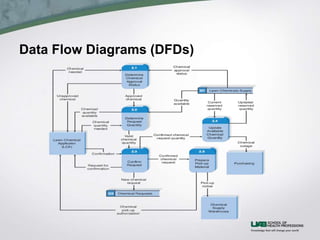
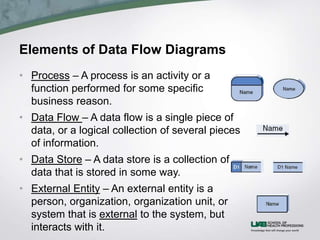
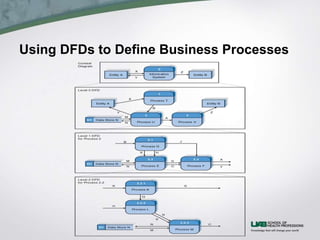
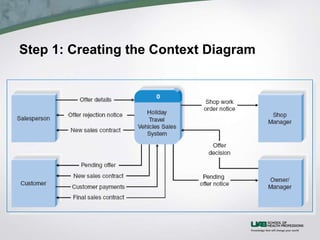
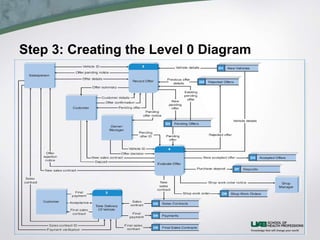
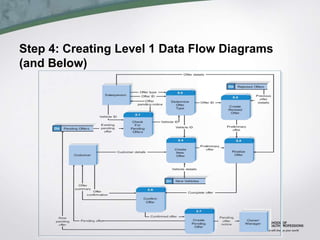
This document discusses process modeling and data flow diagrams (DFDs). It describes the key elements of DFDs including processes, data flows, data stores, and external entities. It outlines the steps for creating DFDs, which include building a context diagram, creating DFD fragments for each use case, organizing them into a level 0 diagram, developing level 1 DFDs based on use case steps, and validating the DFDs. Common syntax errors like violating the law of conservation of data are also discussed.