Download as PDF, PPTX



![A couple of headlines… [all November ’14]
3](https://image.slidesharecdn.com/22-01-15dlmeetup-150122111042-conversion-gate01/85/Deep-Learning-an-interactive-introduction-for-NLP-ers-3-320.jpg)

























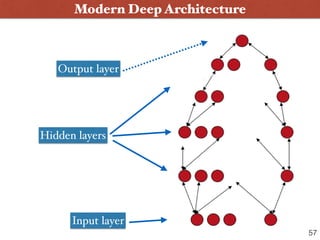

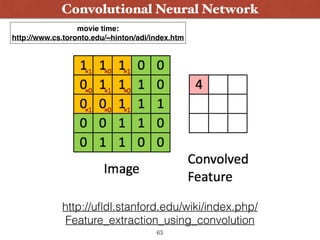
![2. Convolutional Neural Network
62
from: Krizhevsky, Sutskever, Hinton. (2012). ImageNet Classification with Deep Convolutional Neural Networks
[breakthrough in object recognition, Imagenet 2012]](https://image.slidesharecdn.com/22-01-15dlmeetup-150122111042-conversion-gate01/85/Deep-Learning-an-interactive-introduction-for-NLP-ers-62-320.jpg)





![as PhD candidate KTH/CSC:
“Always interested in discussing
Machine Learning, Deep
Architectures, Graphs, and
Language Technology”
In touch!
roelof@kth.se
www.csc.kth.se/~roelof/
Internship / EntrepeneurshipAcademic/Research
as CIO/CTO Feeda:
“Always looking for additions to our
brand new R&D team”
[Internships upcoming on
KTH exjobb website…]
roelof@feeda.com
www.feeda.com
Feeda
69](https://image.slidesharecdn.com/22-01-15dlmeetup-150122111042-conversion-gate01/85/Deep-Learning-an-interactive-introduction-for-NLP-ers-69-320.jpg)





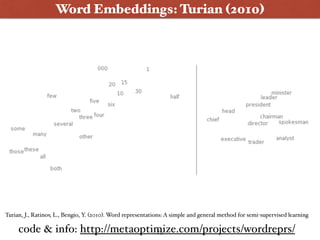
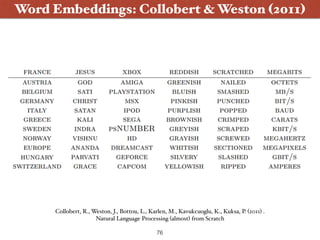



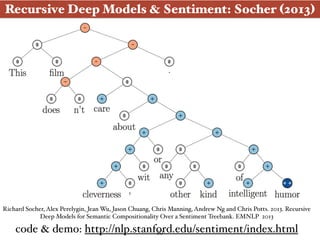


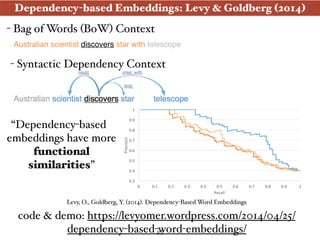

The document presents an introduction to deep learning specifically for natural language processing (NLP), highlighting its relationship to machine learning and its applications in various NLP tasks. It covers key concepts such as supervised and unsupervised learning, the evolution of neural networks, and significant breakthroughs in 2006 that enabled deep learning to flourish. The presentation also discusses future challenges and developments in deep learning methodologies and their implications for the field.























































































