The document provides a comprehensive overview of deep learning, including its background, technical foundations, and practical applications across various industries. Key concepts such as artificial neural networks, machine learning tasks, and the significance of deep learning in areas like speech recognition and medical technology are explored. The document also discusses the evolution of deep learning algorithms and frameworks essential for implementation.
















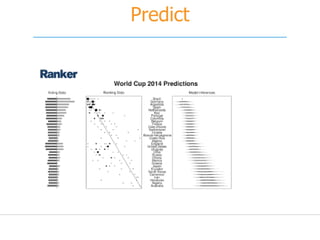
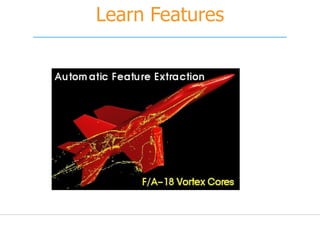





![What is Machine Learning?
Arthur Samuel defined machine learning as a
Field of study that gives computers the ability to learn without being
explicitly programmed".
Machine learning explores the study and construction
of algorithms that can learn from and make predictions on data.[3] Such
algorithms operate by building a model from example inputs in order
to make data-driven predictions or decisions,[4]:2 rather than following
strictly static program instructions.](https://image.slidesharecdn.com/practicaldeepllearningv1-160501081318/85/Practical-deepllearningv1-37-320.jpg)










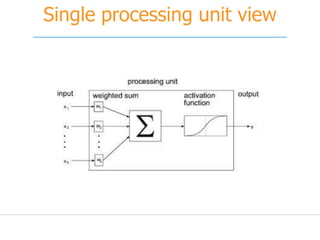

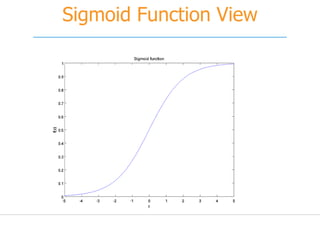
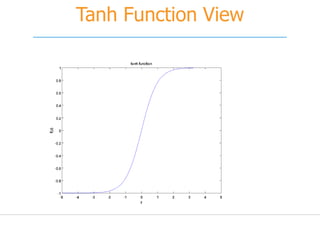










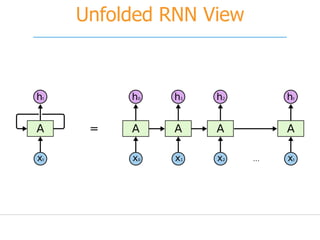
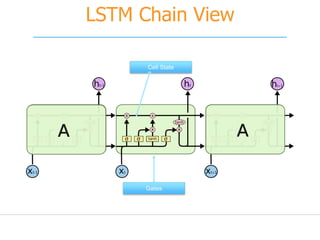
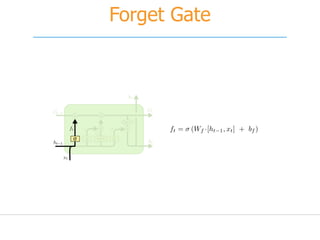
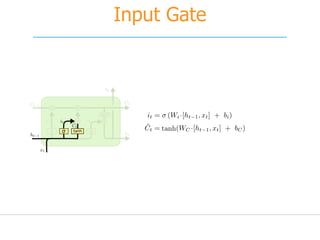
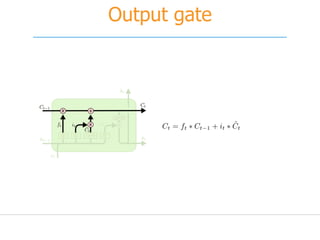






































![[251] implementing deep learning using cu dnn](https://cdn.slidesharecdn.com/ss_thumbnails/215implementingdeeplearningusingcudnn-150915052020-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[252] 증분 처리 플랫폼 cana 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/225cana-150915052201-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)







































