Downloaded 149 times


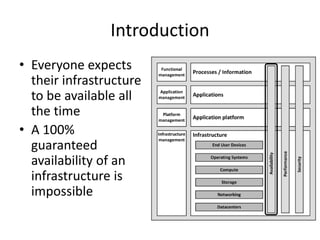

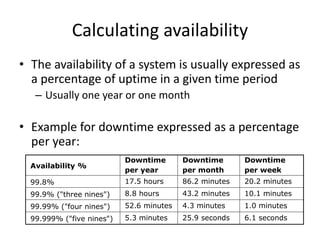

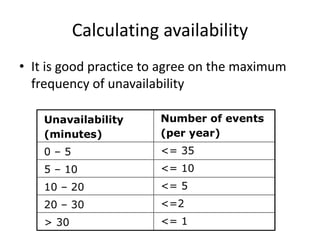
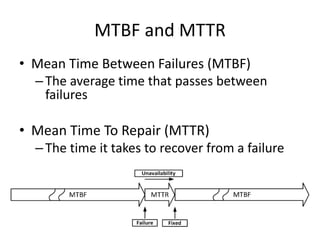
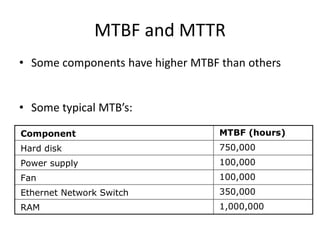


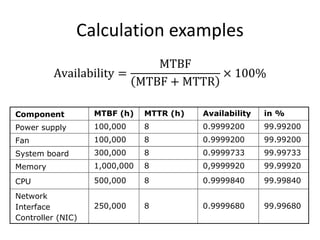
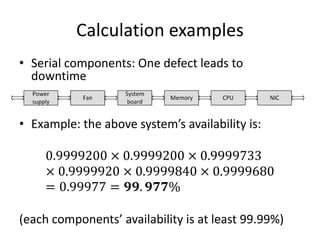





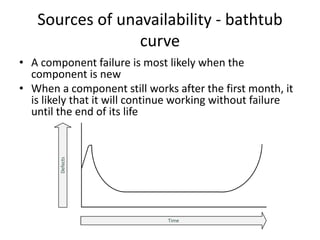











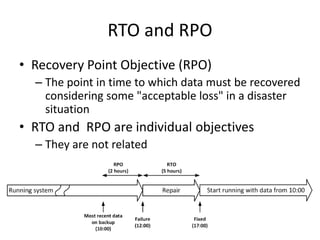

This document discusses availability concepts for IT infrastructure architecture. Some key points include: - Availability is calculated based on uptime percentage over time (usually annually or monthly), with 99.9% being a common service level agreement target. - Downtime is influenced by factors like mean time between failures (MTBF) and mean time to repair (MTTR). Redundancy and failover help improve availability. - Sources of downtime include human errors, software bugs, planned maintenance, hardware failures, environmental issues, and infrastructure complexity. Redundancy, failover, and fallback solutions can help address some causes of downtime.


















































































