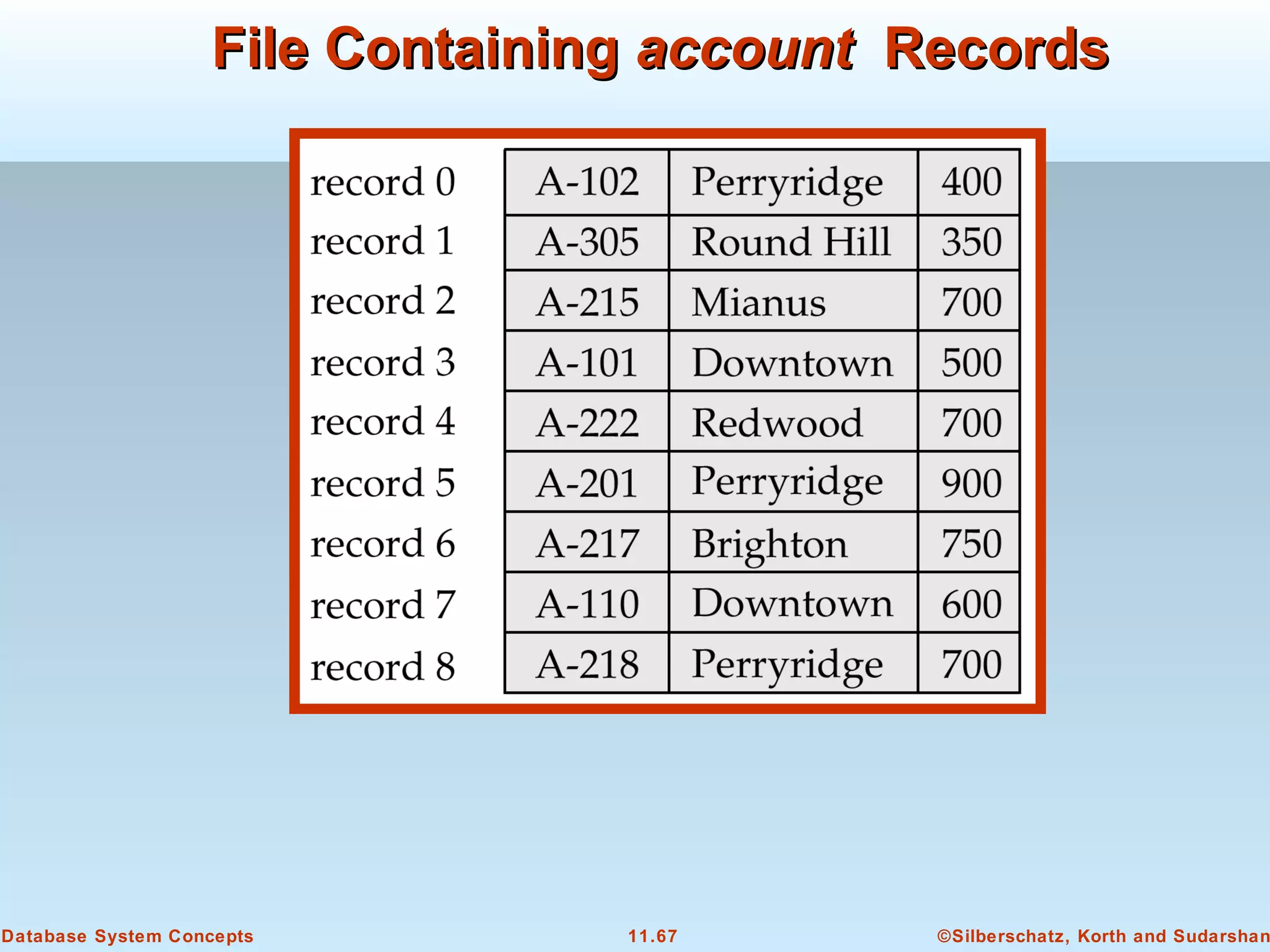
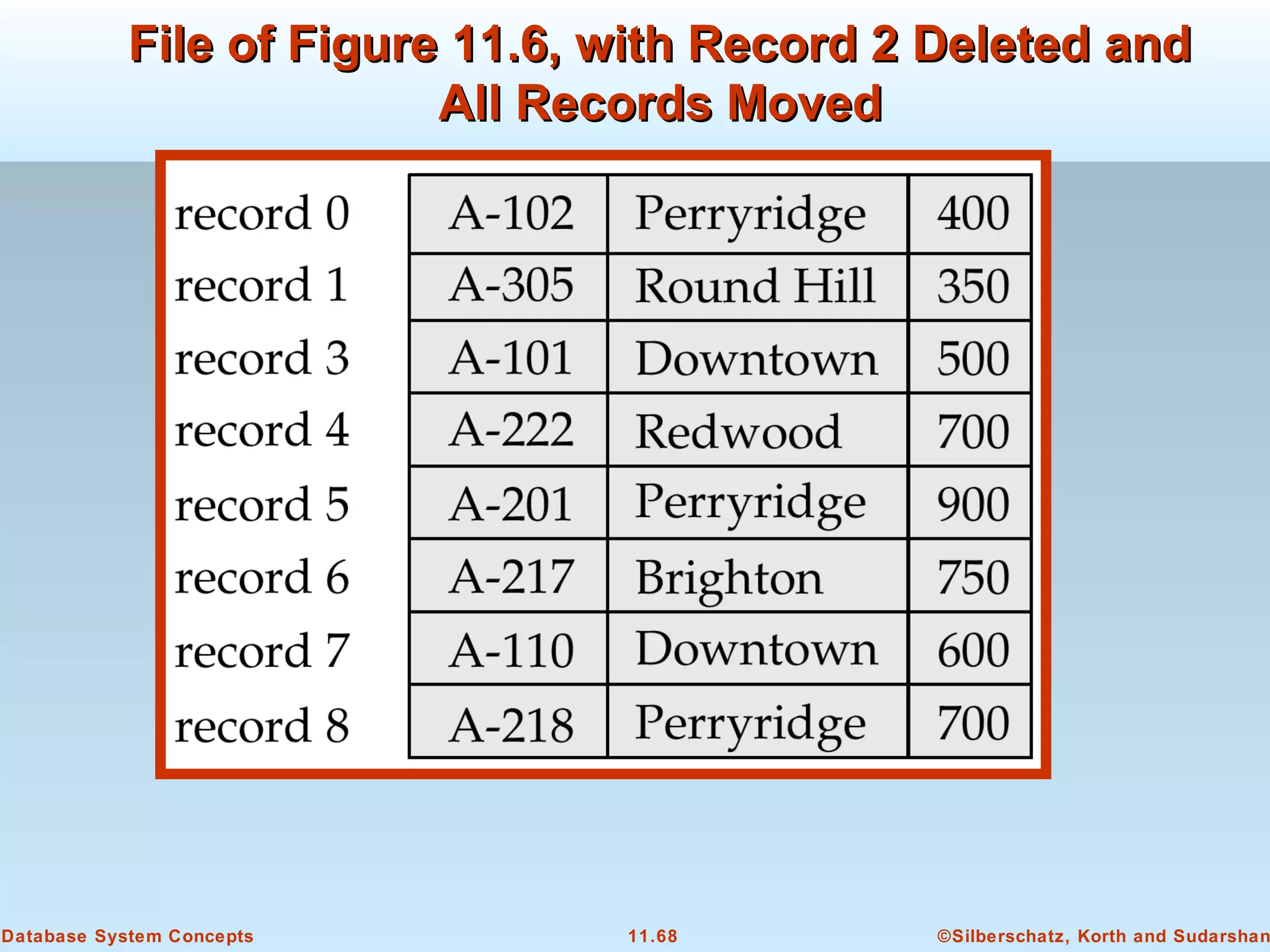
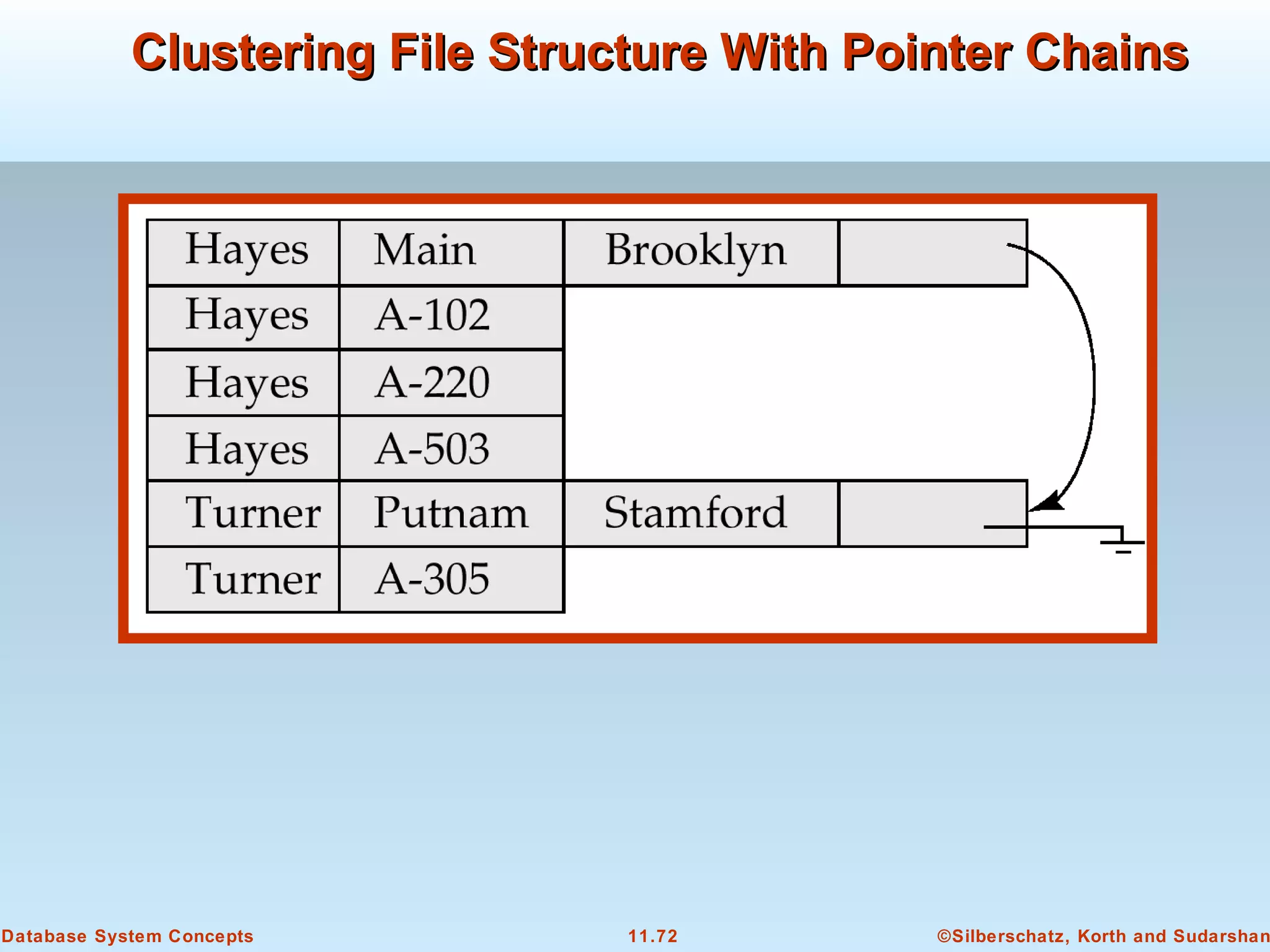
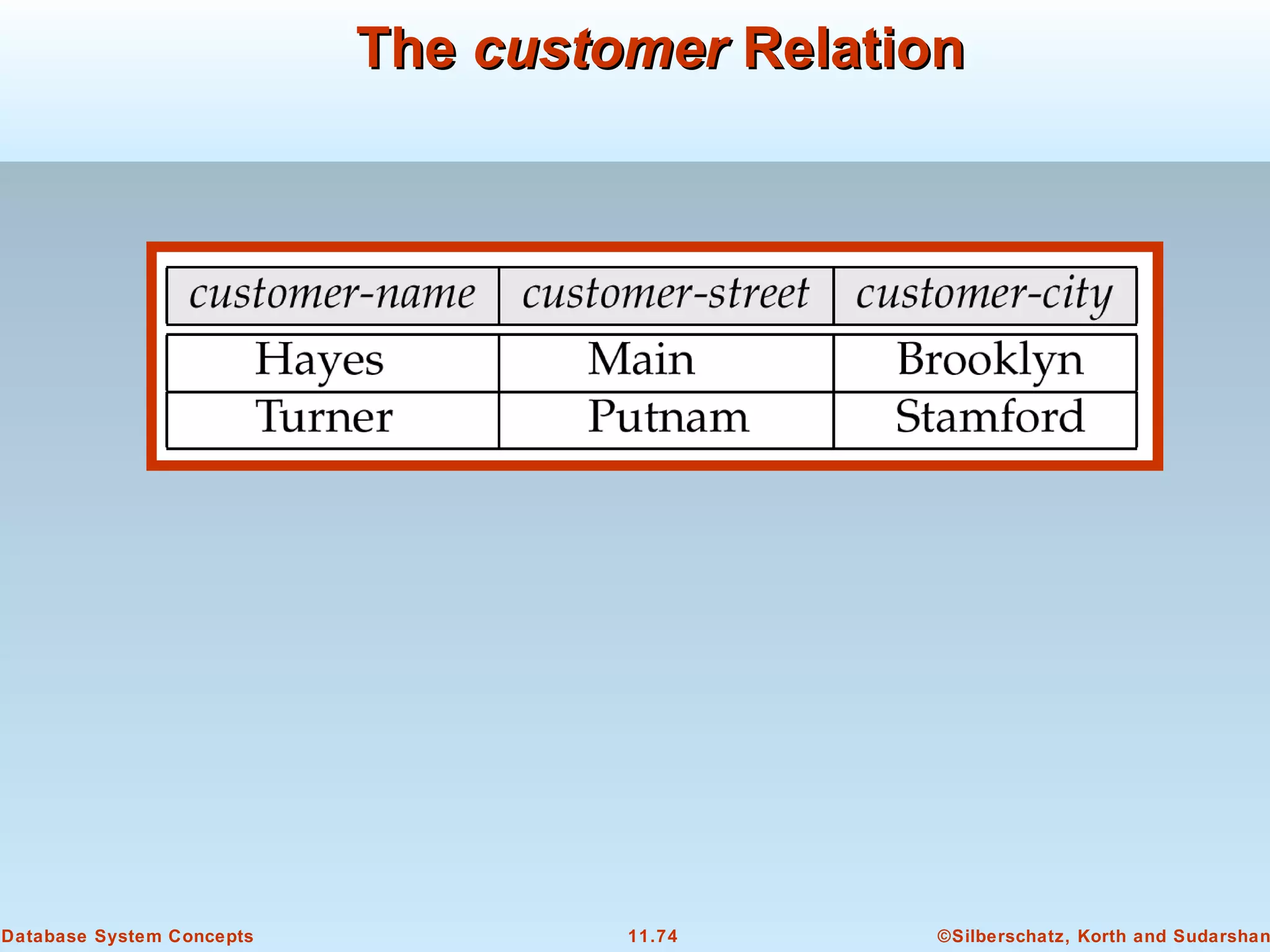
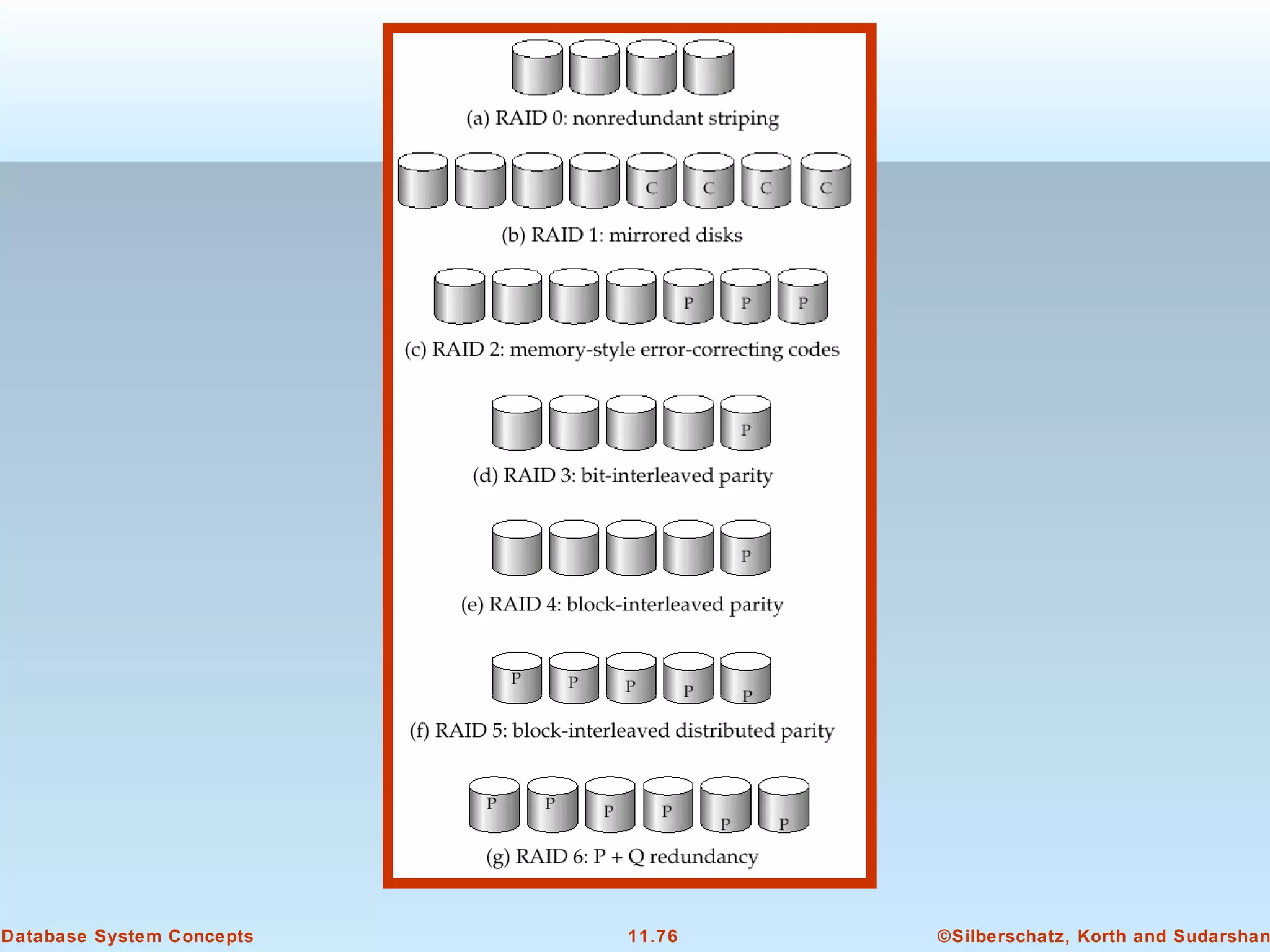
This document discusses physical storage media and file organization in a database system. It describes different types of storage media like magnetic disks, flash memory, and tape storage. It explains the hierarchy of storage from fastest but volatile primary storage to slower but non-volatile secondary and tertiary storage. The document also discusses techniques for improving performance and reliability of disk storage, including RAID (Redundant Arrays of Independent Disks) and how it uses data striping and redundancy across multiple disks to provide improved I/O performance and fault tolerance. It outlines several RAID levels that trade off performance, reliability, and cost in different ways.