Downloaded 88 times




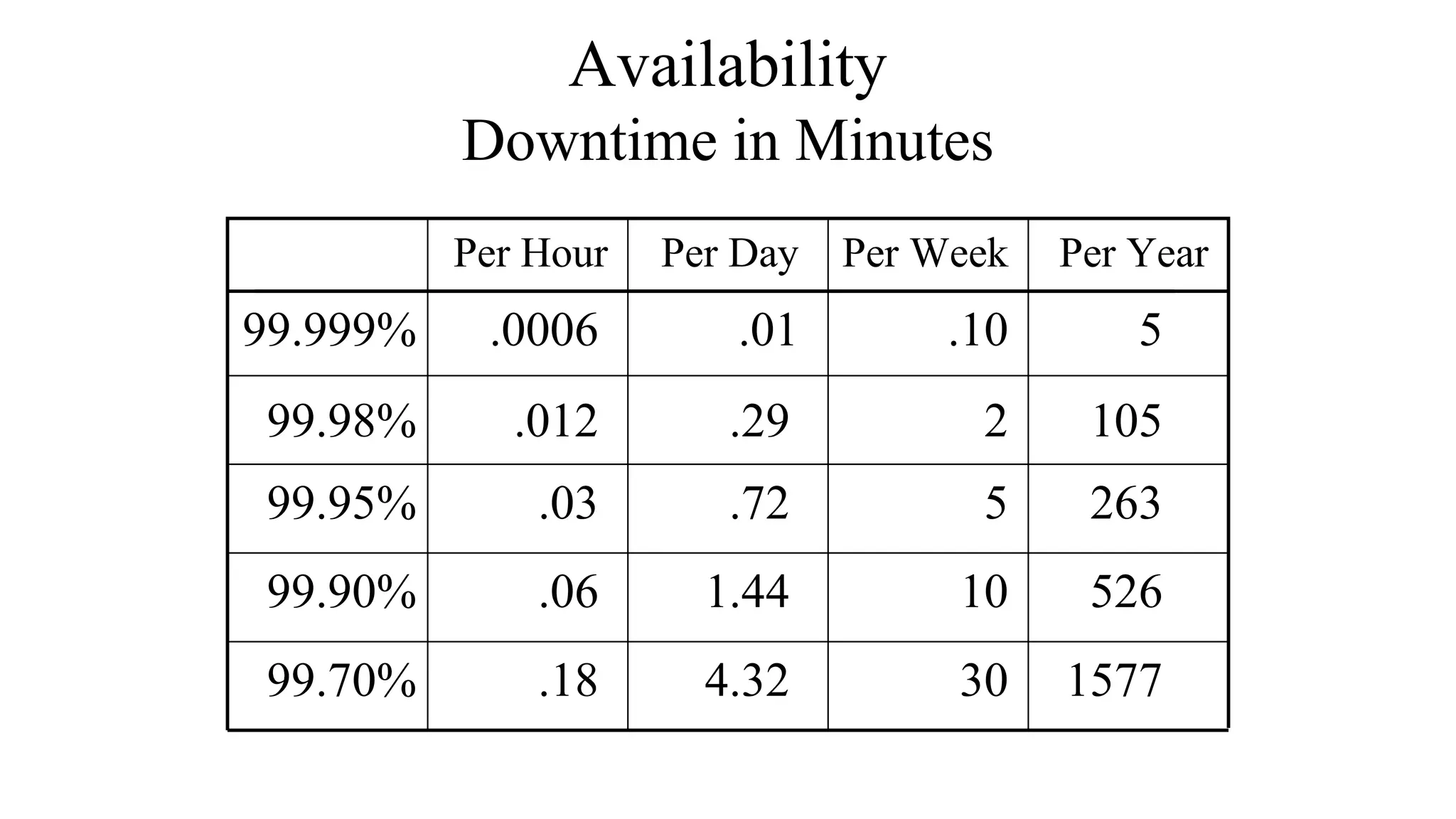
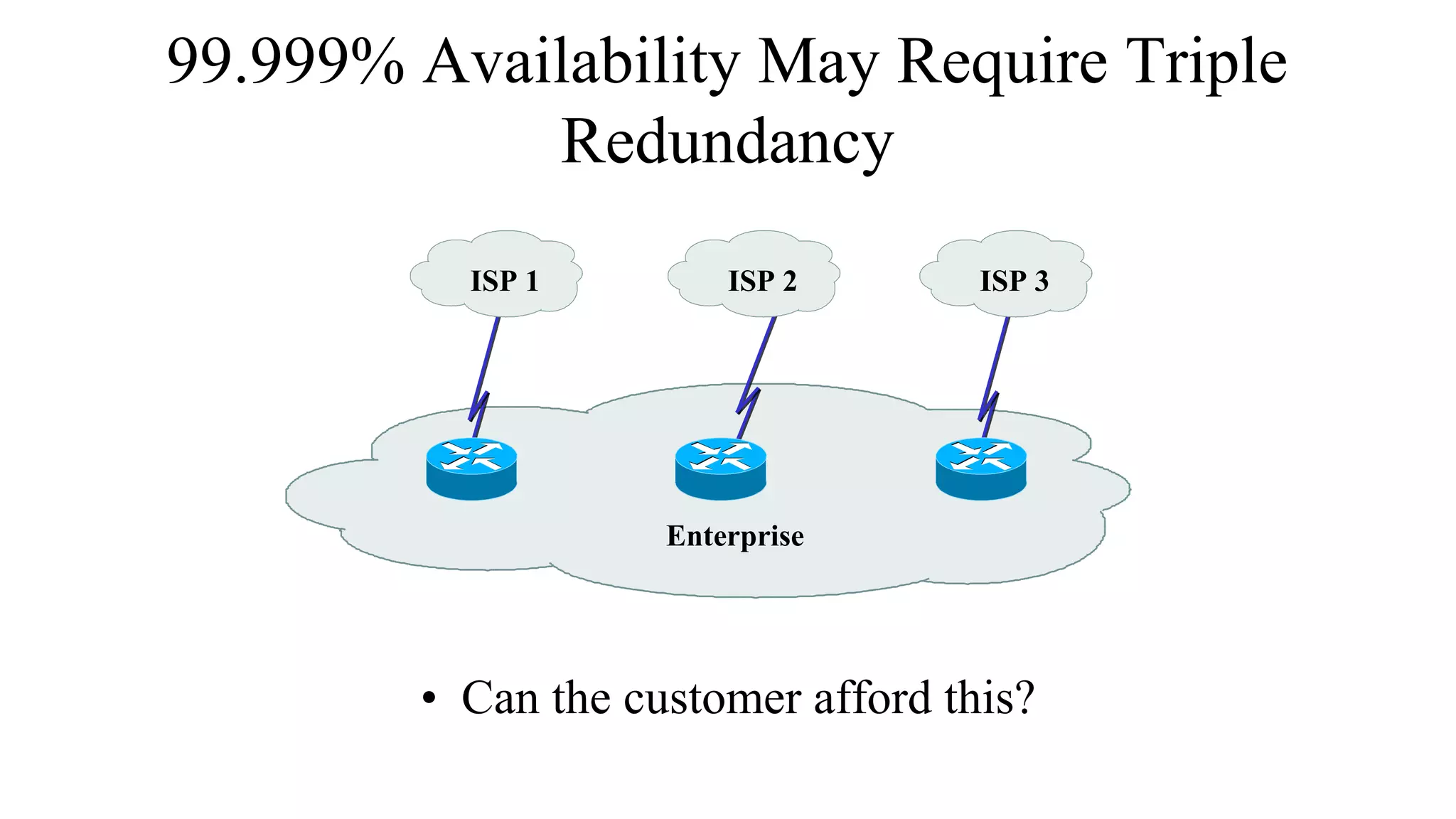







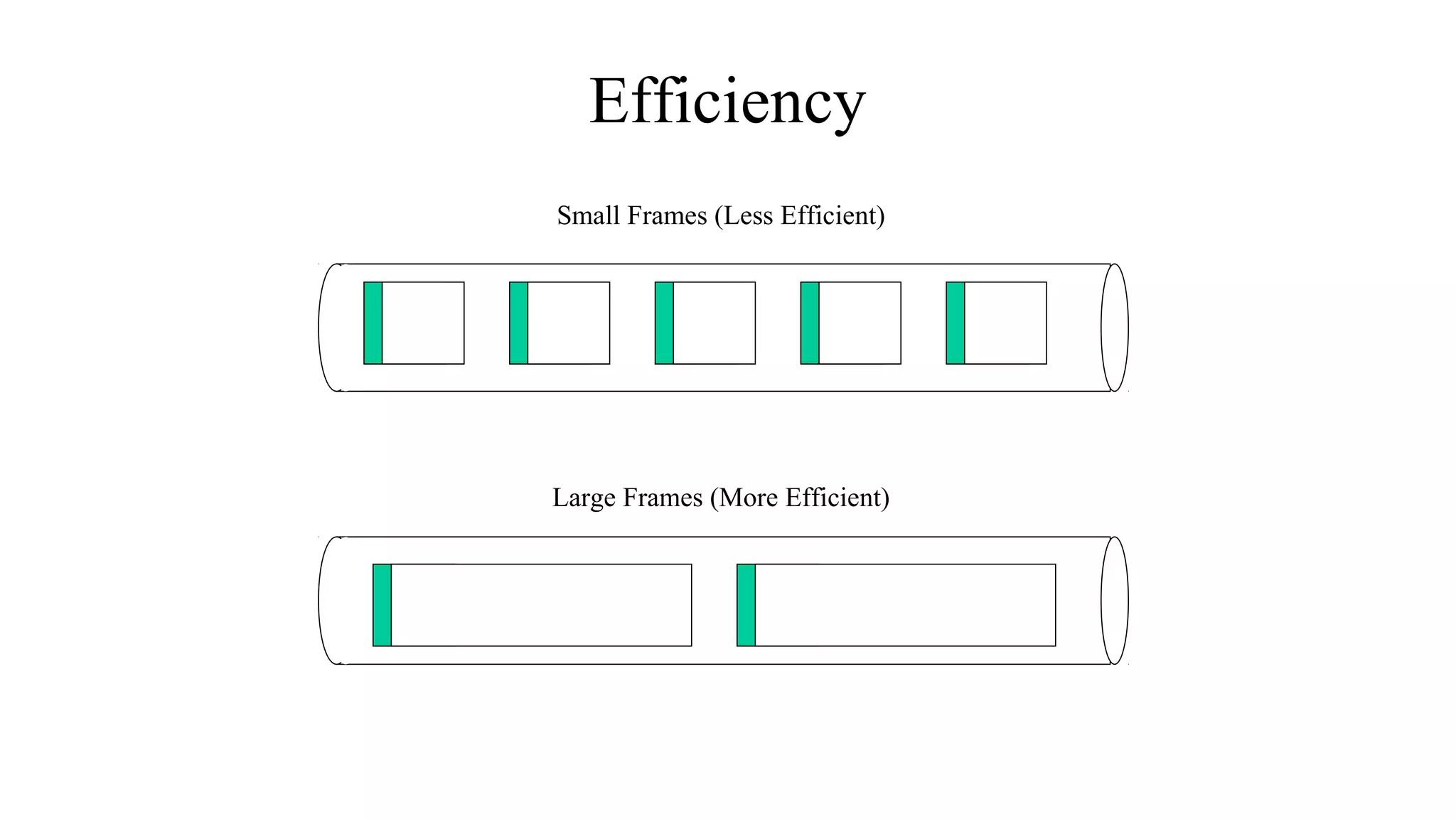













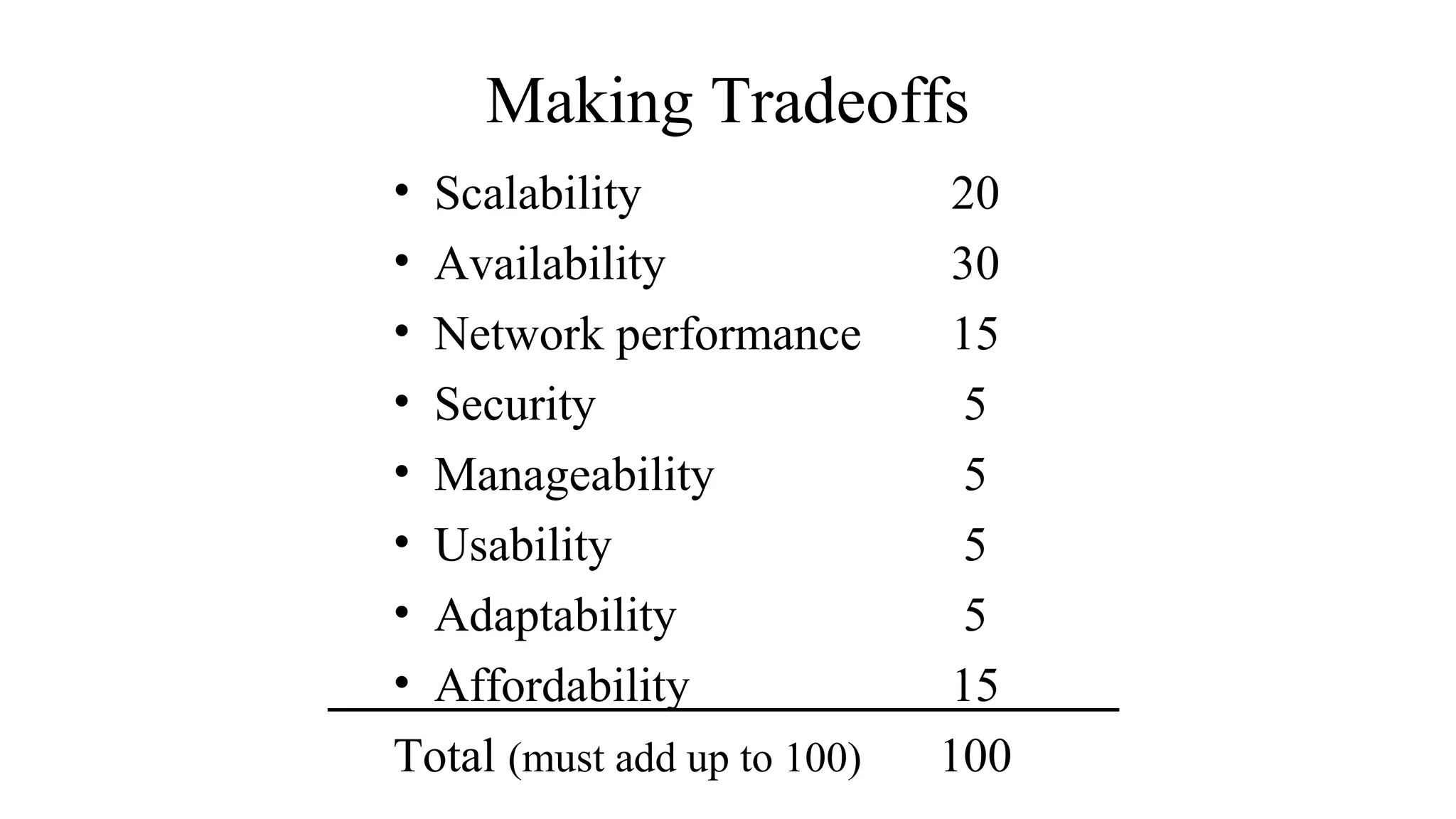



This document discusses key technical goals for network design including scalability, availability, performance, security, manageability, usability, adaptability and affordability. It defines these goals and discusses important considerations for each one. For example, it explains that availability can be expressed as a percentage of uptime or as MTBF and MTTR metrics. It also emphasizes that tradeoffs between these competing goals are usually necessary for effective design.



















































































