Download as PDF, PPTX


























![Data structure behind databases
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
$ db_set 81 '{"x":"11","places":["London Eye"]}'
$ db_set 42 '{"x":"23","places":["Exploratorium"]}'
$ db_set 42 '{"x":"35","places":["Golden Gate"]}'
$ db_get 42 '{"x":"35","places":["Golden Gate"]}'
$ cat database
81,{"x":"11","place":["London Eye"]}
42,{"x":"23","places":["Exploratorium"]}
42,{“x":"35","places":["Golden Gate"]}
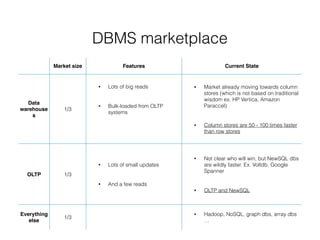
Many dbs use a log, an append-only data file, similar to
what db_set does
But real database has to deal with more issues
• Concurrency control
• Reclaiming disk space
• Log size control
• Handling errors, crash recovery
• Partially written records
• File format
• Deleting records
Append-log is efficient
• Appending and segment merging are faster
• Concurrency and crash recovery are much simpler if
segment file are append-only or immutable
• Merging old segments avoids fragmentation problem](https://image.slidesharecdn.com/data-intensive-apps-171212065847/85/Building-data-intensive-applications-30-320.jpg)





















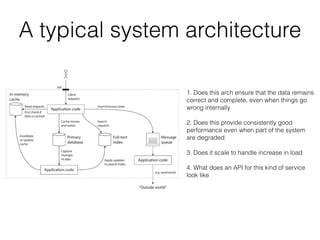
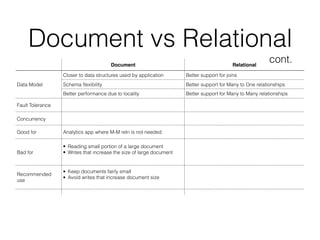
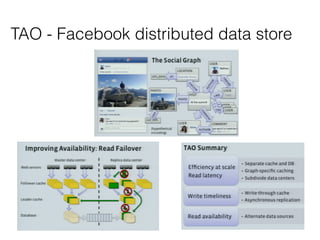
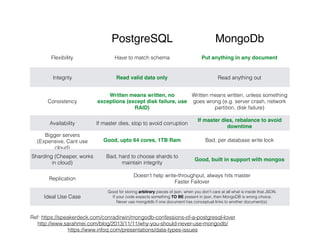
This document discusses data intensive applications and some of the challenges, tools, and best practices related to them. The key challenges with data intensive applications include large quantities of data, complex data structures, and rapidly changing data. Common tools mentioned include NoSQL databases, message queues, caches, search indexes, and batch/stream processing frameworks. The document also discusses concepts like distributed systems architectures, outage case studies, and strategies for improving reliability, scalability, and maintainability in data systems. Engineers working in this field need an accurate understanding of various tools and how to apply the right tools for different use cases while avoiding common pitfalls.



































![Resilience: the key requirement of a [big] [data] architecture - StampedeCon...](https://cdn.slidesharecdn.com/ss_thumbnails/resiliencethekeyrequirementofabigdataarchitecture-stampedecon2015-150717135240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)































