Download as PDF, PPTX










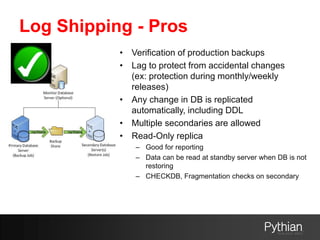




























The document details disaster recovery (DR) and high availability (HA) strategies for SQL Server, emphasizing solutions that can be on-premises, in Azure, or hybrid. It discusses various methods such as log shipping, mirroring, replication, clustering, and Azure-specific options, their pros and cons, along with considerations for architecture design. The presentation aims to help users choose appropriate solutions based on their specific database environment and recovery requirements.























































































